The Ethics of Modern Communication
A BlogBook is a series of posts intended to be weaved into a single book-length essay.
I wrote this book around the year 2000 and 2001, to cover the ever-mutating field of the Internet in terms of the ethics of such communication, particularly as it focuses on copyright and related issues.
While the writing style could use some improvement, I find that I still largely stand by everything I wrote 20 years ago. The biggest change that I would include is something to address the increasingy hostility of the internet environment. While this essay works tends to point in the direction of ad blocking and similar technologies not being very ethical on theoretical grounds, in practice I think they’re almost a necessity for security reasons nowadays.
But otherwise, I think this largely holds up. Despite the superficial frantic changes in the Internet world, this all still makes sense.
In 2022, a new challenger is arising in the form of AIs that can consume the entire Internet (more or less) and then be used to produce “novel” content. Especially in the image AI space, this is getting a lot of people wondering about the copyright status of the output of such systems. As I write this on the tail end of 2022, I think people are finding themselves working around to the same conclusions I came to 20 years ago; if you slurp up that much content just to feed your AI you must be considered to be deriving from all those sources. An emerging story to be sure.
Communication Ethics book part for Prelude. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I've been particularly interested in how the Internet is affecting law and society for several years now. I've seen a lot of debating, litigating, and legislating, but there is little or no consistency in the rhetoric.
In the past, we've had legal frameworks that allowed us to approach these issues with some degree of consistency. Copyright was built on an ethical framework built on certain simple ethical principles: A creator should be given the opportunity to benefit from his work. A creator deserves credit for his work. The market should be grown. A created work must eventually be released back to society, as the goodness of public ownership exceeds the goodness of continued private ownership for the society. These and other simple principles are the foundation of copyright law, even if we have not followed them perfectly.
But communication has changed radically since the precepts in the previous paragraph were first propounded. In all the debating, litigating, and legislating, virtually nobody has examined the ethical foundation of modern communications. Is it any wonder that the resulting legislation and court decisions have been largely garbage?
This essay exists to correct that major oversight. Indeed, the situation has changed, and due to the complicated nature of modern communication technologies, attempting to create an ethical foundation is decidedly non-trivial. This is not to say that the foundations we built the current legal system on have somehow become irrelevant, but how the principles play out in real life is no longer obvious. Rather than starting with a desired conclusion and making sure I end up with them, I examine the situation afresh, hopefully shedding light in corners you didn't even realize existed. In many cases I myself was surprised by the results, particularly by the Death of Expression chapter, when something I thought would be easily salvagable turned out to be a complete loss. The final goal of this essay is to try to construct such an ethical foundation, and from it derive some sort of useful framework for thinking about the ethical problems, leaving the final construction of the legal framework to Congress and the courts.
I do not respect a person, group, or ideology that defines itself solely in opposition to something. Opposition should flow from positive opinion about what should be that happens to contradict somebody else's ideas. To respect my own opinions about communication issues, I feel it is necessary to thus propose a system that describes how we should be doing things, because it's simply too easy to take potshots at an existing system when you have no responsibility to replace it. It is also too easy to paint one's self into a corner when one is simply being critical of things; without a coherent vision, it's easy to end up accidentally contradicting one's self, which I believe has happened many times, even by groups like the EFF.
I run a weblog called iRi, which is descended from a weblog tracking these issues and trying to synthesize all the various stuff that's happened over the last few years into some sort of positive, cohesive whole. It became clear to me quickly that the weblog format was insufficient for the task. There is so much to cover that it simply cannot be done in small chunks, because there is so much context I need to lay down. So instead of trying to lay this out in a long series of weblog posts, I started writing this essay. As you'll see, each chapter builds on the last and there's a high degree of cohesion in this essay; trying to post it in little chunks would never have worked. Now that this essay has been written, I have stopped posting so much stuff about these topics as I feel it is redundant to what I have written here.
I do not ask you to swallow my views unchallenged. Indeed, I encourage dissension; the odds of this essay being perfectly correct are small. But I hope this will stimulate you to think about these issues in new and hopefully profitable ways. There are ideas in here that I have not seen anyone talk about, even in the years of debate I've been watching, and even in the years it has taken me to write this essay, and the years it has been sitting here largely completed. Even a year after the first publish date I think it is still ahead of its time.
This essay alternatively talks pure ethical theory and about legal concepts, both current and future. The connection is that law is always used in this essay as "applied ethics". In the real world, it is not always the case that laws reflect applied ethics; one need not search too hard for laws that seem to be applied corruption. But we will treat the law in this manner, especially as the ethical "action" of the law is often more revealing then the "words" of theory, and transitions will not be labelled, as that would cause too much bloat.
Who This Is For
This essay was written in the United States, about the United States. All references to "this government" and "the people" refer to the United States Government and United States citizens. Conditions in your country may vary... but as I am talking ethical theory here, the contents of this essay still apply.
Communication Ethics book part for The Conventional View of Communications. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The first question that needs to be answered is, "Is there any need to re-analyze the ethical situation? Can our current legal/ethical framework handle the challenges posed by modern communication technology?"
In this chapter, I'm going to cruise through history and extract an overview of the development of the concepts that the legal system has developed to handle various issues as they arose. We will re-examine the history of content distribution and the history of copyright principles, and draw some connections between them, both traditional and novel. We will examine how we lost track of the ethics of copyright and got stuck in the trap of believing that ad-hoc, expedient solutions were instead immutable wisdom of the ages. In the end it should be clear that the introduction of the Internet and associated technologies constitute a qualitative change in communication technology that will require extensive further refinements
This is a high-level summary, not an enumeration of the thousands of details added over the years. The intention is to lay the groundwork for a demonstration of the deep flaws in the current system. Because the conventional view freely mixes laws and ethics, this chapter will not go to great lengths to separate them either.
I'm going to assume that the readers of this essay are already familiar with both the justifications for intellectual property and free speech, and the basic historical reasons for the creation of each of those, and do not need Yet Another (Probably Oversimplified Anyhow) Explanation of why Gutenberg's printing press more-or-less caused the creation of the concept of copyright. (Again, this is already long enough without rewriting that yet again.) Therefore, since you know the basics of the conventional view of copyright, we can focus on synthesizing a new and better understanding of communication issues, rather then re-iterating conventional understandings.
Communication Ethics book part for Definition of Information. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Information is used loosely in this essay to mean anything that can written on some medium and transmitted somehow to another person. Writing, sculpture, music, anything at all. Information can be communicated, which will be more carefully defined later. Yes, this is broad, but there is a rule of thumb: If it can be digitized, it's information.
Note that digitization is very, very powerful. While few people may own the equipment to do it, there is no theoretical difficulty in digitizing sculpture, scent, motions, or many other things people may not normally consider digitizable. Even things like emotions can be digitized; psychiatrists ask their patients to do so all the time ("Describe how anxious you're feeling right now on a scale of 1 to 10."). While something like a written letter may be fully analog, one can generally create some digital representation that will represent the letter satisfactorily, such as scanning the whole letter and sending the image file.
"Communication" is simply the transfer of information from one entity to another. The details of that transfer matter, and it's worthwhile to examine the history of those details.
Communication Ethics book part for Historical Overview of Information Transmission. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Reduced to a sentence, Gutenberg's printing press's primary effect on information reproduction was to make the production of words relatively cheap. For the first time in history, the effort required to make a copy of a textual work was many times less then the effort required to create the original copy, thus making the production model of "Make an original copy of a book, then print thousands of copies of it quickly for a profit" practical.
Ever since then, technology's primary effect is to lower the cost of various production models with various media until they are practical for an increasing number of people. Every major challenge to intellectual property law has come from this fundamental effect.
Communication Ethics book part for Hand Copying. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
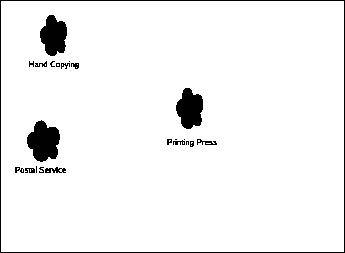
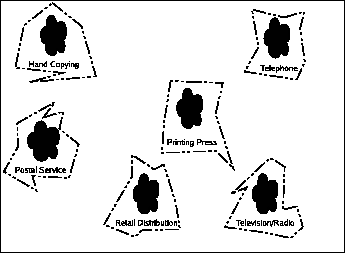
Let's create a graph to look at how various parameters affect the ability to do something profitably, examined over time. (Though not strictly in chronological order as it is often difficult to place a date on when a given technology became truly practical.)
 |
You'll note there's only one black-dot, which is hand-copying material. You'll also note that the graph has no axis labels. This is because there are, in reality, a lot of things that could go on those labels, like cost-per-copy (extremely high), time per copy (a lot), number of customers waiting for product, etc., and there are even more as time goes on, so we're just going to pretend that the graph is two dimensional so we can fit it on the paper. I'll talk about some of the noteworthy parameters as we go through.
At this point, there was no such thing as copyright. Copying was an unmitigated good for a society. Numerous documents have disappeared from history because they weren't copied, now existing only as obscure references by other works which were successfully copied.
Communication Ethics book part for Gutenberg: Books, Magazines, Newspapers. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Gutenberg's invention added another possibility. By lowering cost-per-copy and time-per-copy by orders of magnitude, it became practical to run thousands of copies of a book and sell each of them at a lower price then a single hand copy would cost. A significant time investment was required to set up each run, though, and that became a new constraining factor. With this new ease of replication, the first rumblings of copyright law began, but it was still a very simple domain, so the laws were simple, at least by modern standards.
Another side effect of Gutenberg's invention was the ability to reach an unprecedented number of people with the same message, because of the sheer number of copies that could be cranked out and delivered to people, rather then requiring the users to come to one of the rare copies of the content. This introduces the notion of the scale of communication; throughout history, we have always treated communication reaching many people quite differently from private, 1-to-few communication. Perhaps one of the most important effects was that such technology made it much easier to spread propaganda. Before such easy printing, propaganda required a network of people to verbally communicate it to the targets; printed propaganda, combined with wide-spread literacy, enabled much smaller groups to effectively use propaganda, which has obvious large effects on the fluidity of a society and the intensifying of common discourse.
As the printing press technology improved, people could set up content for the press faster. The lowering of the cost-to-setup enabled the invention of newspapers (and by extensions all periodicals), which are basically cost-effective periodic books. A new practical content distribution solution appeared, and it too affected the law. People wanted to use this new platform for political purposes, but the centralized nature of the printing press made it easy to shut down if a powerful person disliked what the newspaper said. To counter this, our ethical concepts of free speech and the freedom of the press, initially synonymous, were created. In America we even get this guaranteed as part of the first amendment to our constitution; your country may vary. Printing was a major improvement over hand copying, but it is not a perfect information distribution system. The most obvious problem is the need for physical distribution of the printed materials, which was a major part of the cost. The necessities of daily/weekly/monthly distribution to hundreds or thousands of points for periodicals within a subscribing area required a huge infrastructure investment, and non-periodicals needed some infrastructure too, though it wasn't as demanding. There also need to be enough readers (amount of use) to make it economical to print a given newspaper.
 |
You'll note the hand-copying blob is still there. That's because it was every bit as practical to hand-copy things before the printing press as it was after; that almost nobody chose to do it for book-sized communications means that they felt they had a better choice, but the choice was still there. To this day, hand-copying is still the preferred method of communication in many smaller domains, such as jotting down addresses, phone number, and simple notes. Rarely, if ever, does a truly new form of communication completely displace an older one.
Communication Ethics book part for Postal Service. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The postal service is not often considered as an important advance in the context of intellectual property, but in communication terms it is the earliest example of a information distribution service that was capable of reliably sending a single copy of something from one single person to another single person. On a technical level, the modern Internet functions much more like a fifty-million-times-faster postal system then the more-often used metaphor of a the telephone system, so study of the postal system can potentially provide insight into the Internet as well.
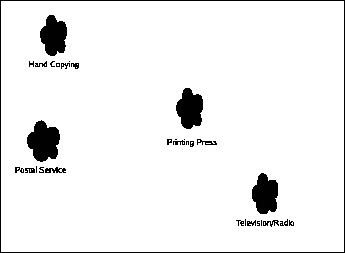
 |
Whether or not this pre-dates Gutenberg's press mostly depends on what you call the first "postal service". Ancient China had a decent one, as did Rome, but the scale and universality of the modern postal services places them in a different league entirely. The forces of technology have given postal services the ability to serve more people and allow them to send more types of things, culminating in that greatest of postal service triumphs, commercially viable junk mail.
That may sound funny, but it's serious, too. It takes an efficient system to make it worthwhile to simply send out a mailing to "Boxholder", and have any hope of it paying off economically.
We often ignore the media in which normal people can communicate with other normal people on small scales, because the large ones that we are about to look at look so much, well, larger that the postal service seems like it's not worth considering. It's an important advance, though, and has empowered a lot of political action, direct sales, even entire industries that might have otherwise never existed. And it has caused the creation of its own fair share of laws and principles. The postal service is primarily interested in the transportation of objects more then "information" per se, but laws have been developed for strictly communication-based crimes, such as using the postal service to send death threats.
The key things a postal service needs is cheap, reliable transportation and customers... lots and lots of customers. It needs to be economical to process each of these point-to-point transmissions, and this means you need to either make up the cost in scale as traditional postal services do, or charge your customers higher prices as courier services do.
Communication Ethics book part for Radio and Television. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Radio and television (which at the level I'm covering them are similar enough to treat as two aspects of the same technology) are entirely different beasts.
 |
With radio and television, content could be broadcast quickly, even immediately ("live"), to any number of people around the country or the world. The customer had to invest in technology capable of receiving these transmissions, but the general public found radio and television more then compelling enough to invest billions of dollars in. Fast forwarding to today, we find that content with broad appeal can be broadcast profitably, news-type content can be broadcast multiple times per day (entire channels can be dedicated to what is essentially the same hour of content, like CNN), increasing the frequency of transmission to "hours" from "days". "Niche" content can also succeed on a smaller scale, though there is still a relatively high break-even point. The schedules of broadcast content started its intricate dance with the American public as each started to schedule their lives around each other.
Radio and television also broke free of the tyranny of the written word. Radio was one of the first technologies that could handle sound directly (the only competition are records and when you consider that a truly viable technology is a judgement call), and television introduced the even more exciting world of video. It was a long time before this truly strained copyright law, as it was not until the 1980's that the mass-market consumer had any easy, practical means of reproduction of video (via the VCR). Concern about the equivalent of recording from a radio did not exist until the 2000's (the ability to record a digital stream directly from a digital radio), because the mass-market consumer did not have the technology to widely reproduce and distribute a recording with any quality. So we can see that one of the pressures on copyright law is the availability of technology that can produce or reproduce content in a given medium.
Radio and television have their own constraining factors too. The expense necessary to put together even the simplest of professional-quality programs is quite high, which introduces the concept of "cost of entry". In theory anybody could start up a television program or network; in practice, it is vastly more difficult then simply having a printing press print 1000 copies of something. Large transmission towers must be constructed, electromagnetic spectrum must be allocated (extremely limited in television before the advent of UHF), and a large staff must be hired to run this station. Thus, only a limited number of large networks could afford to take full advantage of the medium. This has changed with the wide-scale use of cable, and its corresponding ability to transmit low-quality programs without an expensive transmission tower, allowing "public access" channels (probably only due to Federal mandate, though it's hard to know for certain), but the networks still dominate.
The issue of what we now call "monetization" also appeared, brought clearly to mind by the inability to charge for a physical artifact like the printed word. I am aware of three basic viable models: The advertising-based model, the government tax model used in the UK, and a subscription model where an encrypted signal is broadcast and special decoders must be rented (only feasible relatively recently). This also interacts with the economies of scale; you can't make money advertising if only three people are watching your show, whereas forced taxation allows you to target smaller audiences, as long as you can get government funding. An echo of this problem can be seen on the Internet, except the advertising solution isn't working as well.
Of all of the media discussed in this chapter, I think radio and television have been most deeply affected by the way the industries monetize the medium; one need only compare a day's programming from the BBC or PBS to NBC to see the differences.
Communication Ethics book part for Retail Distribution Networks. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
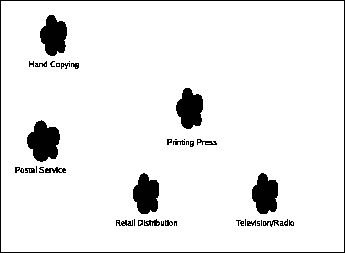
The retail distribution networks have put content into the hands of "the general public". It has become economically viable to distribute content by having the customer come to some retail outlet that orders many copies of various kinds of content and allows the customer to purchase them and take them home. Much like the postal service, this required the invention of reliable transportation and a large enough customer base to sustain the retail outlet.
And much like the postal service, only more so, this has affected the law by affecting everyone, not just some select group of people with convenient access to content in a copyable form. Perhaps more then anything else, the developments implied by the large scale distribution of content in retail stores, put together with the need for consumer technology such as VCRs to use this content, has brought this down to the level where the decisions made regarding these issues will affect everybody in their day-to-day life. What can I do with this CD? Why can't I send my friend a quote from an electronic book?
The existence of a large-scale distribution network for some kind of content, like sound recordings, tends to imply some sort of standard medium for distributing that content. As more people own players for that medium, the technological pressure to create technology to allow the mass-market consumer to also create content on that medium increases. Thus, a few years after the introduction of the CD-ROM, we get mass-market CD writers. DVD writers arrived even more quickly then CD writers did, relative to the initial introduction of the medium. A large-scale retail distribution method by its very existence tends to create market pressure for the creation of technology that will be capable of allowing the user to, among other things, violate copyright laws.
Communication Ethics book part for Telephones. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Telephones are much like the postal service. In general, telephones are hardly different at all from speaking face to face, and in general there is little special treatment required to handle them. But I do mention them because of the nuisance issues that the law has had to deal with with regard to telemarketers, scammers, and other people abusing the medium for personal gain. We will find the principles inherent in the laws laid down for telephones useful in some other similar circumstances later, most notably the issues surrounding "forced" communication, such as e-mail spam.
We can go ahead and roll fax machines into this category too; their biggest impact on the law was also a "forced communication" issue, where junk spams could cost the recipient money for toner and paper. As such it is very similar to normal telephones, when it comes to the legal issues.
Communication Ethics book part for Final Diagram. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
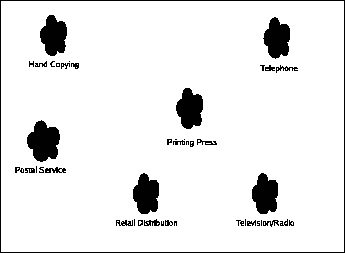 |
Our final diagram (cleaned up for convenience) has a number of isolated splotches, and a large number of candidates for what could be considered to be axes:
- cost per copy
- scale of people reached (one, tens, thousands, millions)
- time to produce per copy
- number of paying customers
- initial setup costs
- transportation demands
- economies of scale
- speed of transmission
- availability of (re)production technology to the mass-market consumer
- cost of entry
- method of monetization
- whether reception is "forced"
There are no connections between these splotches, because there are no "in betweens" which are economically viable. Running a television station does nothing to help you run a postal service, because the postal service has "transportation demands" and "initial setup costs" that the pre-existing television station does nothing to defray. Even the two most structurally similar systems, the phone system and the postal system, are very different beasts, and there's no way to use one to help build the other in any significant way. This is important, because the assumption that each of these domains was independent became an unspoken assumption in the law.
What that means in practical terms is that when a legal pronouncement was made about television ("A given company may only own two television stations in a given market"), it had little or no impact on the other communication technologies.
The separation isn't completely perfect, if you try you can come up with some things that affected multiple types of communication at the same time. But even some of the most basic ethical principles were often defined differently for different media; witness the difference between slander and libel, for instance, virtually identical high-level concepts that differ only in whether they occur in spoken or printed word.
I'd also like to point out that there's a lot more on that diagram then I believe most people are considering since they tend to limit themselves to merely mass media like television and the Internet. By adding in some of the other technologies, we'll find that we can actually find a simpler, more general pattern that applies even after the Internet comes into existence, by focusing not on the technology but on the patterns of communication itself.
Communication Ethics book part for Before Internet - Almost Attained Stasis. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I believe that in the period between around the 1950's (1940's if you are willing to fudge a bit on the retail distribution issue) and the late 1980's, a time period of thirty to forty years, that there were no major technological developments that truly changed the landscape as described above. This is certainly a bit of a judgment call, as things like the Xerox copier appeared However, other then possible changes in the general legal climate, there is no compelling reason these suits could not have been filed decades earlier and won then., but I'd say that those were refinements to existing law, not truly new stuff. Even when tape technology was introduced, both audio and video, the difficulty of copying analog tapes accurately precluded large-scale copyright violations and the consequent pressure on the law, even if it did prompt the now-notorious Boston Strangler comment by Jack Valenti:
I say to you that the VCR is to the American film producer and the American public as the Boston strangler is to the woman home alone." - Jack Valenti, President of the Motion Picture Association of America, Hearings before the subcommittee on Courts, Civil Liberties and the Administration of Justice, 1982. Transcript available at http://cryptome.org/hrcw-hear.htm.
Thus, for forty or fifty years the law had been revised and refined in Congress and with international treaties such as the Berne Convention, and clarified by our court system, until there was hardly any mysteries left about what was legal and what was not. That's long enough for a complete generation or two of lawyers and lawmakers to come and go; this has the unfortunate effect of convincing people that the current system is the only possible system and there will be no major changes necessary. Veneration of the current system has reached a quasi-religious status, where questioning the current system, or even questioning whether we should continue to strengthen the system (question the "meta-system", as it were), gets one labeled a heretic.
So here's the trillion-dollar problem:
 |
Our final diagram has lots of isolated splotches here and there, looking totally independent. Rather then taking the time to truly map the domain of discourse and look at all of the issues in a coherent way, laws and judicial decisions exploited the independence of the media types, and each individual segment got its own laws. The laws were informed by the principles of intellectual property law and certain guarantees of rights, but only "informed by"; deviation was seen as harmless or even good, since it helped match the law to the real world better. Thus, we have created a legal system that in practice consists of a lot of special cases and a very few defining principles.
Despite the inelegance of such a system, it worked, it was well-defined, and while large in size, well understood once you've absorbed all the information on a given topic.
It is truly unfortunate that it did work; it's given us some horrible legal habits.
Communication Ethics book part for After The Internet - Stasis Broken. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The Internet's effects on law can be understood by looking at this figure (with apologies to those who are printing this out to read it):
 |
Here's the "problem": The Internet is extremely powerful technology, and is only getting more powerful. There isn't a single axis of our diagram that hasn't been significantly affected by the Internet. Cost of entry? Believe me, if this was 40 years ago you would not be reading this, because I could never afford to self-publish this physically, and I would simply have never written this. Transportation? It doesn't get any easier then sitting in your own home and accessing the world. Scale? Sometimes people accidentally send email to tens of thousands of people when they intended to only send it to one person; that's how easy large-scale communication is on the Internet.
Remember when I defined information? "Basically, if it can be digitized, it's information"? The Internet is all about the transmission of information. When considered in the context of the rest of the computer revolution, which has digitized everything, from simple words to video to interactive games to, well, everything, the true effect of the ability to transmit information in all of its forms becomes visible: The Internet allows every model to be viable economically, all at once!
Want to create a movie for the enjoyment of you family members (and nobody else) over the Internet? No problem, people do that all the time. Publish music to the entire world? Yep, we can do that too. Write an e-mail to Grandma? Yep. Write an e-mail to every one of the thousands of employees of Intel (Intel vs. Hamidi) almost as easily? Can do.
The Internet in a period of just a few years has taken each of the bubbles that we saw in the previous section and rapidly expanded each of them until they all touch, overlap, and envelop each other. For instance, creating a video for an audience of two is possible because the Internet expands the capabilities of a consumer to have much of the distribution power of a major television network to send someone a video. On the other side, the Internet expands the television studio's viable scales of production, usually limited only to the "ultra-large" scale, to include the ability to make truly economical microcontent available. Similar things have occurred in the radio domain, and entire sites have indeed sprung up in an attempt to make a profit off of this, such as Live365.com, which assists people in creating what are essentially radio stations.
The DMCA (Digital Millennium Copyright Act) is providing another example of this kind of crossover. It is probably safe to say that the DMCA, specifically the anti-circumvention-device clauses, were only intended to protect movies, music, software, and other traditional media. Because it is excessively broad and poorly worded, it has been twisted to prevent people from buying "unauthorized" printer ink refills. On the other hand, through some serious sophistry it has been found not to prevent people from manufacturing compatible garage door openers. To prevent abject absurdity requires extreme effort on the part of the judge, and the result is still far from logically rigorous; instead it smells like an attempt to continue to justify a law even in the face of obvious absurdities.
One could hardly imagine a more thorough way to challenge the traditional communications frameworks. As you recall, the important thing about the diagram I developed in the previous section was that all the sections were isolated, which became an unspoken assumption in the rest of the legal discourse. To put the problem succinctly, the problem with the current legal system is that the foundational assumption that the legal domains are independent is no longer valid, which has invalidated all laws built on that assumption.
We cannot simply patch around this problem, because the system is already a patchwork quilt and you can't continuously patch patches. From day one, laws were made without regard for the other communication domains so contradictions and simple conceptual mismatches between the domains are the rule, not the exception. The very principles upon which the practical system was built have been shown lacking. We must fix the problem at a deeper level.
Communication Ethics book part for Ethical Drift. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This also explains the ethical drift that has occurred over the last sixty to eighty years. While hammering out the earliest versions of copyright law, it was critical to create an ethical framework for thinking about the issues. But once the system is built, it is easy to treat the system as the goal and forget about the original ethical foundation that it was built on. Forgetting the true foundations of the system was made even easier by the fact that there weren't very many true challenges to the system; adding one more domain may look exciting at the time but the excitement is contained within that domain. It is easy to see with only a little study of the origins of intellectual property that the mistaking of means for ends is nearly complete in current intellectual property law and trends. Only a small fringe group discusses the ethical issues any longer in terms of responsibilities and the basic goals of the intellectual property legal machinery; the vast majority of the discourse is in terms of the rights of the owners, and protection of rights, and often even the ensuring of profit, which is far removed from the original reasons given for our current system.
Communication Ethics book part for Legal Attempts To Deal With The Change. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Let's look at the diagram again, but remove the black which represents viable activities.
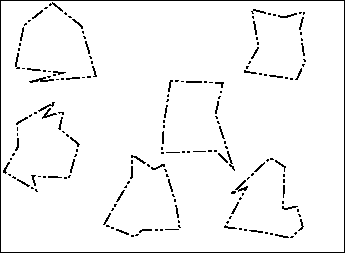 |
You'll note that the law no longer covers the complete domain of activities anymore. This presents some major problems, as people such as MP3.com have found out. As a way of branching out, MP3.com attempted to create a business where they would create high-quality MP3 files of thousands of CDs (at the time, it was technically challenging to create a good MP3 from a CD, as evidenced by the notoriously spotty quality of files downloaded from the original Napster), and when people proved to MP3.com that they owned the CD, MP3.com would give them access to the prepared MP3 files. MP3.com figured this would not be an issue because they made the customer prove that they already possessed a legal copy of the song or album they could obtain. The courts found that MP3.com was distributing music files, which requires a license that MP3.com didn't have. Subsequently, that service has been shut down.
This is a perfect example of what the modus operandi of the legal system has been up to this point: To try to extend all of these little circles outward until they cover all the scenarios that are important at the moment. In this case, the courts decided that distribution of music in this manner was the same as distributing new CDs to the customers. Unfortunately, because each of these sets of laws have been designed with any number of hidden assumptions based on the domain that they were created for, there are unresolvable conflicts everywhere these laws overlap.
For instance, consider "sending digital video over the Internet". In early 2000 in Australia, the part of the government charged with licensing television broadcasters briefly considered trying to require anybody in Australia who wants to transmit streaming video over the Internet to acquire a broadcasters license.
Notice that if one only considers the point of view of those familiar with television, this requirement not only makes perfect sense, it shows a good understanding of how the growth of the Internet could affect television. It is probable that an Internet site in a few more years could broadcast streaming video twenty-four hours a day, seven days a week, at television qualities to television-station sized audiences, effectively gaining all the capabilities of a television station. In only a few more years, this capability will exist for everyone. Obviously, if a country wants to regulate what can appear on television, the country will not want to allow such "stations" to bypass the decency laws of that country just because it isn't a "television station". Thus, it was proposed that the bureau should consider requiring streaming video websites to meet the licensing requirements of a television station. Do not think I am mocking this idea; from the point of view of television regulation, this was an unusually forward-thinking idea, especially for the year 2000.
Fortunately, it was rapidly struck down... because when look at this with anything other then a television-centric viewpoint, it quickly degenerates into absolute absurdity. Does Grandma need a full-fledged broadcasting license just to post streaming video of her grandchildren's birthday party for the father who's on a business trip on the other side of Australia?
And flipping it around, can we completely duck the issue of requiring a broadcasting license by not "streaming" video? In places where two classes of law overlap, like in this example where television law is overlapping with personal law, people will attempt to "dance" from one legal domain to another. So, if the law specifically requires streaming video providers to obtain licenses, a provider may decide to delay the video by an hour, create several files containing an hour of content each, and allow the visitor to view those on the web in a non "streaming" fashion, which violates the spirit of the law, but not the letter. In every way that matters, they are still broadcasting and deriving all the benefits thereof (especially if they also just "happen" to schedule all of their content in advance by an hour so this delay gets cancelled), but they've either ducked the law or forced the creation of unwieldy special-case clauses in law or the policies of some entity like the FCC.
And this is only one small case involving two domains! Imagine all the wonderful conflicts you could create with a bit of creativity, many of which have already occurred, somewhere. I could go on for another twenty or thirty pages proving this point with examples, but that would exhaust us both. If there was only a limited number of these intersections, we could cover them all with special cases as we have in the past, but the combinations and conflicts are nearly limitless, with every year's new technology adding a few more.
Here, you can make your own conflicts. Pick one or two from this list: Video, music, spoken word, deriving works from (such as making custom cuts of movies), text, images, software. Pick one from this list: over the Internet, on demand, traded via peer-to-peer, with some unusual monetization system (such as micropayments). Pick one from this list: to one person, to a select group of persons, to a small number of people in general, to the general public. Odds are very good that unless you deliberately select something that already exists ("Video monetized through advertising to the general public" a.k.a. "Television"), you can find cracks in the law. If you select two from the first list ("Music and spoken word over the Internet to a small number of people in general", which is personal radio station DJ'ing, which is a popular hobby in some subcultures), you're certain to find conflicts. And this isn't even an exhaustive list of possibilities, just what I came up with in a few minutes.
I think it is clear that the current approach cannot succeed. We can not address each problem that arises with a stop-gap solution; each such stop-gap adds two more conflicts to the system. Even if we stuck with it long enough to nail down each problem the hard way, and in this era of multi-year lawsuits that would take a very long time, it would still be messy and inefficient, and would still be subject to radical upheaval by a new technology. We are far better off laying a completely new foundation.
Communication Ethics book part for A Communication Model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
On the one hand, you'd think we all understand what communication is well enough to talk about it meaningfully, since we all do it from a very young age. On the other hand, personal experience shows that people get very easily confused about the communication that occurs in the real world. Most people can't really answer "What happens when you request a web page from a web server?" If you can't even meaningfully answer questions about how things work or what happens, how can you expect to understand the ethics of such actions? And a complementary question, if one must have a post-grad degree in computer science to understand what is going on, how can we expect to hold anybody to whatever ethics may putatively exist?
Since nobody can adequately describe what's going on, the debates almost inevitably degenerate into a flurry of metaphors trying to convince you that whatever they are arguing about is the same as one of the existing domains, and should be treated the same way. The metaphors are all inadequate, though, because as shown earlier, there is a wide variety of activities that do not fit into the old models at all. As a result, the metaphor-based debates also tend to turn into arguments about whether something is more like television or more like a newspaper. There are sufficient differences between things like using a search engine and reading a newspaper to render any metaphor moot, so the answer to the question of which metaphor is appropriate is almost always "Neither."
Before we can meaningfully discuss ethics, we need to establish what we mean by communication, and create a model we can use to understand and discuss various situations with. We'll find that simply the act of clarifying the issues will immediately produce some useful results, before we even try to apply the model to anything, as so frequently happens when fuzzy conceptions are replaced by clear ones. After we're done, we will not have need to resort to metaphors to think and talk about communication ethics; we will deal with the ethical issues directly. As a final bonus, the resultant model is simple enough that anybody can use it without a PhD in computer network topology.
Communication Ethics book part for The Model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
For this model, I take my cue from the Internet and the computer revolution itself, because it is a superset of almost everything else. Telecommunication engineers and other people who deal with the technical aspects of communication have created a very common model of communication that has six components, which are a sender, an encoder, a medium, a decoder, a receiver, and a message, as in figure 10.
 |
The parts of this model are as follows:
- Sender: The sender is what or who is trying to send a message to the receiver.
- Encoder: In the general case, it is not possible to directly insert the message onto the communications medium. For instance, when you speak on the telephone, it is not possible to actually transmit sound (vibrations in matter) across the wire for any distance. In your phone is a microphone, which converts the sound into electrical impulses, which can be transmitted by wires. Those electrical impulses are then manipulated by the electronics in the phone so they match up with what the telephone system expects.
- Message: Since this is a communication engineer's model, the message is the actual encoded message that is transmitted by the medium.
- Medium: The medium is what the message is transmitted on. The phone system, Internet, and many other electronic systems use wires. Television and radio can use electromagnetic radiation. Even bongo drums can be used as a medium (http://eagle.auc.ca/~dreid/overview.html).
- Decoder: The decoder takes the encoded message and converts it to a form the receiver understands, since for example a human user of the phone system does not understand electrical impulses directly.
- Receiver: The receiver is the target of the message.
As a technical model this is fairly powerful and useful for thinking about networks and such. However, since the model is for technical people for technical purposes, it turns out that it's actually excessively complicated for our purposes of modeling communication for the purpose of ethics.
We can collapse the encoder and decoder into the medium, because we never care about the details of the encoder or decoder in particular; it is sufficient for our purposes to consider changes to the encoder or decoder to be essentially the same as changes to the medium.
That leaves us four basic components.
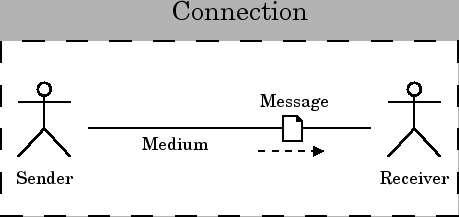 |
The base unit of this model can be called a connection.
- connection
- If there is an identifiable sender, receiver, and medium, they define a connection along which a message can flow. When the sender sends a message, the medium transmits it, and the receiver receive the message.
Note that until the message is sent and recieved the medium may not literally exist; for instance, your phone right now theoretically connects to every other phone on the public network in the world. However, until you dial a number or recieve a call, none of the connections are "real".
A connection is always unidirectional in this model. If communication flows in both directions, that should be represented as two connections, one for each direction.
To send a message across the connection, a connection is initiated by a sender, and the receiver must desire to receive it, excepting sound-based messages which due to a weakness in our physical design can be forced upon a reciever. Either can occur independently; a receiver may be willing to receive a message, but the sender may not send it until they are compensated to their satisfaction. A sender may wish to send a message, but no receiver may be interested in receiving it.
For a given message from a sender to receiver, the "medium" is the everything the message traverses, no matter what that is. If the phone system offloads to an Internet connection to transmit the message part of the way, and the Internet connection is then converted back to voice on the other end, the entire voice path is the medium. It may sometimes be useful to determine exactly where something occurred, but except for determining who is "to blame" for something, all that really matters are the characteristics of the medium as a whole.
Communication Ethics book part for Example. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Let me show you an example of this model applied to one of the most common Internet operations, a search engine query. Let's call the search engine S (for Search engine) and the person querying the engine P (for person). Let's assume P is already on the search engine's home page and is about to push "submit search".
- P (as sender) opens a connection to S (as receiver) via the Internet (the medium). P sends the search request (the message).
- S, which exists for the sole purpose of searching the Internet in response to such requests, accepts the connection, receives the request and begins processing it. In the past, the search engine has read a lot of web pages. It puts together the results and creates a new connection to P, who is now the receiver, using the Internet. It sends back the results.
Technical people will note at this point that the same "network connection" is used, as TCP is both send and receive, so no new "network connection" is ever created. This is true on a technical level, but from this model's point of view, there is a new "connection"; what constitutes a "connection" does not always match the obvious technical behaviors.
On most search engine pages with most browsers, you'll also repeat this step for each graphic on the results page, loading a graphic that's on the page. In this case, the person P is the sender for the first connection, the company running the search engine S is the receiver for the first connection, and the medium is everything in between, starting at P's computer and going all the way to the search engine itself.
This model does not just apply to the Internet and computer-based communication. It applies to all communication. When you buy a newspaper, the newspaper is the medium, and the sender is the publisher. When you watch television, the television is the medium, and the television program station is the sender. When you talk to somebody, the air is the medium and the speech is the message. This is a very general and powerful model for thinking about all forms of communication.
Communication Ethics book part for Chain of Responsibility. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
There are many elaborations on this basic model:
- an entity between the sender and receiver catches the message and does something with it. The entity could cache it so future requests are faster, log that a communication occurred, change the message, completely block the message, or any number of other things.
- the communication medium itself may affect or manipulate the message somehow, either according to someone's intent or by accident (transmission flaw), especially as "the medium" can include computers and other such things.
There are any number of ways to expand on those basic elaborations of intercepting the message or manipulating the medium. An exhaustive list of such things would take a long time, but fortunately there is a relatively straightforward way of characterizing all of them. Each possible elaboration consists of some other entity inserting themselves into the connection somehow and manipulating the message between receiver and sender. For every communication made, we can catalog these entities and form a chain of responsibility.
- chain of responsibility
- The listing of all entities responsible for manipulating a message in some form other then pure delivery.
Consider a newspaper story containing a quote from some source and some commentary by a reporter. By giving the quote to the reporter acting on behalf of the newspaper, the source is trying to communicate with the readers of the newspaper story. In the communication from the source to the reader, the newspaper intervenes, probably edits the quote, and adds the rest of the article around it. In this case, the newspaper is on the chain of responsibility for this communication. This matches our intuition, namely that the newspaper could potentially distort or destroy the message as it pleases, and it has responsibilities that we commonly refer to as "journalistic ethics", which among other things means that newspaper shouldn't distort the message.
Being "responsible" for a message means that you are able to affect the message somehow, and are thereby at least partially responsible for the final outcome of the communication. As I write this, millions of conversations are occurring on a telephone. I am not on the chain of responsibility for any of those communications because I have no (practical) ability to affect any of those communications. On the other hand, if someone calls my house and leaves a message with me for my wife, I can affect whether that message is transmitted accurately, or indeed at all. Alas, too frequently I forget to deliver it. Thus, I am on the chain of responsibility for that message, since I have demonstrated the capability of destroying the message before it got to the recipient.
Anybody who can affect the message is therefore on the chain of responsibility even if they have no technical presence on the medium. The biggest, and perhaps only, example of this is a government, which may choose to set rules about all messages that affect all message and thereby have a degree of responsibility for all messages. For instance, the government makes rules about "libel" and "slander", and the government has the ultimate responsibility of enforcing them. Since a government is capable of censoring a message, they are technically on every message's chain of responsibility as a result, though the impact is so diffuse that usually as a practical matter it's not worth worrying about.
The chain of responsibility should consist only of people, corporations in their capacity as people, and "governments" considered as people. Any time it seems like a machine or process is on the chain of responsibility, it is really the person responsible for that machine or process who is on the chain. The reason for this is that a machine or device can not be "responsible" in the ethical sense for anything, since they are not people. Sometimes it is not obvious who that person is, and once again it can be a judgement call exactly who is responsible.
For example, consider a browser cache, which stores content from web servers on behalf of the browser user, so they don't need to reload it every time they wish to view it. Clearly "the browser cache" is on the chain of responsibility of a standard web page retrieval communication, because if it works incorrectly or has stale content, it can prevent the user from receiving the correct message. But since "the browser cache" is (part of) a program, and programs aren't allowed on the chain, who is responsible for the browser cache? The obvious answer is the browser manufacturer, but as long as the cache is implemented correctly, that is not necessarily the right answer. Consider a lawsuit against someone who took content from a web browser's cache and then illegally distributed it. Can the browser maker be said to be involved with this? One could make a case for it... perhaps the cache manufacturer should have encrypted the cached content better so the user couldn't just take it out of the cache. On the other hand, that's not necessarily a very convincing argument because clearly the person who is illegally distributing the content is responsible, and the fact that they got it from the cache merely incidental, as they could have just as easily gotten it directly from the website.
Presence on the chain is not a binary off/on thing, because there are different levels of responsibility. Sometimes it's not possible to strictly determine whether an entity is "on" or "off" the chain. As usual in the real world, there are grays, and thus there is room for legitimate disagreement about how responsible a given entity is in some situations. The most useful question to ask is "How much influence can the person have on the message?" Someone who can silently manipulate the message to say anything they please obviously has more responsibility then someone who can merely block one image from loading on a web page, and can't hide their responsibility. In the caching example, as long as the cache is correctly and honestly implemented, the browser manufacturer has no effective ability to control the messages I see.
Another example: We typically believe that the phone companies or Internet search providers should not examine or modify the messages we use their equipment to send, but just accurately transmit them. In other words, we expect the ISPs and phone companies to stay off the chain of responsibility by refusing to affect the message, despite the fact that physically, our messages travel via their equipment and they could fiddle with it if they chose. This is also a good example of a time when literal physical reality doesn't perfectly match our conception of ethics: If the phone company simply relayed our message, we do not hold them ethically responsible for the contents of the message, event though in a technical sense they are. In existing law we refer to this as "common carriers", entities that simply carry communication and are not responsible for the message, contingent on their not affecting the message.
Communication Ethics book part for Time. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Only in the modern era, through live television and radio, telephones, and the Internet have we achieved effectively instantaneous communication over long distance. A lot of communication is still not instantaneous. Thus, a single "connection" may actually have a long life. When one reads the Code of Hammurabi, who ruled in 1795-1750BC, one is reading a work across a connection spanning nearly four thousand years. It can be instructive to consider the chain of responsibility for the work: The original author, the transcriptionist, the carver, the archaeologist, the translator, the web site host... note that I am not on it, I'm just pointing at the work and have no control over it.
This is one of the reasons I define connections as a unidirectional flow, rather then the more intuitive (under some circumstances) bi-directional flow. "Connections", and more specifically, the "messages" quite frequently outlast their senders. Modelling that as bi-directional is the only way this makes sense.
Communication Ethics book part for Intention vs. Literal Speech . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
If you read "Hlelo, how are you?", you still understand what I mean despite the typo. (I'm sure you can find some more typos in this work elsewhere for more examples.) But sometimes it isn't so easy to tell what the original message was supposed to be, if the typo or corruption is bad enough. Or sometimes the communicator can't or doesn't say what they mean, or it may not be possible to directly say what they mean in a given medium.
It is always impossible for a receiver to be completely sure they truly understand what the sender was trying to communicate with their message. Rather then opening the topic of whether we can get the "true content" from the message itself, which itself has many large, heavily philosophical books written about it, we will dedicate ourselves to the much simpler task of just trying to make sure that the message itself, the sequence of bits over time, is adequately transmitted from sender to receiver, because that's all we can do.
We will see this come into play later, as we try to determine whether something "really" changed the content of a message or not.
Communication Ethics book part for Fundamental Property: Symmetry. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
We hold these Truths to be self-evident, that all men are created equal... Declaration of Independence
Probably the most important and perhaps surprising result of this analysis is a re-affirmation of something that we all should have understood all along: There is no intrinsic ethical asymmetry in the communication relationship. There is no intrinsic value in being the sender over being the receiver, or being the receiver over being the sender. Indeed, every person and legal fiction (corporation, government, etc.) that ever communicates in any fashion does so as both a sender and a receiver at some point.
I mention this to explicitly contradict the subtle, almost subconscious insinuations by large content owners that they have some sort of ethically advantageous position over consumers that should translate to various special privileges. It can be the case that the sender has something the receiver wants, which puts the sender du jour in a position of power over the receiver, but this is an economic position of power, not an ethical one. It is these relationships that drive the so-called "intellectual property" industries. At any moment the receiver may simply decide not to desire the sender's message, whatever it may be (music, movies, newspapers, etc.), and the economic power the sender has is gone. To the extent this remains a purely monetary concern, the symmetry property is maintained, because after all, the sender desires the receiver's money, too. Capitalism is negotiating the level of desires in such a way that business occurs and money and goods flow.
An example of such a "special privilege": Levies on blank media based on the assumption that the some of the media will be used to illegally copy content, which are paid to the certain large companies who own content. The right to charge what is in every sense a tax is granted to these companies simply because they own content, regardless of whether a given purchaser will actually use if for illegal copying. We consumers don't even subsequently receive the right to place whatever we want on this media based on the fact that we have quite literally already paid for it (at least in the US), which might do something to restore the symmetry; we can still be prosecuted for "piracy". So media companies receive these fees not because it is part of a mutually beneficial bargain, not because it is part of some general mechanism available to all senders, but because they enjoy special, asymmetrical privileges not available to the rest of us.
It is ethically dangerous to promote one person or entities interests over another, for much the same reason that the authors of the Declaration saw fit to put "all Men are created Equal" right at the top. Once stipulated that one entity is superior to another, history shows us time and time again that the leverage is used to gather just a bit more power, and a bit more, and a bit more, and so on and so forth until the inequity is so great the inferior entity rebels in some manner. The authors of the Declaration of Independence were quite familiar with history, and they found this so clear they called it self-evident. If you don't agree that this is bad, I really don't know how to convince you; this is axiomatic.
But beyond the basic argument from "self-evidence" that I just gave you, there is a deeper reason this property must hold: Because any entity is both a sender and a receiver, any "special" treatment accorded to one side must paradoxically be accorded to the other to be at all consistent. This can be hard to grasp, but perhaps the best example is the Berman-Coble bill (see Freedom to Tinker's coverage), which would grant a copyright holder special power in enforcing their copyright. The music industry desires this power, yet when faced by the actual bill, it occurred to them and many others that the bill could equally well be used against them by other copyright holders ("Hacking the Law"). And suddenly, the bill looks much less attractive... You can not grant special concessions to either side of the communication relationship, because those same privileges will turn around and bite back in the next minute as roles reverse. Only an entity which only consumes or only produces can afford this sort of thing, and it is really hard to imagine such an entity; even the mythical "pure consumer" expects that at least in theory, if they choose to communicate they will have free speech, copyright protection, and all of the other reasonable things one expects to protect one's communication.
A couple of other examples: Software companies trading demographic information about their customers like baseball cards yet trying to block the consumer equivalents, such as performance benchmarks of the software (see the UCITA provisions). I acknowledge as one of the counterexamples to this symmetry principle the government's occasional need to keep information classified, but we have the Freedom of Information Act too, showing the balance is merely tipped, not broken.
In some situations, one may voluntarily agree to forgo the symmetry and agree to some set of constraints imposed in a contract by another entity. This exchange of rights is what lies behind our contract law. However, it is unethical to require someone to forgo this symmetry without compensation. Due compensation is a big part of contract law, and I remind you I use "law" here in the sense of "applied ethics"; in theory, a contract is not valid unless both sides receive something of value. It is a judgement call exactly where the line is drawn. You will probably be unsurprised that I consider the actions of music companies unethical at this point, increasingly requiring that the user commit to not performing actions acceptable in the past (such as making personal copies), and yet charging the same amount or even more as was charged historically for the same goods.
Sorry to beat on the music industry, but they have been the most aggressively honest about their intentions regarding these issues. They aren't the only group I disagree with, they just provide the most vivid illustrations.
Communication Ethics book part for A Natural Balance . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This symmetry has always been with us; as I mentioned in Ethical Drift, we've forgotten after so many years of the current status quo. A nice side effect of re-recognizing the symmetry of communication, that all people have equal rights to communicate, is that it provides us a nice balancing point. This principle provides a natural way of examining the relationships between various entities and considering how ethical they are. Is one side elevating itself over the other? Is the other side justly compensated for this elevation? (Mere compensation is not enough; if you paid me a penny for forty hours of work, you are unjustly taking advantage of me, even though I am "compensated".) Is a larger entity using its size abusively? Just this one simple, nearly-forgotten principle has a lot of resolving power when the proper questions are asked.
Communication Ethics book part for Fundamental Property: Only Humans Communicate. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
You remember where I first showed the communication model I'm building? See the people on each side of the connection? One must never forget that communication only occurs between people (and corporations in their capacity as people). This may sound like a strange thing for a computer scientist to say, but it is vital to not get distracted by the technology. Computers are null entities in ethical terms. Only how people use them matter.
This is critical because it is so easy to get sidetracked by the technology, but the tech just doesn't matter, except inasmuch as it allows and enables communication among humans. If a computer just randomly downloads something for no human reason (say, some weird transient bug due to a power spike) and it will never be seen by a human, it really doesn't matter. If someone downloads a music file from a fellow college dorm resident and immediately deletes it, it may be technically illegal (in the "against the law" sense), but ethically I'd say that's a null event. If anything occurs that never makes it back to a human being at some point, who really cares?
It is worth pointing out that by and large, current law sees things this way as well. One does not arrest a computer and charge it with a crime (exempting certain cases created in the War on Drugs, which is beside my point here).
The claim that computers can violate the copyright of software by loading into memory from the disk (necessitating a license that permits this act)? As stupid as it sounds. Who cares what a computer does? The only actions that matter are those performed by a human. Media are just tools, they have no ethical standing of their own. In fact, a human never experiences any copy of any communication located on a hard drive. The only copy that matters is the one the human is actually experiencing, which are the actual photons or air vibrations or whatever else used to "play" or "consume" the media.
Only people matter.
An example to illustrate the point: Suppose a hacker breaks into a computer and installs FTP server software on the computer, allowing it to serve illegally copied software and music. Suppose that four days later, the computer owner notices and takes immediate action to shut the FTP server down. During those four days, the computer may have served out thousands of copyright violations. Ethically, can we hold the computer, and by extension, the computer owner responsible? No! We should hold the hacker responsible, not the computer. Only humans communicate, and the computer owner was not even aware of the offending communication, and took no actions to enable it. His or her computer was being used in communication as a medium by completely different senders and receivers. Ethically, the owner was an innocent bystander to the software piracy.
Note this scenario happens daily, and to the best of my knowledge nobody has ever been prosecuted for being hacked and having an FTP server run on their machine. This could change at any time...
Communication Ethics book part for The Key to Robustness: Follow The Effects . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It turns out this fundamental property is the key to robustness. If we had to pay attention to the actions of every computer and router and device between the sender and the receiver, we'd never be able to sort out the situation with any degree of confidence. The modern Internet is quite complicated, and some innovative and complicated ways of communicating have been developed. As we try to apply older models to these issues, the complexity explodes and we are left unable to determine anything useful about the situation.
But we don't need to worry about the actions of every router and program between the receiver and the sender. All we need to worry about are the results, and who is on the chain of responsibility. The technology is unimportant.
For instance, recall the example in chapter 2, where I talked about the Australia considering requiring licenses for streaming video over the Internet. A bit of thought revealed the complications inherent in the issue: What if I don't stream, but provide downloadable video? What if I send chunks that are assembled on the user's computer and claim I never actually sent any actual video, just some random chunks of numbers? What if I just want to stream video as a 1-to-1 teleconference? If you define the problem in terms of what the machines are doing, then any attempt at law-making is doomed to failure, because there's always another way around the letter of the law. Instead, this ethical principle says follow the effects. If it looks like television, where you are in any way making video appear to many hundreds or thousands of users reasonably simultaneously, then call it television and license it. I don't care if you're mailing thousands of people CDs filled with time-locked video streams, bouncing signals off the Moon, or using ESP. After all, Australia really only cares about effects; the tech is just a red herring. On the other hand, Grandma emailing a video, or 1-to-1 teleconferencing, is obviously not television. The television commission should then leave it alone.
Of course there would be details to nail down about how exactly one defines "television" (remember all those axes in the communication history section?), but that's what government bureaucracies are for, right? "Scale of people reached" is a natural axis to consider in this problem. I'm not claiming this provides one unique answer, but actively remembering the principle that only humans communicate provides a lot of very important guidance in handling these touchy issues, and makes it at least possible to create useful guidelines.
In fact, I submit that no ethical system for communication can fail to include this as a fundamental property. Not only is it nonsensical to discuss the actions of computers in some sort of ethical context, I think it would be impossible to create a system that would ever actually say anything, due to huge number of distinct technological methods for obtaining the same effects. Consider just as one example the incredibly wide variety of ways to post a small snippet of text that can be viewed by arbitrary numbers of people: Any number of web bulletin board systems, a large number of bulletin board systems over Telnet, Usenet, email mailing lists with web gateways, literally hundreds of technological ways of producing the same basic effect. Yet despite the near-identical effect produced by those technologies, if we insist on closely examining the technology, each of those has slightly different implications for who is hosting the content, where the content "came from", who is on the chain of responsibility of a given post, etc. Are we going to legislate on a case by case basis, which even in this small domain is hundreds of distinct technologies? The complexity of communication systems is already staggering, and it's not getting any easier. On the whole, we must accept this principle, or effectively admit defeat.
Communication Ethics book part for Fundamental Property: Everything Is Digital. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Everything is digital. There is no analog to speak of; analog is an artifact of technology, with little to no discernable advantages over digital, except for generally requiring somewhat less sophisticated technology to create and use.
Why is this true? Because digital subsumes analog into itself: Everything analog can become digital, with all the copying and distribution benefits thereof. The Internet even provides us with a way to digitize things that might seem like too much effort to digitize by allowing people to easily distribute the workload. Even the daunting task of digitizing centuries of books has been undertaken, and by now, any book that is old enough to be out of copyright, and is famous enough for you to think of off the top of your head, has been digitized and is available at Project Gutenburg. Other examples:
- The Project Gutenburg Distributed Proofreaders convert public domain books into electronic text by parceling out the various necessary actions to many people. One person scans in the book, a page at a time, which currently is the hardest thing any single person has to do, though there is some hope that robotics can take over this job in the future. The pages are run through an OCR software program, which is much better then nothing but is very noticably inaccurate. The Distributed Proofreaders project uses the web to then present each page and the results of the OCR to a human, who corrects the errors the computer has made. The page and the corrected text are then presented to a second human for further verification, and finally one person knits all the contributions into a whole, coherent e-text.
As I write this, the Distributed Proofreaders are doing such things as War Poetry of the South by William Gilmore Simms (ed.), Quatrevingt-Treize, Abridged by Victor Hugo, in the original French and English, Lessons and Manual of Botany by Asa Gray, and Familiar Quotations by Bartlett (edition not specified). If anything, I've biased this list in favor of the things I at least recognize (Victor Hugo and Familiar Quotations), as I do not immediately recognize anything else they are currently doing. The "popular" works have long since been done.
- The market grew tired of waiting for popular books like the Harry Potter series to be translated into their language, so a distributed translation project sprung up around Harry Potter and the Order of the Pheonix and had it translated into German, in at least an attempt to beat the official translation. Conversions of the book into digital form were available online before the book was even officially released, transcribed from the book. Even before the book was officially published as an E-book, the information was digitized.
- In fact it's getting so easy to transfer book content into the digital realm that book stores were briefly concerned about people coming in with cameras on their celluar phones and taking pictures of the pages of books and magazines.
And that's the hard stuff, like text content. Audio content is so easy to digitize, with such high quality, as such low prices, it's actually shaking up the music industry as it becomes possible for garage bands to suck their sound into the digital realm and manipulate it like the professionals do. Some domains are still tough, like sculpture and 3D art, but certainly not impossible; for instance, every major special-effects-laden movie now uses motion capture, which digitizes motion, frequently in conjunction with machines that scan the actual contours of someone's face, so an actor's face can be used on the computer model. Someday we'll be able to do this in our garages, too, because all that is theoretically needed is a camera, enough processing power, and some clever algorithms; the elaborate setups and dot-laden costumes used by the professionals currently are merely expressions of our technological limitations. It seems to be an unofficial goal of the next generation of gaming consoles (PS3 as of this writing) to have some primitive versions of this capability; one implementation already exists in the form of the EyeToy for the PlayStation 2.
There is a tempation to try to partition communication ethics into "Analog" ethics and "Digital" ethics, but it is hopeless because in the end, there is no real fundamental difference between the two. "Analog" is just a special case of "Digital" where the limitations of technology happen to make it unusually difficult to copy reliably, but that property is not fundamental to the underlying message. There is no point in trying to distinguish between "analog" and "digital" ethically. Talking about the "analog hole" is meaningless; it's just a glorified way of saying that people's ability to copy your content is a problem, with the word "analog" just muddying the discussion.
Actually, I'm bending the truth here for simplicity's sake; ethically, the representation is simply meaningless until it's converted at some point into something a human can experience. So it's not that "everything's digital", it's that for our purposes there's simply no such thing as "digital" vs. "analog". Whether a song is stored as pits on a plastic platter or as magnetic variations on a metallic tape, the medium doesn't matter to the message. But given the way most people currently think of the word "digital", saying "everything is digital" is more likely to be correctly understood.
Communication Ethics book part for Review. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
To review:
- Communication can be modelled as a set of connections along which messages flow from a sender to a receiver on some medium. A given interaction may require several such connections to model; even a simple web request requires two connections (one from the person requesting the page, one to return the page to that person).
- Several elaborations on the model exist in the real world, which can complicate the model primarily by adding more entities to the chain of responsibility, who have the opportunity to fiddle with the message(s).
- We take as an axiom that communication is symmetric. There is no intrinsic ethical value in being the sender or receiver, or in possessing some message that somebody else wants.
- There is no analog, only digital, and things that aren't digital quite yet, but could be if enough people cared.
- We observe that only humans communicate. We also note that we either must accept this as true, or give up any hope of having a rational system of ethics that can actually claim something is ethical or unethical.
Now that we have examined the history of communication, laid down our goals in building an ethical system, and created a model we can use to model actions in the real world and communicate about their effects, we are finally ready to begin applying what we've built to real-world situations.
Communication Ethics book part for Censorship and Free Speech. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the United States, we have the First Amendment of the Constitution that guarantees us certain things.
Congress shall make no law respecting an establishment of religion, or prohibiting the free exercise thereof; or abridging the freedom of speech, or of the press; or the right of the people peaceably to assemble, and to petition the Government for a redress of grievances.
This is less of a concern to some countries, such as China. However, modern communication capabilities can affect free speech in a lot of ways, both enhancing and diminishing, depending on how it is used. No matter how you look at it, freedom of speech will be affected in every country.
Communication Ethics book part for What’s The Difference?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Censorship and free speech are often seen as being two aspects of the same thing, with censorship often defined as "the suppression of free speech". Perhaps there is nothing wrong with this definition, but for my purposes, I find I need better ones, perhaps something a little less circular. My definitions have no particular force, of course, but when grappling with problems, one must often clearly define things before one can even begin discussing the problem, let alone solving it. Thus, I will establish my own personal definitions as the analysis I want to do is not possible with a fuzzy conception of what "free speech" is.
Communication Ethics book part for Free Speech. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It's typically bad essay form to start a section with a dictionary definition, but since I want to contrast my definition with the conventional dictionary definition, it's hard to start with anything else. Free speech is defined by dictionary.com as
- free speech
- The right to express any opinion in public without censorship or restraint by the government.
This definition misses some critical aspects of our common usage of the term. For instance, free speech is of no value if nobody is allowed to listen to the speech; people in solitary confinement have perfectly free speech, but that does not mean that we would have considered it an acceptable solution to lock up Martin Luther King Jr. in solitary confinement and let him preach what he may; along with the obvious unjust imprisionment we would consider this to be an obvious example of trampling on free speech. We should also consider the right to free speech as the right to listen to anybody we choose (subject to possible exceptions later), thus
- free speech
- The right to express any opinion in public without censorship or restraint by the government, and the corresponding right to experience anybody's expressions in public without censorship or restraint by government.
I use "experience" here as a general verb: One listens to a speech, watches a movie, reads a book or webpage, etc.
Since I don't want to define free speech in terms of censorship, lets remove that and put in its place what people are really afraid of.
- free speech
- The right to express any opinion in public, and the corresponding right to experience anybody's expressions in public, without being pressured, denied access, arrested, or otherwise punished by the government.
This definition really only applies to people in a government-controlled territory, like a public park. If one looks around at all of the various ways of expressing ourselves, we find that the government does not own very many of them. In common usage of the term "free speech", we expect "free speech" to allow us to say that a corporation "sucks", express our opinions about pop music stars, and review movies, without the non-governmental entities we are talking about, or that own the means of expression, being able to suppress our speech merely because they don't like it.
Considering both the target of the speech and the publisher of the speech is necessary. Suppose I use an Earthlink-hosted web page to criticise a Sony-released movie. If Earthlink can suppress my speech for any reason they please (on the theory that they own the server and the bandwidth), and have no legal or ethical motivation to not suppress the speech, then in theory, all Sony would have to do is convince Earthlink it is in their best interest to remove my site. The easiest way to do that is simply cut Earthlink a check exceeding the value to Earthlink of continuing to host my page, which is a trivial amount of money to Sony. In the absence of any other considerations, most people would consider this a violation of my right to "free speech", even though there may be nothing actually illegal in this scenario. So if we allow the owner of the means of expression to shut down our speech for any reason they see fit, it's only a short economic step to allow the target of the expression to have undue influence, especially an age where the gap between one person's resources and one corporation's resources continues to widen.
Hence the legal concept of a common carrier, both obligated to carry speech regardless of content and legally protected from the content of that speech. The "safe harbor" provisions in the DMCA, which further clarified this in the case of online message transmission systems, is actually a good part of the DMCA often overlooked by people who read too much Slashdot and think all of the DMCA is bad. The temptation to hold companies like Earthlink responsible for the content of their customers arises periodically, but it's important to resist this, because there's almost no way to not abuse the corresponding power to edit their customer's content.
I also change "opinion" to expression, to better fit the context of this definition, and let's call this "the right to free speech":
- the right to free speech
- The right to express any expression in public, and the corresponding right to experience anybody's expressions in public, without being pressured, denied access, arrested, or otherwise punished by anyone.
There are standard exceptions to free speech, for instance "libel", "slander", "threats", and "community standards." In my opinion, these are not deeply affected by the Internet era, with the exception of what the definition of a "community" is. I want to leave that for later. Thus, my final definition is
- the right to free speech
- The right to express any expression in public, and the corresponding right to experience anybody's expressions in public, without being pressured, denied access, arrested, or otherwise punished by anyone, subject to somewhat fuzzy, but fairly well-understood exceptions.
It should be easily seen that this accurately reflects what we've known as free speech into the Internet domain (and indeed any other domain with equal ease). We can express, subject to the usual limitations, anything we want on a web page, in an e-mail, or with an instant message, and we are free to receive those expression. Unlike people behind restrictive national firewalls in countries such as China where there is no guarantee of free speech, we are largely allowed to access anything we wish.
Though it's not directly related to the definition of free speech, I'd like to add that we expect people to fund their expressions of free speech themselves, and the complementary expectation that nobody is obligated to fund speech they disagree with. For instance, we don't expect people to host comments that are critical about them on their own site.
By far the most important thing that this definition captures that the conventional definitions do not is the symmetry required of true free speech. Free speech is not merely defined in terms of the speakers, but also the listeners.
Communication Ethics book part for Censorship. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
For structural symmetry with the Free Speech section, let's go ahead and start with the dictionary definition. A drumroll please...:
- Censorship
- Censorship is the act of censoring.
OK, that was particularly useless. Curse structural parallelism!
The best way to understand my definition of censoring is to consider the stereotypical example of military censorship. During World War II, when Allied soldiers wrote home from the front, all correspondence going home was run through [human] censors to remove any references that might allow someone to place where that soldier was, what that soldier was armed with, etc. The theory was that if that information was removed, it couldn't end up in the hands of the enemy, which could be detrimental to the war effort. The soldier (sender) sent the message home (receiver) via the postal service as a letter (medium). The government censors intercepted that message and modified it before sending it on. If the censor so chose, they could even completely intercept the letter and prevent anything from reaching home.
This leads me naturally to my basic definition of censorship:
- Censorship
- Censorship is the act of changing a message, including the change of deletion (complete elimination of the message), between the sender and the receiver.
Censorship is not always evil; few would argue that when practiced responsibly, military censorship as described above is truly ethically wrong. Censorship is a tool like anything else, it can be used to accomplish good or evil. But like war, censorship must be used sparingly, and only when truly necessary.
There is one last thing that we must take into account, and that is the middleman. Newspapers often receive a press release, but they may process, digest, and editorialize on the basis of that press release, not simply run the press release directly. The Internet is granting astonishing new capabilities to the middlemen, in addition to making the older ways of pre-processing information even easier, and we should not label those all as censorship.
Fortunately, there is a simple criterion we can apply. Do both the sender and the receiver agree to use this information middleman? If so, then no censorship is occurring. This seems intuitive; newspapers aren't really censoring, they're just being newspapers.
You could look at this as not being censorship only as long as the middlemen are being truthful about what sort of information manipulation they are performing. You could equally well say that it is impossible to characterize how a message is being manipulated because a message is such a complicated thing once you take context into account. Basically, since this is simply a side-issue that won't gain us anything, so we leave it to the sender, receiver, and middleman to defend their best interests. It takes the agreement of all three to function, which can be removed at any time, so there is always an out.
For example, many news sites syndicate headlines and allow anybody to display them, including mine. If a news site runs two articles, one for some position and one against, and some syndication user only runs one of the stories, you might claim that distorts the meaning of the original articles taken together. Perhaps this is true, but if the original news site was worried about this occurring, perhaps those stories should not have been syndicated, or perhaps they should have been bound more tightly together, or perhaps this isn't really a distortion. Syndication implies that messages will exist in widely varying contexts.
Like anything else, there is some flex room here. The really important point is to agree that the criterion is basically correct. We can argue about the exact limits later.
So, my final definition:
- censorship
- Censorship is the act of changing a message, including the act of deletion, between the sender and the receiver, without the sender's and receiver's consent and knowledge.
In terms of the communication model, censorship occurs when somebody interrupts or interferes with the medium such that a message is tampered with while traveling from the sender to the receiver.
Communication Ethics book part for The Difference. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Going back to the original communication model I outlined earlier, the critical difference between the two definitions becomes clear. Free speech is defined in terms of the endpoints, in terms of the rights of the senders and receivers. Censorship is defined in terms of control over the medium.
The methods of suppressing free speech and the methods of censoring are very different. Suppression of free speech tends to occur through political or legal means. Someone is thrown in jail for criticizing the government, and the police exert their power to remove the controversial content from the Internet. On the receiver's side, consider China, which is an entire country who's government has decided that there are publicly available sites on the Internet that will simply not be available to anybody in that country, such as the Wall Street Journal. Suppressing free speech does not really require a high level of technology, just a high level of vigilance, which all law enforcement requires anyhow.
Censorship, on the other hand, is taking primarily technological forms. Since messages flow on the Internet at speeds vastly surpassing any human's capabilities to understand or process, technology is being developed that attempts to censor Internet content, with generally atrocious results. (A site called Peacefire has been good at documenting the failures of some of the most popular censorware, as censoring software is known.) Nevertheless, the appeal of such technology to some people is such that in all likelihood, money will continue to be thrown at the problem until some vaguely reasonable method of censorship is found.
Communication Ethics book part for Combating Censorship and Free Speech Suppression . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The ways of combating suppression of free speech and censorship must also differ. Censorship is primarily technological, and thus technological answers may be found to prevent censorship, though making it politically or legally unacceptable can work. Suppression of free speech, on the other hand, is primarily political and legal, and in order to truly win the battle for free speech, political and legal power will need to be brought to bear.
These definitions are crafted to fit into the modern model of communication I am using, and I have defined them precisely enough that hopefully we can recognize it when we see it, because technology-based censorship can take some truly surprising forms, which we'll see as we go.
Communication Ethics book part for Summary. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
- Free speech is the right to express any expression in public, and the corresponding right to experience anybody's expressions in public, without being pressured, denied access, arrested, or otherwise punished by anyone, subject to somewhat fuzzy, but fairly well-understood exceptions.
- Censorship is the act of changing a message, including the act of deletion, between the sender and the receiver, without the sender's and receiver's consent and knowledge.
Communication Ethics book part for Software and Software Patents. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In general, I think the idea of patents are at least OK. I think the United States Patent Office literally needs help; they are horribly undermanned and can't possibly do a competent job under the present levels of applications and manpower. The system we have may not be perfect, but patents have been a generally good thing for innovation, as long as the patent period doesn't grow too long. For instance, in the traditional domain of patents (strictly physical machines) they seem to be a net gain. This doesn't mean the system is perfect or that I would defend all uses of patents, but it does mean that by and large, it is good in many industries.
But I'm totally against software patents. You might think that's a contradiction, especially if you are not intimately familiar with computer science. In order to show you why that's not the case, we need to come to a better understanding of what "software" is.
Communication Ethics book part for What is a Patent?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is well beyond the scope of this essay to go in depth into the history of patents, which itself can easily fill a book. If you are not familiar with patents, I recommend doing a Google search on "Patents" and "Patent history".
The incredibly brief summary is that patents extend protection to someone who discovers a process that does something, such as a process for manufacturing aspirin. For the period of the patent protection, nobody is allowed to use that method unless they come to some sort of agreement with the patent holder. After that, the patent becomes public knowlege and anybody can use it without penalty. It is a limited monopoly over a process granted by the government in the interests of both furthering progress by giving people economic incentives to do research (by allowing them to benefit from that research), and to benefit society by making sure the knowlege makes it back into the public domain (all patent filings are fully public).
In particular, I'd like to point out that initially, the idea that software could be patented was rejected, as there was no material process that could be patented. A pity this was not sustained, as we would not have the patent problem today.
Communication Ethics book part for What is Software?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
(Even if you are computer expert, you may want to skim this.)
In order to understand why "software patents" are wrong, I'm going to have to explain exactly what software is, and thus why it does not match with the concept of a patent. I am deeply indebted to Professor David Touretzky, who testified in front of Judge Kaplan in the DeCSS trial on this very issue, though in the context of establishing software as speech, not a patent case; what follows is an expanded and elaborated version of what he presented, with a lot drawn from Gallery of CSS Descramblers. Despite the tendency of people (including computer scientists) to lose sight of these facts, the basic ideas behind this presentation extend back to the very beginnings of computer science itself; Alan Turing's classic 1950 paper "Can Machines Think?" addressed many of these same issues.
Communication Ethics book part for What Is Software?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
When most people think software, they think things like MS Word and Mozilla Firefox. This are pieces of software, yes, but they are not what "software" is anymore then Shakespeare's "Romeo and Juliet" is "English". This comparison is almost exactly analogous to the situation in software.
At the most basic level, software is a sequence of numbers, just as written English is a series of glyphs and spaces. These numbers look something like this:
- 2558595091
- 1073777428
- 1382742636
These are "32-bit" numbers; other size numbers are possible. (For more details on this, consult The Art of Assembly Language, particularly the part about the binary number system, which should be relatively easy to understand.)
These numbers have no intrinsic meaning by themselves. What we can do is choose to encode meaning into them. Very simply, certain parts of the number can mean that we should do certain things. We might decide that if the number starts with 255, it will mean "subtract", and when we have a subtraction, the next three numbers indication what numbers to subtract from, the next three numbers indicate what number to subtract, and the last number what bin to put the result in. So 255,858,509,1 (odd commas are deliberate) might mean "subtract 509 from 858 and stick the result in memory bin #1", which would place 349 in bin #1. (Computer people will please forgive me for using decimal; even Turing did it in "Can Machines Think?".) Other numbers might instruct the computer to move numbers from bin to bin, or add numbers, put a pixel on the screen, jump to another part of the sequence of numbers, and all kinds of other things, but since we have a fairly limited set of numbers to work with, all of these things tend to be very small actions, like "add two numbers and store the result", rather then large actions, like "render a rocket on the screen", which even in the simplest form could require thousands of such smaller instructions.
 |
The power of computers lies in their ability to do lots of these very small things very quickly; millions, billions, or even trillions per second. Software consists of these instructions, millions of them strung together, working together to create a coherent whole. This is one of the reasons software is so buggy; just one tiny bit of one of these millions of numbers can cause the whole program to crash, and with millions of numbers, the odds that one of them will be wrong are pretty good. There are many, many ways of making the numbers mean something, and pretty much every model of CPU uses a different one.
However, it is not enough that the computer understands these numbers and what they mean. If only the computer understood these numbers, nobody could ever write programs. Humans must also understand what these numbers mean.
In fact, the most important thing about these sets of numbers is that humans understand them and agree on what they mean. There are ways of defining numbers that no real-world computers understand. Some of these are used for teaching students, others are used by scholars to research which ways work better for certain purposes, or to communicate with one another in simple, clear ways that are not bound up in the particular details of a specific computer. If no human understands the way that numbers are being given meaning, then there is no usefulness to humans.
Communication Ethics book part for Software Is Just A Lot Of Instructions. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Software truly is a recipe, it truly is a list of instructions. And just like recipes in a cookbook are written in English (or even a specific English-based jargon language), these instructions must be written in some human-created language. It's a limited language. a mathematical language, but a language nonetheless, capable of expressing how to do everything a computer ever does. It is the language of problem solving. It extremely precisely answers questions such as "How do I move the mouse cursor?", "Will the asteroid hit earth?", and "How do I determine the square root of 7?"
Any given CPU understands a special language, called the machine language for that CPU. When a computer programmer speaks in this language, and tells the computer "add 2 and 2 and put it in register 4" (a register is a place to store a number), the computer can 'understand' and do it. Machine language is the compromise language between computers and humans, the meeting point between flesh minds and silicon machines. Like any language, there are things that are easy to say and things that are impossible to communicate. (English, for instance, does not communicate mathematical concepts very well, that's why mathematicians have their own mathematical language that looks like this: ![]() )
)
Machine language's most notable characteristic is that it never says anything implicitly, it is always explicit. For computer scientists, where slight nuances in meaning can mean the difference between a calculation taking years, being completed in minutes, or not being completed at all, let alone correctly, this is an important characteristic of the language, because it means there are never any "devils in the details" that can cause unanticipated problems. (Think about how often you have given instructions to someone, only to have them misinterpret them because they weren't precise enough or were misinterpreted by the other person. Imagine the difficulties that could be caused if that literally occurred several billion times per second, and you start to understand why programmers like the idea of a language that is totally explicit.)
 |
Humans almost always represent machine language in a closely related language called "assembly language", which is slightly closer to human languages. Subtracting 250 from 500 and putting the result in bin 1 might be represented as SUB 500, 250, 1. Assembly language traditions tend to be old and come from an age when the machines were much less friendly, so that subtraction operation is likely to look more like SUB I #500, [#250], {%1}; the wierd symbols may look intimidating but like the exclamation mark and colon in English, once you learn what they mean they do not look so strange. Assembly language can represent a more-or-less one-for-one translation from machine language, and is significantly more convenient then looking at the raw numbers.
Communication Ethics book part for Non-Assembly Languages. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
 |
In reality, assembly language is too low level for normal usage by humans. For example, the code in the assembly language figure only sets up a single function call; that's a lot of typing to do something very, very simple; any non-trivial program will have thousands or even millions of function calls, so a function call needs to be as simple as possible because every keystroke will be repeated that many times. Fortunately, we can create our own languages that are simpler to use for humans, and convert them into machine code. Some famous languages of this type are C and C++, Java, Javascript, Lisp, and Fortran, but there are thousands of others. I've created two of my own for graphics processing and audio processing simply to facilitate finishing an in-class assignment. We weren't required to write a language; it was simply easier then the alternative. It is quite easy to write a language for a specific purpose for a person skilled in the art; I only mention the big ones because I expect you might recognize them but I would imagine that not a day goes by without some new little language being created somewhere. Computers don't understand these languages directly, but we can tell them how to translate these other made up languages into machine code that the computer can understand. (The precise mechanics involved in this process are absolutely fascinating, and ranks as one of the great engineering triumphs of the 20th century... and are way too complex to cover here.)
Since even dealing with assembly code gets old very quickly, we taught the computers how to take care of this for us. In C, I can write this:
- area = width * height;
and the C compiler will automatically create the code for doing the multiplication and storing of the value, without the code writing needing to muck about with the exact memory location those things go into, or the exact bin the computation is performed in. And more importantly, the code writer doesn't need to think about these things, leaving their brains free to think about more important, high-level things that only humans are good at doing.
By creating these languages for our own use, which we call higher level languages (because they allow us humans to think at a higher level of abstraction, which we are more comfortable with), we allow ourselves to use words and other symbols where the computer only understands numbers. But before a modern computer can obey our command, the compiler program must convert "area = width * height" back into the machine code numbers that the computer understands, or it will be unable to execute them.
 |
I derived the assembly language in the assembly language figure from the C program in the C language figure above. The C compiler I use works by converting the C code into assembly language, then the assembly language into machine code; I got the assembly language by asking the compiler to stop there. Most of that is just boilerplate; the important line is printf("Hello world!\n");. (The \n tells the computer to go to the next line after it prints Hello world!.) Almost all of the assembly code in the assembly language figure is the translation of that line, pretty much everything except the last three lines, which are the translations of return 0; and is a necessity imposed by the operating system, which always expects a program to return a number back to it. But you can see how it's still easier to read the C then the assembler. Some languages like Python are even simpler, where the code for the equivalent Python program would simply be print "Hello world!". Finally, I let the compiler generate the machine language from the assembly code, a portion of which is shown immediately above.
In order to make the easier languages work, we've learned how to tell computers to convert from one language to another. The computer only knows how to run code in machine language, so there are a lot of converters that go from some language to machine language, but there are other converters that work without ever going to machine language. For instance, there's a program called asp2php that takes code written to work on Microsoft's Internet Server platform in Visual Basic script using their Active Server Pages structure and converts the code to PHP, another web server programming system that allows the creation of dynamic pages.
Communication Ethics book part for Brief Review. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
To briefly review, we've discussed three separate things up to this point:
- Machine code, the actual code the computer executes. This is a series of numbers. The computer is not capable of executing anything else directly.
- Assembly code, which is a nearly one-to-one transliteration of the machine code into something that a highly trained human can relatively easily read. This is generally the "meeting point" between human minds and the computer, although there is nothing impossible about reading machine code directly, it just requires the use of cognitive resources better spent elsewhere.
- High-level languages, which are translated down into machine code by other programs.
Communication Ethics book part for An Unfortunate Dichotomy. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Unfortunately, in computer science's zeal to explain how some of this stuff works to the public, computer scientists have made statements that were convenient at the time about machine language, specifically "Machine language only has meaning to the computer." This is incorrect, but I hope you now understand why this simplification was made, having seen was machine language looks like ("2192837463", or, as we computer folks prefer it, "0x82B40B57" in hexadecimal). It is difficult for a human to follow machine language, we prefer reading higher level languages, but for a competent human, it's only a matter of time to read machine language.
There are tools that can help, too. A disassembler can convert machine code back into assembly code reasonably accurately, which makes it somewhat easier to read. There are ever decompilers that try to convert machine code back into high-level languages, which doesn't always work very well for various technical reasons, but with other tool support, it is possible for a skilled computer user to learn how a program works in a reasonable amount of time, even if they start with just the machine code.
This is not just theory; many programs have been modified by people simply examining the machine language, often to remove copy protection. Game cheating codes like those used by the Game Genie are actually done by making tiny changes to the machine language of the video game. Snake-oil encryption techniques have been reverse engineered and subsequently defeated by examining the machine language alone. Reverse engineering is frequently used to get hardware running in operating systems that the manufacturor has not provided a driver for. Even the author has on a couple of occaisions dived down to the machine language level; in my case, an important executable file was scrambled on disk and I had to re-assemble the pieces in the correct order or I would have lost the file; without the clues from reading the assembly code, I could not have gotten the order right.
Because of incorrectly simplifying the idea of "machine code", people have gotten the idea that machine language is somehow different then those other high level languages. But it's not really that machine language is different, it's that it is a special language (or rather, set of languages) that the machine can execute directly. Despite the fact that we as humans perceive machine code, assembly code, and the various high-level languages very different, it is a difference of degree, not kind. Each is more abstract and human-usable then the last, but there is a smooth progression of languages and possible languages from machine code right up to some of the most abstract languages there are, like Javascript being used in a web page.
There has been work done on creating machines that can execute high-level languages directly, in particular one called LISP. As compilers improved, efforts in this direction ceased, but for those machines, machine language was a high-level, human readable language. We choose to have computers execute this rather obtuse language directly because it makes some things easy, but we are not forced by the nature of computers to do this. We could create a machine with a processor that executed Java directly, without even compiling it as a separate stage, it just wouldn't be as efficient for a number of reasons.
You may not have the tools and you certainly don't have the time, but you could learn absolutely everything about how Microsoft Word works simply by reading its code, because its code is just a list of instructions. Or you can learn how to efficiently sort things by reading code. All computer code, a.k.a. software, from machine code to Javascript and beyond, is communication.
Communication Ethics book part for All Software Is Communication!. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The essence of software is communication, human to computer, human to human, computer to computer, computer to human. The only rare one in that list is computer to human; computers generally communicate to humans in software only when the human is doing research into software (you can look at genetic programming research in this way, where the computers report back the best program they've found to do something). Everything else happens frequently; humans write programs, humans send code back and forth to each other to talk about what it says, and computers send each other code to execute, by downloading programs, sending Java bytecode, or even Javascript in a web page.
For instance, see this very common type of question on a UseNet technical newsgroup. Code is included because the communication could not be done without it. How better to describe what is going on?
When judges see this, it usually impresses them. In the case of Junger v. Daley, the judge ruled that code is speech worthy of First Amendment protection.
"Because computer source code is an expressive means for the exchange of information and ideas about computer programming, we hold that it is protected by the First Amendment."
Judge Kaplan of the first DeCSS trial also was impressed by arguments along this line, though it doesn't seem to have affected the ruling either way.
To the best of my knowledge, neither of these judges were introduced to the equivalence of machine language and higher level languages. It would be interesting to see their reaction to that.
Communication Ethics book part for Patents On Communication?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Getting back to our original focus on patents, here's the problem: The patent system was created to patent objects and processes. In this, I believe that it has done a reasonably good job; the Patent Office's competence may be questioned, but that should not reflect poorly on the concept of patents. However, when the Patent Office decided that software was an object or a process, they made an ill-conceived decision and extended their power into a domain they did not have the tools to handle.
To demonstrate that patents are not the answer to every problem in a non-software domain, think about this: Can works of art be patented? Could there be a patent on the Mona Lisa? Or a patent on Beethoven's Fifth Symphony? Not the paint or the instruments or the making of the canvas, a patent on the painting itself. Does that make any sense? No, it does not, because the patent system was created for objects and processes, not things like art or music. For art and music, we have copyright and other concepts, because the tools of protection must match the domain, or you get silly results.
Consider a patent on "The Mona Lisa". If such a thing existed, it would mean that for a period of 17 years, nobody would be allowed to re-create Mona Lisas, a painting, perhaps set into a particular frame, without permission from the patent holder. However, the patent would not stop anybody from producing a poster of the Mona Lisa and selling it, or a postcard, or using it in a TV show, or in fact, much of anything else, because only the process of producing things just like the original Mona Lisa would be protected; the image would have no protection. When I take a picture of an automobile, I do not violate any patents, despite the fact that any number of patented items may appear in that photo, some possibly with enough detail to re-create the object later (such as patented body panel shapes or fender designs). Copyrights are for that sort of thing, and indeed they are used; I don't recommend that you try to produce a "new" car that looks exactly like a Dodge Viper, even with no patent violations (to the extent that is even possible), as lawyers from DaimlerChrysler will surely come a-knockin'; in the process, you'll violate several copyrights for things like logos or dashboard designs. Similarly, copyrights are silly for machines to produce aspirin; you can't "copy" such a machine, you can only manufacture new ones. The right tool for the right concept.
Patents are not the right tool for covering software. Web pages are documents and programs. There are even images that are also programs. Patenting software is exactly the same as patenting a recipe... not the process of following the recipe, but the text of the recipe itself. It's like patenting the Mona Lisa, it's absolutely absurd.
So after examining the meaning of each word in the phrase "Software Patent", we see that on a deep level the phrase is essentially an oxymoron, a self-contradicting phrase.
Communication Ethics book part for It’s Even Worse Then That. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
If someone was foolish enough to grant a patent on the Mona Lisa, it would not have a great impact on society in general; it's only one painting and it's not ever going to be repeated accidentally. For those who would reproduce it deliberately (traditionally called "forgery") patent laws won't stop them anyhow. The Mona Lisa is phenomenally complicated, including all kinds of little details and hidden layers of paint. But that's not really comparable to the kind of patents the Patent Office is granting.
Communication Ethics book part for Unbelievably Broad Patents. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Ask twenty people to write a program and give them the same specifications, and you'll get 20 very different programs. Much like English, there are often many ways to say something. "The cat chased the dog." "The dog was chased by the cat." "The domesticated canine was pursued by the domesticated feline." Software is similar; the same basic concept may be expressed in many, many different ways.
If a patent was granted only on the specific code written by the patent applicant, then software patents would not pose a threat of any kind to anybody; the odds of exactly replicating somebody else's code are astronomical. Unfortunately, software patents are being granted on effects of code, and not the code itself! Consider Amazon.com's famous "One-Click Shopping" patent. When Amazon.com successfully sued Barnes & Noble for having a similar feature and thus violating their patent, exactly how did Barnes & Noble violate Amazon.com's patent? Well, they certainly didn't sneak over during the night and steal the code from Amazon.com's servers. Odds are, given the different setups of Amazon.com and Barnes & Noble, the One Click Shopping system was implemented almost completely differently, quite probably in different languages on different hardware platforms and different integrations with different databases. It is possible that no two lines of code written by the companies is the same. It obviously has nothing to do with the code.
If it was not the code... then what else is there that Barnes and Noble could have violated? The only conclusion one can come to is that Amazon has successfully patented the entire concept of one-click shopping. If this seems surprising, or an unlikely conclusion, it's not. Richard Stallman, the founder of the Free Software movement and a man who has been programming for decades, wrote an essay called The Anatomy of a Trivial Patent, in which he dissects a very normal software patent. Where physical patents include precise descriptions of components, their shapes and relationships, software patents are written so broadly that they essentially lay claim to entire concepts. A sample from the essay:
Patent excerpt: "using a computer, a computer display, and a telecommunications link between the remote user's computer and the network web site,"
Stallman: "This says they are using a server on a network."
Because computer programs are interconnected with so many other computer programs and hardware devices, it does not take much work at all to expand a trivial idea like One-Click Shopping into an impressive looking patent application that no patent officer is trained to handle. If you read Stallman's essay, you'll find that the actual subject of the patent application takes up very little space; it has to be fluffed up with other irrelevant tripe to take up more then two sentences (and it's hard to make two sentences look like a non-obvious invention).
I challenge anybody who thinks this is incorrect to come up with a rigorous and useful metric for determining whether a given piece of software is covered by a given patent without making any reference to the final functionality of the piece of software. Remember that determining if a given machine violates a patent explicitly does not reference the functionality of the machine, only the design itself.
In fact, patent law is supposed to encourage multiple implementations of the same process! Take a simple example: The turn signals in a car. There are quite a few designs for the turn signal controls, some just working the turn signal, others integrating cruise control or windshield wiper controls. Designing a good turn signal control is non-trivial; while the basic requirement of moving a stick to activate an action is simple in concept, designing a cost-effective switch that will last the lifetime of the car, during which the switch will be used thousands upon thousands of times, in all manner of environmental conditions, and with death or serious injury potentially on the line if the switch malfunctions, is not trivial. Thus, when solutions are found, they are patented. However, there are several variations on the theme that have been developed. Sometimes the auto manufacturer wants a new one to fit in better with the theme of the car, sometimes the car company thinks it will be cheaper to make their own then license one from a competing car company. Thus, there is a reward for creating a new device, both because you can use it and you might get licensing revenues, and incentive for the competition to come up with new designs that will benefit them if they believe the licensing is too expensive. That's capitalism.
But suppose you could apply for, and receive, a patent for "The use of a stick-like object to activate multiple actions, depending upon the direction in which it is moved"? And get the patents for the two basic behaviors, which are "stick", which is when you turn on a turn signal and the stick stays in that position until the signal comes off, and "toggle", which is when you pull back on the stick to toggle the brights on or off. This is what is occurring in the software patent arena. Now, whoever owns that patent completely owns the idea of "turn signal sticks" (along with a wide variety of other things, such as some gaming joysticks). There is no incentive for the competition to try to build their own, because there is no way to build a turn signal stick that won't be a turn signal stick.
Going back to my sentence example, try communicating the concept of "chase" without communicating the concept of "chase". "Pursued with the intent of catching?" "Following more and more closely, in the attempt to occupy the same space?" You can't. If you want to create a One Click shopping competitor, you can't, because no matter how different it is from Amazon.com's system, it will always still be a One Click Shopping system. This is more evidence that Software Patents are absurd... it results in diametric opposition to the original purpose of patent law, which was to encourage diversity in methods of accomplishing the same tasks.
Communication Ethics book part for Synonymous Software. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The problem here is that the patent system cannot handle the software equivalent of synonyms, words and phrases which mean that same thing but say it differently. Let's call software that does much the same thing, but does it differently, synonymous software. For example, Microsoft's IIS server, which is a web server, is synonymous with Apache, a very different web server program. Just like synonyms in English, they are not completely equivalent. Microsoft and Apache use very different extension mechanisms, and the capabilities of the two are different, as well as their ability to run on various platforms, but in terms of what they do, they are very similar, and in general, if one piece of software can do something, so can the other.
One can draw a strong analogy here with the connotation of a word, versus its denotation; both IIS and Apache have the same "denotations" as "web servers", but very different "connotations". Also like English, the same word can have multiple different meanings, and thus have certain senses of a word be synonyms for several sets of words. Example: "Ram" is a synonym for "mountain goat" and "bump into". Some software is flexible enough to be "synonymous" in multiple ways with different sets of software. It's just as complicated as English, which is to say, very complicated. This should not be a surprise, because both English and software use language to communicate, which is one of the most complicated things around, especially when in an environment where the language can be directly executed by a machine.
Because the Patent Office is trying to force communication into a model that was created for objects and processes, it has had to make determinations on what to do with synonymous software. As previously mentioned, there are many ways to say the same thing, such that for a complicated system, which might be factors of magnitude larger then Shakespeare's entire collected works, the odds of somebody stumbling onto the same "phrasing" of that complicated system as the patent holder are astronomical. (Shakespeare's entire collected works are available from Project Gutenburg, and are approximentally 5.5 megabytes. The Linux Kernel source code, just the C source code alone (which isn't the entirity of the kernel) is appoximentally 120MB in version 2.5.70, and still growing.) A patent that narrowly covered only exactly what the company produced would be of no value. Therefore, the only option the Patent Office can stand to consider is the position that all synonyms of a given patent are covered by that patent. (Cynic's note: Handing out worthless patents would make them impotent, anathema to a bureaucracy, all of which inevitably perceive themselves to be of supreme importance.)
This is intolerably broad. It's so broad that absolutely absurd patent battles are emerging. According to this Forbes Magazine article Amazon Tastes Its Own Patent-Pending Medicine dated October 13th, 2000, OpenTV tried to take control of Amazon's One Click Shopping patent. OpenTV makes television set-top box software and infrastructure, and one of the capabilities of their software is the ability to enter credit card information once and buy things by pushing some sort of "Buy" button while watching TV, for instance purchasing a Madonna album while watching a Madonna music video.
In this case, the difference between the two systems is even larger then the difference between Barnes and Noble's system and Amazon.com's system. An interactive television implementation and a web implementation of "One Click Shopping" are so different that they are hardly even recognizable as the same thing. Even if somebody had experience working on one system, if they were hired by the company implementing the other, the experience working on the first system would be of almost no value whatsoever. How can these two companies in two different businesses with totally different technical resources and entirely different languages be conflicting with each other's patents, if the Patent Office is not giving out patents on entire concepts?
As a defensive measure, software companies have taken to simple generating as many patents as possible in as many fields as possible, to build up a patent portfolio. Frequently, these patents partially or totally overlap due to poor prior art checking (done deliberately by the applicant and accidentally by the Patent Office). The point is to make sure that nobody can sue the company for patent infringement without the company being able to counter sue for some patent infringement themselves, an arrangement strongly resembling the Cold War policy of Mutually Assured Destruction. This should be taken for a sign of sickness in the system though, as this has negative effects: First, it negates the point of a patent anyhow when it isn't really possible to sue a competitor for infringement without being counter sued, because the only way to do business is for the most part to simply ignore patents entirely. Second, it completely artificially raises the barrier of entry to starting a software company, because a new company will not have such a portfolio and will be intensely vulnerable to a patent infringement suit by a competitor, unless they are in a totally new field (breaking new, unpatented ground) or a totally old one where all relevant patents have expired. The former is extremely rare, possibly non-existant, and as for the latter, any field where the techniques have been well-understood for more then 17 years is not likely to have room for a new competitor.
The only way to see the current patent system as a good thing is to look at it with the belief that the purpose of the patent system is to line the pockets of certain companies with money, at the expense of innovation. Otherwise, software patents make no sense.
Communication Ethics book part for Quick Reminder . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I want to re-emphasize that I am arguing against software patents, not patents in general. Limited rewards for doing real research seems reasonable to me, even if I sometimes find the use of such patents by certain entities unethical. One can also make a good case that the Patent Office is doing more harm then good simply because of its inability to correctly perform its function due to under staffing, and a technology environment too complicated to allow "human review" to scale correctly. I am not making those arguments here. I am simply arguing that patents should not apply to software.
Communication Ethics book part for Patents v. Free Speech. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This argument is quite simple. Because software is a form of speech, by restricting software through the use of patents, we restrict free speech.
- Software patents hurt artists. The digital art movement is small, but will grow over time. All digital art requires strong algorithms and programs to drive them. The most interesting art will emerge from the most innovative techniques... but if those techniques are patented (as they almost assuredly will be), the artists will be unable to use them without licensing them from the companies. Remember, the power to license, like the power to tax, is the power to destroy; in other words, this isn't just about "money". Companies should not be able to block the speech of the new wave of artists in this manner. If you think this sounds silly, keep in mind that the copyright system has "fair use" clauses, and this is one of the explicit "fair use" reasons: "transformative use". Despite the well-acknowledged need for this sort of protection, patents have none, because patents aren't built to handle speech. Copyrights, on the other hand, are built to handle speech and have the concept of a "compulsory license" that can handle this sort of use, under certain cases. (Look up "compulsory licenses" for more information.)
- Software patents hurt the public, by allowing companies to remove speech from the public discourse. If a company owns a patent on something critical, and the company decides they do not like what a licensee is doing, for whatever reason, they can revoke the license and remove that speech. I wish this was merely a far-fetched possibility, but an October 31st, 2000 article in the California Recorder, Suit Turns the Tables on Patent Critic http://www.callaw.com/stories/edt1031b.shtml, talks about Greg Aharonian and TechSearch. Greg is a patent critic, and apparently annoyed TechSearch. TechSearch owns a patent on a '"remote query communication system", which covers a method for compressing and decompressing data transmitted from a server to an end user.' From the article:
Aharonian had said the patent is so broad that anyone with a Web server could be sued for infringement.
"That's probably not incorrect," said TechSearch founder and president Anthony Brown.
Remember, the original purpose of the patent system was to protect objects and processes... it's hard to shut down free speech by denying somebody the rights to use a turn-signal stick. Aharonian's full speech is the message we would call the website, and the instructions on how to display and process his message. Because this company can patent the instructions part of his speech, the company can deny Aharonian the right to speak. This gives great power over speech to any entity that has a patent on anything relating to communication.
In other domains, such as copyright law, we have explicitly balanced (key word) the rights to free speech against the gains of the restrictions. Since nobody ever thought that patents would enter into the speech domain, there are no explicit provisions for free speech in them, so it should be no surprise that patent laws are not balanced to protect free speech. We would do not and do not tolerate such violation of free speech rights in any other domain. We should not tolerate this in the software domain either.
Communication Ethics book part for Patents & Copyright. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the preceding analysis, we observed that copyright has traditionally been balanced for free speech. It's worth expanding on that, because software counts as an "expression" under current law. As an expression, it is covered by copyright.
To my knowledge, this means that software is the only thing covered both by the patent system and the copyright system. (I welcome correction on this point.) Both systems were set up to balance the rights of the creators versus the rights of the public; since the domain covered by copyright (expressions, or speech) and the domain covered by patents (machines, processes, objects) are so different that they required two separate legal systems, it should be no shock that when one thing is covered by both systems (which were explicitly designed to be separate) that the balance is destroyed.
Remember my challenge to come up with a rigorous and useful metric to determine if a piece of software violates a patent? Even if you could come up with one, it would take some serious thinking, it probably wouldn't be simple, and it would probably have a lot of exceptions and edge case. Coming up with such a metric to see if one software violates the copyright of another is trivially easy; it's basically contained in the definition of copyright. If a program would meet copyright's definition of a derived work from another program, then it is potentially in violation unless permission was obtained. Very simple. Very effective. And if you did manage to come up with a patent-derived metric, it would probably be effectively identical to the copyright metric, only much more circuitous and complex.
Copyright works for software quite well. This provides very compelling evidence that software is truly a form of communication and not an object or a process, because the system with the assumptions built in to handle communication works reasonably well, while the system built to protect physical objects works very poorly. If it walks like a copyrightable work, and quacks like a copyrightable work, maybe it really is more like a copyrightable work, not a patentable work.
The only solution to the Software Patent issue is to at the very least stop granting software patents immediately, and ideally revoke the whole idea as a net loss to society. Nothing else will do. Nothing else will work. Nothing else will be ethical.
It seems clear to me that the best resolution to the problems posed by the conceptual mismatch of "Software Patents" is for the patent system to simply get out of the software patent business, and resume its more traditional duties. Unfortunately, the copyright system will fare substantially worse at the hands of modern communications...
Communication Ethics book part for The Death of “Expression”. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In this chapter, we examine the current foundation of copyright, the expression, and show why "expression" is not an adequate concept to base a system on.
Communication Ethics book part for What Is An Expression?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This subsection is not a substitute for gathering a real understanding of copyright. It is a good idea to learn more about this on your own. There are many good resources online, many targeted at non-lawyers. I strongly advise that if you find these issues interesting, that you take the time to learn more on your own. A Google search on the string "Copyright FAQ" turns up ten excellent resources on the front page as of this writing.
But so that we are all on the same page, including any possible misconceptions arising from my non-lawyer nature, let's extremely briefly review the concepts behind copyrights: Copyright's root concept is "expression". From the Findlaw.com Legal Dictionary:
- Expression
- 1. an act, process, or instance of representing or conveying in words or some other medium: "speech" 2. a mode or means of expressing an idea, opinion, or thought
Copyright protects expressions and nothing else. If you "express" an idea in an essay, you own the expression, but you do not own the idea. You can take anything in this essay, re-express it in your own words, and you will have an "expression" that is every bit as much protected as the one you are reading. It is considered polite to credit the idea, but there is nothing in copyright law that enforces that. There is stuff that covers the use of expressions; if you directly quote this essay, then copyright law constrains what you can do without my permission.
What you can do without my permission is called "fair use". You can quote short snippets for the purpose of commentary, but those quotes must be the minimum necessary for the commentary, and not constitute a large portion of a work. You could not re-publish this essay without my permission with commentary for every paragraph, because that would be a large portion of the work, and thus not be fair use. There are some other things that are "fair use" too, though they aren't as encompassing as many people think they are.
Copyright law is concerned entirely with expressions, how people use them to create other expressions, and how various rights and privileges flow through various economic transactions. The ins and outs of copyright are complex, and in order to truly understand what I am saying here, you really ought to learn more for yourself. But these are the basics: there are expressions, there are protections, and there are some balancing things that people can do without the permission of a copyright holder, mostly for the purposes of free speech.
The other important thing about copyright many people miss is that the protections are not atomic, in the original sense of "indivisible". You can give permission for certain things but not others, which is to say just because you have permission to own a certain expression does not legally mean that you have the right to do whatever you want with it, like copying and re-distributing it. (You may feel you have the moral or ethical right, but that's quite different.) If "Possession is nine-tenths of the law", this is part of the other tenth, where physical ownership of an expression is not very meaningful. Owning a copy of Microsoft Office does not entitle you to make as many copies as you like and sell them to others. Many copyright novices often argue on the grounds that physical ownership confers full rights to them, and they are wrong. (A much, much smaller group of people argue that it should confer full rights, which is a different point entirely.) The "first sale" doctrine does provide certain guidelines on what restrictions can be made on customers; again, consult better resources than this on the first sale doctrine.
Now, you might be wondering why I feel I can just tell you to go look up "first sale" and "fair use" and generally gloss over the details of copyright, when it seems like the details would be important to me. The entire point of this essay is to examine communication issues, and an important part of that is to examine the the historical solutions to these problems. The reason I feel justified in waving away the details of copyright law is that I do not intend to attack "copyright law"; instead, as the chapter title implies I will strike at the concept of "expression", which is the foundation of copyright. With "expression" destroyed, all the rest of copyright law crumbles.
Again, lest you think this simply bombastic rhetoric with little application in the real world, one does not need to look hard to see very real strain in copyright law, both in the various issues covered in previous chapters and in more issues to be covered in chapters to come. Is it really such an extreme claim that the strains come from a fundamental mismatch of the expression doctrine with the real world, rather then merely some transient issues that we can make go away with a couple of laws?
Remember, there's nothing holy about our current system. As demonstrated in chapter 2, as well as the system worked, from top to bottom the copyright system is a system of expedience and purely local targeting. If you need a moment to prepare yourself for the idea that we need to destroy the entire system, I'd understand.
Communication Ethics book part for Why Is The Expression Doctrine Dead?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Before software, expressions were dead. Once made, they would not change or develop, just like a boulder does not change. Nowadays, expressions are living, vibrant things, and if you examine the various ways in which they are alive and vibrant, you'll find that modern expressions shatter the old framework, just as the framework we use to deal with boulders shatters if we try to apply it to elephants.
Example: If a boulder is in the road, we know it will not move by itself, so we need to obtain equipment to move it somewhere where it won't bother anyone, like down into the gully. We fully expect it will not crawl by itself back up into the road, so much so that if we do find the rock back in the road the next day, we do not even think of the possibility of it having moved itself; we immediately ask ourselves what human moved the rock back up. If an elephant is in the same road, it doesn't make much sense to spend hours to get a crane, lift the elephant up, and drop it down the gully. By the time you've gotten the crane, the elephant has likely moved; if it's still there, it might attack you, and that's even more likely if you try to lift it with the crane. Elephants require another conceptual framework to handle the problem; I'd recommend one that accounts for elephants' tendency to gore people to death. This is not something the boulder framework needs. It may seem strange when you first think of it, but upon reflection you should see that very little of your understanding about dead things carries over to understanding living things.
Communication Ethics book part for Derivation Trees. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As long as we consider only a single expression in isolation, there is no significant difference between software/documents and traditional expressions. Single, indivisible units are handled adequately by traditional copyright law; this should make sense, as this is a very common case in copyright law. Where things start getting complicated is when works start using other works to create our new work.
Under traditional copyright law and with traditional technology, the only way to use another work is to include some portion of the old work in some new work, either modified or not modified. Certain rules govern these uses if the original work is under copyright protection. There are endless details that have been worked out over the past few years, but it all basically boils down to the right to use the work and the right to pass that right on. The only possible way to use that work is to include a copy of it in the new work. That's the nature of conventional technology.
 |
So let's look at a example. Consider a simple page in a magazine, with an advertisement using photos, a book review written by a free-lance author, a fair-use quote from the book, and the logo of the magazine. Look at a diagram of the important copyright relationships and agreements necessary for that page (below).The reason this works is that everything boils down to essentially one question: Does someone have the right to include a copy of some expression in some other expression, or not? There are a lot of details, like whether the permission can be passed on, whether the work can be modified, used only in part, or used only in certain geographical regions, but these are all variations on the same basic question of permission to include copies of expressions.
|
|
We can call the tree in the previous image the derivation tree of that expression. It shows what other expressions went into the creation of that expression, and the relationships between those expressions. Despite the fact that a derivation tree of many real-world expressions (such as a real magazine) grow immensely large they are manageable, because they are still quite straightforward.
An expression that does not have a derivation tree, because it is a fully original creation of some kind can be called an atomic expression. For instance, this paragraph considered as an expression on its own is an example of an atomic expression; all the words are fully my own, and as such I and I alone own full rights to it. An expression of some sort, such as a newspaper page or collage, that has some sort of derivation tree associated with it can be called a composite expression. Note that we're still examining the current expression doctrine, so it is still appropriate to use the term "expression". Perhaps someone has more established terms for these; I'd appreciate hearing about them.
Communication Ethics book part for Expression and Derivation Tree Equivalence. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Let's specify the derivation tree more precisely, so we can compare this to what happens in the software domain precisely.
An expression derivation tree is a standard tree structure. A tree structure connects nodes. Each node can have any number of children. A node can be a child of only one node. Each node has certain properties. The parent-child relationship (represented in a figure with a line connecting them) may also carry certain properties in the connection. For more complete information about tree structures, consult the web (or Wikipedia).
Trees are immensely useful structures, and are used in many different ways. In my derivation trees, all nodes represent some expression, perhaps some text, or a picture, or a movie. Each of these nodes has at least the following properties:
- Some collection of rights distributed to the owners of that expression. Every expression is owned by some set of entities. It can be owned by one entity, several entities (in the case of a collaborative work, for instance), or no entities, in which case we call it public domain. Each entity may have varying rights to the expression. For instance, there may be a primary author who is authorized to distribute some work, while the other collaboration partners may only have full control over their own contributions. If there is no owner, then nobody has any ownership of the expression, and it can be used freely.
- The expression itself that the node represents.
- Links to any children it may have. In the static world, expressions always carry their children with them. (For example, the "magazine page" has as a child the advertisement; every copy of the magazine page has a copy of the advertisement as well.) If this is a composite expression as described in the owner-rights paragraph above, then that work also has as children all the separate pieces. Each of those children would also contain a full set of properties describing who owns it. These are shown in the figure by the arrows.
Note that these are integral parts of the expression; if you throw the children away, it is not the same expression. That would represent an expression independently derived, with no children. For instance, in the magazine page instance, if you threw away the advertisement child but the final product remained the same, that would mean that author of the magazine page actually created the advertisement themselves. That's not the same thing at all, because that would imply the author of the magazine page would then have full rights over the advertisement, which they do not. Current copyright law does indeed treat fully independently derived expressions that are the same as separate expressions, in the rare cases where it happens.
Along the links from children to parents multiple things flow:
- The rights to use that expression. Many different kind of rights flow, everything from full rights to just the right to use it that one way. This is determined by the agreement between the copyright holder and the entity using the expression.
This is important to keep track of, because for a given parent expression, different children may communicate different rights. For instance, for a magazine, they might have the rights to publish an advertisement in the magazine issue, but they might not have the rights to put that whole page online on the web, because the advertiser may not grant "online rights" to the advertisement. They could still put their articles on the web, though, because the magazine owns full rights to their own works.
- The instructions on how to derive the parent from the children. This is a subtle point that would be easily missed if we were not eventually going to contrast this with software. For instance, a stock photo used in an advertisement is not generally just placed in the advertisement. It might be rotated 30 degrees clockwise, shrunk by a factor of 2, brightened 20%, and have the text "It's Great!" overlayed in Verdana 24pt font starting on the upper left corner.
This is also an important part of the expression because different legal effects can occur, based on how the work is used. The most important example of this is when the instructions describe a use consistent with fair use. That may mean that the parent has rights to use the expression in the way described with the instructions without permissions from the original copyright holder, but used differently (larger quote, longer snippet, etc.), normal copyright may apply. If we don't carry along the re-creation instructions, then we don't have the full picture of what's going on legally.
It is easy to see with all of this how one can make a living just tracking and enforcing the relationships that arise in the copyright domain. The larger the composite work, the more sources for a work, the more complicated the story becomes.
 |
Note that even as verbose as this image is, and as oversimplified as the example is, even this isn't complete. For instance, does everyone have permission for the fonts used? How often do you think of that? In the real world, everything except maybe the stock photo and the quote would themselves break down into further composite expressions, but this should be enough to give you the idea.
Take a look at the Instructions for the Advertisement: Just because the advertisers bought space in the magazine to print their advertisement does not mean that the magazine can do whatever they like with the advertisement; they are obligated to do neither more nor less then what they agreed with the Advertiser. Also note that there are two instances where the owner of a composite expression, the Magazine Page and the Advertisement, where they also own one of the components. It's important to still show the sub-expressions, so one does not get the impression that the advertisement consists solely of a stock photo, which would be unlikely to be a compelling advertisement unless you got really lucky with someone's stock photo.
It is a common misconception that once you create an expression, you own full rights to that expression no matter what. In reality, what you own is certain rights to control how your work is used in other works. It is possible that someone else will completely independently come up with an effectively identical expression, and they will own full rights to it as well. It is recognized by the court system that fully independently coming up with the same expression is a very remote possibility, but it has happened before, especially in domains such as "musical melodies" where there are not necessarily a whole lot of distinct melodies to be copyrighted.
The derivation tree is just an equivalent way to represent the expression, one that highlights the complicated legal status of the expression; it is neither more nor less true, it's another view of the same thing.
Communication Ethics book part for Locality. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Each of the resources in a given composite expression in the static case are physically proximal, because in order to be included, they must exist in a physical form, right on the final expression. One can not display a picture on a newspaper page without printing a copy of that picture in ink on all of the printed newspapers. This may sound stupid, but it will make more sense when contrasted with the software domain.
In particular, the most important example of physical locality is between the consumer and the expression itself. In the old, static case (think 1970's again), there is no way for many people to consume an expression at a distance. A fully independent copy of the expression must be delivered physically to the user in order for the user to experience the message; this is why the Reader is shown at the top of the derivation tree in the figure, because without the reader this is all an exercise in futility. For any media the user can capture and use (video via VCR, physical possession of a book, etc.), the user will always possess a copy, no matter what the original copyright holder may desire, short of theft or confiscation by the government.
Communication Ethics book part for Encapsulation. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
There is one time where we can ignore the children in a derivation tree, and that's if some entity owns full rights to some expression. This is often the case for music. Large music companies often buy all of the rights to some band's song. As long as the band had the right to all other expressions they may have used to create that song (like sounds from sound effect libraries), and all rights are transferred to the music company, then there is no need to show the children of the song on any graph the song may appear in, because the status of the children has been made irrelevant. The music company, and by extension its customers, do not need to worry that some piece of the song may not be used in certain contexts. The music company has effectively encapsulated the rights of that song and made it as if the song was a totally original expression.
This is strong encapsulation. If we are only concerned about some subset of activities, such as publishing a magazine, then we can drop off the parts of the rights transfer that don't matter to whatever we're concerned about, and we'll see weak encapsulation, which happens all the time. For example, in the magazine page we say the "Advertiser" owns the "Advertisement Copy", even though in reality the copy was written by some individual, who immediately transfered that copyright to the advertising company since it was a work for hire. Since the transfer was full, the Advertising Copy's original owner is hidden by the encapsulation, and we can say that the Advertiser owns it. For a more relevant example to you personally, you do not need to worry about the legality of using the clip art that Microsoft Office ships with; if you read your EULA closely, I believe you will find that one of the few rights actually granted to you and not reserved for Microsoft are the rights to use those pictures in most any way you would care to use them. (Of course this can change anytime, so don't take my word for it.) You can't resell them, but who really cares? For the sake of simplicity, we usually just encapsulate the rights and pretend we have full rights to them.
Notice that with both of these encapsulations, the tree is simplified substantially. The magazine need not worry about whether or not the advertisement violates any copyright, because the advertiser takes care of that. The simplification in the tree reflects the simplification in reality. In the previous paragraph, when I speak of encapsulating the rights to the advertising copy, I am really referring to the mental model you would use. These 'derivation trees' are simplified models of the real trees.
Unfortunately, encapsulation totally depends on the fact that the only type of derivative works are the ones so far described. The ability to encapsulate depends on the ability to make reasonable assumptions about what a person can do to an object. Not to beat a dead horse, but in the static domain, all one can do is copy and use in an expression.
Communication Ethics book part for A Thousand Cuts. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
So why did I bother enumerating all the properties of expressions, such as locality and encapsulation, and going to such effort to show how the expression model works? To show how each and every one of them is broken by modern communication.
Digital expressions enable many more relationships between expressions. While conventional law might be modified to take one or two of these into account, I think you'll agree that when all is said and done, there is a qualitative difference between static and dynamic expressions, just as there is a qualitative difference between dead and living matter. Trying to patch the concepts and thus the law is a lost cause.
Communication Ethics book part for Non-locality. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In order to use a conventional expression, you must have a copy physically present with you. Even television and radio programs must be transmitted to your physical receiver, where with the right equipment you can make a copy of the expression. With dynamic expressions, this is not true. A program can live on a foreign server and it may be impossible to get a copy for yourself.
What does this mean? It is impossible to archive a copy of these expressions. It's impossible to copy these expressions at all, for instance to make "fair use" of them, or to use one's "first sale" privileges.
The entire "ASP" (Application Service Provider) buzz of 2000-2001 was built around this idea that companies can host applications on servers that anybody can use from anywhere (or so the theory goes). It may be convenient, but it also means that if some company decides to purchase service from some ASP, it is technically impossible for them to obtain an archive copy of the "Service" (which consists of software) without the agreement of the ASP. We have the legal right to archive certain types of content, but in order for us to archive something, there has to be something local to archive! Much of the drive around ASP's on the business end derived from the impossibility of pirating the applications (or indeed even canceling your subscription in some cases, if the data was held hostage on the ASP servers, rather then the user's local hard drive), and allowing the ASP to fully control the use of the application.
The "ASP" label died with the dot-com crash, but the concept still lives on in almost every dynamic web page on the Internet. For instance, try archiving the software Microsoft uses to run Hotmail. You can't even access that software expression. You can only see the results of the software expression's execution as the Hotmail web pages.
In terms of derivation trees, it is as if that top link to the consumer has been severed. All of the links in the past required the physical presence of a copy, which implied the ability to do certain things, like make more copies of it. Some of these abilities were codified into what is now called the "First Sale Doctrine". If you do not have a local copy, suddenly those 'rights' become meaningless, because it is impossible to physically perform the acts necessary to copy something. This is having the very real effect of causing people to question the First Sale Doctrine, and some people with economic interests in not having the First Sale Doctrine around are trying to take advantage of this questioning to assert that the First Sale Doctrine should be eliminated entirely.
Note that a normal static web page is not non-local, as the web page itself is downloaded to your computer, and you can make a copy of that. For a dynamic web page, the static web page you receive is local, but the instructions on how to create that web page remain non-local, residing only as software on the original web server. This leads us quite naturally to the idea of...
Communication Ethics book part for Expressions That Generate Expressions. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
A static expression like a book will never generate another expression... it's a book, and nothing more. Dynamic expressions can lead much more interesting lives, where expressions can themselves generate more expressions, without the human intervention that's implied whenever one static expression is used in the creation of another static expression.
This happens all the time in the real world, but I think one of the clearest examples of this is the Gallery of Random Art page. The author of the Random Art page, Andrej Bauer, created the Random Art program. Considering the sorry state of post-modern Art, this qualifies as Art... in my humble opinion much more so then many other things labelled "art". Yet nobody sees the Random Art program, only the random art results. Some of these results are quite good, as shown in the archive on that page, although most are not; if they were a more normal desktop resolution many of them would make great desktop backgrounds.
So, here's the question: Who owns the copyright on those expressions? Technically, since Andrej Bauer wrote the program, he is the only human candidate to hold the copyright, so one may probably safely assume they default to him. But in a very real sense he did not create the thousands of art pieces output by the program. Furthermore, you used to be able to get a screen saver for Windows NT that also generates random art. If you grab one of the results of that program's execution, who would hold the copyright? In this case, modern law would say that the owner of the computer running the program holds the copyright. Yet in a way, these expressions are springing forth from nothing at all, with no distinct author. This is an extreme case, where the user has absolutely no input into the process at all.
Perhaps one could argue the works are not copyrightable, as there is no creativity in the pictures, only the program. (Of course the program's copyright is held by the author.) But those are awfully complex pictures to say that they have no more creativity to them then the phone book, and had a human an absolutely identical expression, we would say they are creative works deserving of copyright protection.
The ability of an expression to generate another expression makes it really hard to draw the line of where one begins and another ends, and if we can't even define what an expression is without ambiguity, the whole copyright system comes crashing down.
I picked Random Art as an example because of its extreme nature; the Random Art program essentially accepts nothing as input and creates output. In the real world, most expressions that generate expressions, such as Microsoft's Hotmail programs, take other expressions and do something with them.
A Deeper Philosophical Issue
I'd like to highlight one aspect of the above that is for the next generation to work out. What is creativity? As computers continue getting more powerful, it will get increasingly difficult to determine by examination whether a work was created by a human or a computer. Can the computer's work be said to pass the creativity test for copyright? If so, then why doesn't the computer hold the copyright?
Consider the Random Art program. Like I said, if a human were creating those works none of us would think twice about granting the human copyright over the works. When we refer to a work as "creative", are we referring to an intrinsic property of the work, such that no matter how it is created it is "creative", or a property conferred upon the work by how it is made? I can imagine arguments in support of both answers.
One assumption that copyright law is based on is the assumption that only humans are doing the creating. It won't affect my analysis, which is intended for the current time frame, not the future, but it will be an issue soon enough, and is interesting to ponder.
Communication Ethics book part for Programmatic Content Manipulations. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The power of software expressions to manipulate other expressions is one of the reasons software is so useful, but it causes confusion as well. There is a whole variety of ways that an expression can take other expressions and manipulate them, beyond the standard copying to a new destination.
Framing & Context Shifting
One simple way of manipulating other expressions that doesn't even include what most people would consider "programming" is the one called "framing". Framing is when you create a website that splits the browser's screen into two or more pieces. One piece shows some website with presumably useful information, the other shows other content, typically ad banners or other money-making material, that has nothing to do with the useful site. The issue of whether this is legal or acceptable has come up several times in court, but (unfortunately) they all ended up settling out-of-court.
As early as 1997, TotalNEWS.com linked to hundreds of news sites on the web and showed them in a frame, surrounded by TotalNEWS.com's sidebar, and showing TotalNEWS.com's URL (because that's how frames work). An out-of-court agreement allowed TotalNEWS.com to continue linking, but to stop framing. In 1998, a dental website, Applied Anagramic Inc, framed content from another dental website, Futuredontics Inc. The court decision that resulted was ambiguous, saying:
... the Court finds that the cases cited by the parties do not conclusively determine whether Defendants' frame page constitutes a derivative work.
Neither case manages to provide any guidelines beyond "Framing might be bad." Despite the amount of time this issue has been with us, court cases have only given loose guidelines against deceptive framing, with little clear definition on what deceptive framing is. The solution to this problem was that the problem simply went away. Convenient, but doesn't leave us with much precedent.
The essence of framing is shifting the context of an expression. One example of this is the McSpotlight site protesting against McDonald's. In their own words:
McSpotlight hijacks McDonald's new site (using Frames) and deconstructs its carefully worded PR spiel.
Emphasis mine. Compare the context surrounding McDonald's web site to the context of the McSpotlight's tour. The entire purpose of McSpotlight's tour is to change the context with which you view McDonald's page, and thus change the message sent to the viewer. Unfortunately for the purposes of this essay, McDonald's web site has changed and the only part of the tour that works now is the home page and a couple of other isolated links, but you can get the gist.
Despite the legal ambiguity, several sites continue to frame content, even large ones like Ask.com and About.com.
Content-Blind Manipulation
While framing has attracted significant attention, it is by far the least technically sophisticated example of content manipulation I can think of. It does not actually affect the original content. If we take one step up on the complexity ladder, we find content-blind replacement scripts. These programs situate themselves between the receiver and the transmitter, intercept the message, and perform some of replacement on the words, paying no attention to the actual content of the page. For instance, you can see a Swedish Chef-ified version of my home page.
I call such manipulation techniques "content-blind" because they are not really looking at the content of the web page. Regardless of the contents of the web page, some manipulations will be performed on whatever is available. No matter what web page you run these scripts on, the results will be essentially the same.
One of the most interesting variations on this theme is the Shredder. The Shredder is an artistic statement about the nature of the web, which ties in rather nicely with the points I'm trying to make in this essay. From about shredder:
The web is not a publication. Web sites are not paper. Yet the current thinking of web design is that of the magazine, newspaper, book, or catalog. Visually, aesthetically, legally, the web is treated as a physical page upon which text and images are written.
Have a look at iRi through the Shredder. What's really interesting about Shredder is that it is itself an artistic expression, absolutely independent of the web pages it may produce as a result of use. The Potatoland.org website appears to contain many other expressions of a similar nature.
While behind each of these scripts lies some static source code, upon which somebody holds the copyright, the static source code does not reflect the true nature of the program/expressions. When you look at the iRi through Shredder, where does iRi end and Shredder begin? The only way to understand Shredder is in its relation to other expressions, which has no equivalent in the static expression world. Considered on its own, Shredder is meaningless; only when acting on something does it have any existence as an expression.
Content-sensitive manipulation
On the highest end of the complexity scale, there are programs that can take some content and dynamically alter it to some specification. Some censorware attempts to work this way, by "bleeping out" profanity and blocking pornography. Another example is translation programs like Babelfish that attempt to translate web content from one language to another. These can be very complex and the only limit to what they can do is human imagination and technical skill. What does that mean about the ownership and liability of the expression that comes out of such manipulation? Is there any legal difference between this and content-blind manipulation or framing? These are not easy questions to answer.
Communication Ethics book part for Dynamism. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Once a static expression is created, it never changes. Yesterday's newspaper edition will be the same, even if you look at it a hundred years from now. A "web page" changes all the time. The homepage of CNN.com changes extremely frequently. Yet appearances can be deceiving. What exactly is changing?
It is entirely possible that the index page of a dynamic site, such as a weather site that allows you to specify your location, will never appear the same way twice, not even to the same person. On a truly mundane level, there may at least be a clock on the page that always shows the time the page was accessed. Yet when you reload a page twice, separated by two minutes, and only the clock changes, in some very real sense we want to say that intuitively, the page hasn't changed. The message changes on a moment by moment basis in the most literal sense, but that's not how we think of it.
It is very hard to make a systematic, formalized definition that matches our intuition, though.
Communication Ethics book part for Concreteness. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
One of the key characteristics of an "expression" is its concrete nature. If something is not concrete, it isn't protected by copyright.
From the United States Copyright Office, Copyright Basics:
Copyright protects "original works of authorship" that are fixed in a tangible form of expression. [Emphasis mine.]
For instance, if somebody makes a speech and no recording of it is made, there is no concrete representation and thus no protection. If a recording is made, then it is protected. Since there was no such thing as a non-concrete expression when these laws were made, many definitions don't even talk about it.
The problem is, software does not have to be concrete. At all. Not even close.
With all the various browsers, all the various personalization options, and all the various times that people visit, it is possible that no two people visiting a modern dynamic website will see the same combinations of pixels, even if they were sent exactly the same expression (HTML code), which may never happen. With many browsers, a simple keypress like "CTRL-+" or "CTRL-" can generate a different looking page then the one you are looking at now without receiving a new communication at all! Yet clearly, there is a pattern of similarity there; clearly there is something concrete there that should be protected. Even with a static web page, all browsers receive the same raw HTML source, yet the appearance of the site may change drastically from browser to browser. So we might guess that the set of all possible renderings of a site is also protected under copyright law. Unfortunately, for even a single page, that is a large set, and there are a lot of overlaps. For instance, imagine two pages that are identical, except for an important image which is different. Both pages can be freely rendered without images by a text-only browser, thus the representation for those pages would overlap, despite the fact the two pages are distinct.
We need a cleaner way of thinking about these amorphous expressions. It should probably match up to our intuition of when sites are 'stealing' from each other, because our intuitions are quite clear and pretty much everybody agrees that when it comes to online theft of design, layout, or even content, they know it when they see it.
Communication Ethics book part for Smart messages. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
And now the flip side of the patent debate: While software may be expression, it is undeniable that it can still perform real work, both in the digital domain and even in the physical domain, with the help of robots. In fact, any manipulation of information, and theoretically any manipulation of matter, can be described as a program running on the right hardware. Yet this software is still just communication, no matter what actions it can take. Along with the enumeration of all the differences between static and dynamic expressions I just took you through, dynamic expressions can do anything you can imagine.
Dynamic expressions (software) can and have directly killed people before; for example, see this list of injuries caused by software. For an example of several actual deaths, see entry 32, which was the focus of the now-classic paper (at least in software engineering circles) "An Investigation of the Therac-25 Accidents". (It reads more like a 60 Minutes special than a software engineering paper.) I daresay no novel has ever killed anyone directly, though the book it was contained in might have harmed someone.
How can the old framework hope to keep up with such a different beast?
Communication Ethics book part for Violating Encapsulation. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It's worth noting that with programs, it's possible to violate the encapsulation of a message, because the program can sometimes reach into a final expression and extract the original parts, in a way not possible for static documents. For a classic example of this, see Online Snafu exposes CIA names, where the New York Times released a PDF document with selected portions "blacked out" to hide names, but did it in such a way that it was still possible to extract the original content from the PDF file.
This doesn't really add any issues that weren't already raised by smart messages, but it's interesting to add to pile of things smart expressions can do that old software can not.
Communication Ethics book part for Conclusion (The Funeral Procession). (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The world "real" appears a lot in this chapter, more then good writing style would normally dictate. There's no way around the fact this chapter sounds so theoretical... well, there's one way, which is to make it about four times longer and show four or five examples of each point, but there's no way you'd sit through that. Instead I want to emphasize that each and every point here is backed up in the real world by real events. I've listed several examples already, there's more where that came from, and if you keep your eye out, you'll see more go by. As abstruse as this seems, each little point is manifesting itself in real effects, and the cumulative strain on the concepts currently used to think about copyright is cataclysmic.
The fundamental problems that copyright law was created to address still exist. There can be no denying it; in fact the problems have gotten much worse as the economic stakes rise. Unfortunately, the legal structures created to address these problems were based on certain foundational assumptions which no longer hold true.
If every foundational assumption of old copyright law no longer applies... expressions need not be in the consumer's hands, expressions can be promiscuous, expressions can't even be cleanly delimited... only one thing can be done: Throw out the old system! It's a bold statement, but there's just too many differences between the world of living, vibrant, intelligent software-based expressions and dead, static, constant matter-based expressions.
Communication Ethics book part for A New Model for Copyright. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
What I said in the previous chapter holds true regardless of your opinions on copyright-type issues. This chapter will try to build a new, more sophisticated ethical framework for thinking about copyright-type issues.
Communication Ethics book part for Why Copyright?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is worth taking a moment to justify this.
There are some people who believe that copyright is obsolete, if it ever served any purpose, and that the only solution to our current problems is to simply do away with the concept of "ownership" of "intellectual property" entirely. Disregarding for the moment the philosophical reasons, I would like to focus on the practical issues behind this movement.
This movement seems to be driven by the copyright abuses and excesses of the current intellectual property industries. The draconian decades-long copyright that artificially locks up our cultural heritage, the indignities foisted on us in the name of End User License Agreements (EULA), the foolish and easily abused DMCA (see justification of the "foolish" adjective later) that is powered by copyright concerns... these things and many more are accurately diagnosed as problems with the system. It seems only natural that eliminating the system entirely will do away with these problems entirely.
Indeed, eliminating copyright entirely would eliminate these problems, but I think that solution throws out a lot of good stuff as well. While the focus is naturally on the monetary aspects of "copyright", and the abuses of the system made enticing by the prospect of profit, there are a lot of other important aspects that should not be discarded. First, there are the "moral rights", which are typically considered part of copyright. These include, but are not limited to:
- The right to integrity of a work. The Berne Convention defines this as "[the right] to object to any distortion, mutilation or other modification of, or other derogatory action in relation to, the said work, which would be prejudicial to his honor or reputation." (Berne Convention section 6bis) I will amplify on this in the Message Integrity chapter.
- The right to claim authorship of a work, which is also defined in the same section of the Berne Convention.
Other countries include such things as the right to respond to criticism in the place it is published, the right to (reasonably) retract, and the right to decide when and where to publish a work (drawn from Ronald B. Standler's Moral Rights of Authors in the USA, last revised May 29, 1998).
Moreover, it remains common sense that by and large, the way to get people to do things is to allow them to profit by doing them. Thus, if you want a rich communication heritage, it stands to reason that allowing people to benefit from creating new messages will encourage people to create.
Communication Ethics book part for Copyright Duration . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is beyond the scope of this essay to discuss how long copyright should last. Such a determination should be made by an economic analysis of the costs and benefits of a given length. Personally, I feel very safe in saying that copyrights are way too large right now, possibly by as much as a factor of 10, but the fact that copyright is too long right now is really independent of the question should anything like copyright exist? I think a lot of the people who would simply abolish copyright entirely have come to that opinion by conflating those two questions. "The current copyright duration is harmful" does not imply "The ideal copyright duration is zero."
There are certainly others who argue for an ideal duration of zero on other grounds; while I don't buy those arguments myself, they are interesting and I respect those who come by those arguments honestly, rather then conflating the two questions.
Communication Ethics book part for The Concrete Part/Human Perception Model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Copyright law, as mentioned before, is built around a model where expression is the root unit of communication. To build a system for the future, we must create some other model that models communication... and the more-complete communication model described earlier can again guide us.
In light of that model, it's fairly easy to break things down into two parts: the concrete part(s), and the human-received message. While they are very strongly related to each other, they are not the same thing and you must understand them both separately before their interactions can be understood.
Communication Ethics book part for Concrete Part of Communication. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The concrete parts of a given message are the parts of the message that can be adequately handled by modeling them as expressions. The reason for this is that they are effectively static expressions, changing only with the direct help from humans, which then makes new expressions.
Take CNN's homepage . While the page that you view is quite dynamic, it consists of lots of little pieces that are static, like photos, news article intros, and headlines. Each of those individual pieces are effectively static bits of information, swapped out over time with other static bits of information, under the control of some computer program running at CNN. "The page located at http://www.cnn.com/ " changes extremely frequently, but the individual parts of it do not.
Also, the program that is knitting all these pieces together is itself static, with changes occurring only when a human intervenes. If you look somewhere, there is some code on some computer somewhere doing all this work. This program can be treated as a single concrete object. Even something as unstable as a search engine result page still consists of a database of processed web pages, which are static bits of data, and some program that assembles them, which has a discrete existence.
All communication, no matter how dynamic, must draw from some pool of static parts. The static parts may be very small, down to even individual letters or numbers (which themselves may not meet the creativity criterion for copyright), but they must exist somewhere.
Communication Ethics book part for Human-experienced message . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The human-experienced message is the way the message is perceived by the human being in the model. In other words, the closest possible thing you can get to the actual human experience. After all, the whole point of communication, no matter what its form, is to stimulate the firing of nerve impulses in the human recipient's brain, which should be considered the "most pure" form of this idea.
It is probably OK in practice to step back one level from this ultimate destination, and focus on the representation that the human perceives and thus in practice refer to "the browser-rendered web page" or "the television transmission reception" without loss, as it is essentially impossible to discuss what happens inside of someone's brain. Nevertheless that is the fundamental effect that we are talking about and there are times when this distinction will matter.
An example of when it is better to use the approximation is when trying to determine whether or not a given person has consumed content. Practically speaking, if you order a pay-per-view movie and then go shopping while the movie is playing, you really don't have a basis for claiming an ethical right to a refund. While it is true in theory that you did not get what you paid for, there's no way one can expect the movie provider to check up on you and find out whether you really watched the movie. Indeed, you'd probably consider that intrusive.
Note we are not talking about "the television program"; a given "program" may be wrapped in different commercials from run to run, and may have a wide variety of advertisements run across the bottom during the show, not to mention random editing cuts for content, fitting the screen, or blatant greed. We are concerned with the actual transmission, the actual images seen, not the "logical" (to use a computer term) content. I am not talking about "the web page", which may be rendered in any of umpteen thousands of variations by various browsers and their various settings; I am talking about the actual final images shown on the screen. I'm talking about as close to the human sensory organs as you can get.
Of course, this directly corresponds to the fundamental property of communication that "Only humans matter." Who cares what your computer sees? Only what you personally experience really matters.
Communication Ethics book part for Comparing the models. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
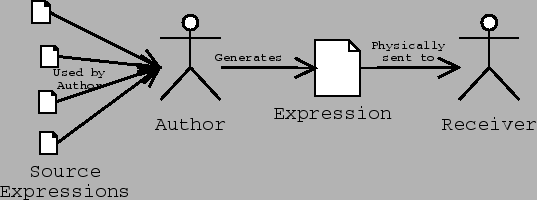 |
 |
Compare the original model with my new model. To understand the difference, consider the rights and responsibilities each pictured participant has. In the traditional model, we have the following parts:
- Author: The author is responsible for ensuring that the use of the expressions violates nobody's rights. The Author has rights to their creation, subject to the limitations of the new expression's derivation tree.
- Expression: The expression is the message. It will never change. As an inanimate object, it has no rights.
- Recipient: The recipient has the responsibility of using the expression in legal manners, as spelled out by the author. The recipient has certain rights such as the right to sell the expression to someone else.
It is not so much that the previous model is wrong, it is simply too simple to handle the current realities.
Communication Ethics book part for New model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the new model, we have the following parts:
- Concrete parts: This is the pool of concrete parts that will be used to assemble the message. The Author may contribute new parts into the pool for the purposes of a single message, but conceptually, any concrete part can conceivably be used in any number of messages. You can see this directly on the Web, where any page can include an image from any server on the Internet. There's no technical reason that this can't be taken even further and applied to things other then images, too.
- Sender: The sender is whoever is driving the final assembly of the message. In the case of CNN, it is the CNN corporation, no matter what parts may have gone into the message. You can always find one entity (or one specific group of entities) that has final say over what goes into the message, and this group bears no particular relationship to who owns the concrete parts making up the message. (For instance, while CNN has final say over what their website contains, they may allow users to comment on the news, which their web servers will show to other people. While CNN didn't author the comments, which are themselves concrete parts, they ultimately have responsibility for whether their web servers show it.)
It is the Sender who ultimately has responsibility for making sure they have the rights to use the concrete parts as they intend to use them.
Note that I'm basically defining the Sender as the entity or group entity that has final say over what goes into the message. Given the number of concrete parts which can go into a message ("as many as you want"), each of which can have entirely seperate authors, this is the only definition that makes sense. There is always such an entity; if you're in a situation where you think there might be multiple such entities, there's actually several independent messages. For instance, you might be in a chat room with multiple participants, and it might look like all of the participants are responsible for the final participation. But in reality, each participant is sending seperate messages, which happens to be interleaved on the screen. This matches reality; if one participant says something insulting, we do not blame the others, because they have no control over the message the insulting participant is sending.
- Assembler: The assembler is a machine or process that takes the various parts and creates a coherent message out of them. The author accomplishes the sending of a message by manipulating the assembler somehow. It may be software, in the case of a web server, or be entirely physical, as in an old-style printing press, but either way, it is a device being operated by a human and as such has no ethical standing on its own. Either the human uses it ethically or not (or conceivably there is no ethical way to use a given assembler), but the assembler never has responsibility for anything. Analysing the assembler and how it is used is our key to understanding dynamic messages.
Now, the creator of the assembler (software author, machine manufacturor) may bear some responsibility for what is output if they build the assembler in such a way that it always includes, excludes, or modifies content in an unethical way. But ultimately it is still the Author's responsibility, because if there is no way to ethically send a message, they still have the option of not sending any message at all, so we need not concern ourselves too much with this possibility.
- Message: This is a message as in our original communication model, where the Author is the sender, it is traveling over some potentially complicated medium, inheriting from the communication model all the ethical consequences of people tampering with the medium, and eventually arriving at the receiver.
- Decoder: For the communication model, it was not necessary to consider a decoder. It's important to break it out for the new copyright model for two reasons: One, it allows us to definatively show where the (practical) human-received message is, and two, unlike assembler tampering, tampering with the decoder is out of the control of the Author, and as such may require special treatment.
- Receiver: Finally, we get to the human-experienced message which is delivered to the receiver, who subsequently experiences it in a manner appropriate to the medium.
Simplicity is important, and it's a strike against this model that it has more parts then the expression model. However, it's also important to capture the dynamics of what is going on, and the expression model critically oversimplifies things, which makes for the confusion you can see all around you. Thus, it's worth the additional parts for the additional accuracy we get from this model.
Communication Ethics book part for New model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Since this is complicated, I would like to give some examples of what all these parts are.
Let's suppose you are reading this in your web browser, via that online version of this that I am providing. What do these parts correspond to?
- Concrete parts: This chapter is composed of some text, and some pictures. The text (represented in HTML) and pictures are each individual files sitting on a hard drive somewhere in Pennsylvania (I think...).
- Sender: That would be me, but not because I wrote this essay. It's because it's my web server and I'm ultimately responsible for what it serves. As the sender, it's my responsibility to ensure I have the proper permissions to send the concrete parts to you. Since I authored the concrete parts in question it is happily quite easy to grant myself permission to serve the parts out. I'm such a nice guy, I'm not even asking me to pay for the privilege!
- Assembler: The web server software on jerf.org.
- Message: The physical incarnation of the message is a stream of bits representing the images and text going to your computer.
- Decoder: The computer you are using, and more specifically the web browsing software, is decoding the message which is just a series of electrical impulses into a visual format you can perceive.
- Human-experienced message: The very photons coming into your eyes, or sound coming into your ears, or however you are perceiving this webpage.
Remember this is all at the conceptual level, not necessary a literal level. For our purposes here a "webpage" is one message, even though at the physical level the decoder (web browser) and the assembler (web server) may actually have a two-way communication. In addition, the "assembler" may not literally correspond to one physical entity either, as multiple webservers may be used to assemble a single webpage. For example, many web sites split their "content" and "images" server for technical reasons. As usual, what really matters in this model are the people. The critical points of view are the ones that the receiver and the author have; once you have that, then you can draw the line around the "assembler" and "decoder" with confidence, even if they are very complicated machines. The technology is not important.
A more traditional example: Suppose this had been published as a traditional book.
- Concrete parts: The exact same concrete parts used for the web page would be used for the book. The text would not be represeted in HTML, it would be TEX or some other typesetting language, and the images would be in a different format, but to the extent possible, they would represent the same text and pictures.
- Sender: In this case, it would be the book publisher, because they would have final authority over what goes into the book. This despite the fact that they did not author a significant amount of the concrete parts going into the book. They would get a logo on the back cover and similarly inconsequential things, so they do have a little content, but it's a vanishing fraction of the whole.
- Assembler: In this case, the book publishing machine, which is probably software driven nowadays but you could pretend there are no computers involved for the sake of argument if you wish.
- Message: The actual book.
- Decoder: Also the actual book; it "decodes" my content by the act of existing and having light fall on it, which then enters your eyes.
- Human-experienced message: Also for all practical purposes the book itself; they should all be effectively identical so there's no benefit to getting more technical then that.
Communication Ethics book part for Original Model In Terms of This Model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
 |
We can look at the old model in terms of the new model, both to better understand their differences, and where the old model fails to capture important nuances.
The old model can be seen as a special case of the new model, when the following conditions are true:
- The "final message" is static, not dynamic, so we need not consider the effects of assembly, which may change over time like dynamic webpages. We can assign all responsibility for that to the author. This collapses the box labelled "Author and Source Expressions" into just the author and the source expressions.
- The expression, having a concrete physical existence (as in the case of a book), is its own decoder and never changes, collapsing the box labelled "Expression" into the expression part of the original model.
The receiver of both models is the same, but note that "Human received message" is still outside of any box. The reason for this is that the human received message is simply not considered in the old model, despite its importance, because everything going into the human-received message is static, so it can be ignored.
But look at what the old model loses. It has no way to represent any of the fancy messages we discussed in "A Thousand Cuts". It can't handle programs that dynamically assemble things from other messages. It can't handle the impact of various web browsers ("decoders") on the message, because in the original expression model everything is intimately tied with its inherent physical representation.
As alluded to previously but not said directly, this model is still tolerably useful when the relationships are all static. For example, the individual article text for the stories CNN runs is still handled decently by the old model. They do not change over time and typically consist of some static set of quotes from sources, writing from CNN correspondants, and other such static material. Where the model breaks down is when programs start dynamically knitting the static parts together. It's impossible to handle the homepage of CNN.com as an expression because it's effectively impossible to nail down just what "the homepage of CNN.com" is. The concrete part and human-perception model works because the problem is broken down: Concrete parts (very similar to expressions) for the part of the message that works well on, and a human-perceived message for each individual experience of the homepage by a person. Separately, they can be treated sensibly.
Communication Ethics book part for Legislating Content. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This separation gives us a much-needed degree of flexibility regarding legislation. It allows one to make laws concerning just the concrete parts, or just the use of concrete parts in human-recieved communication, without needing to rule on the whole communication at once, which is very difficult and tends to overflow into other domains.
For instance, there are laws on the books regarding compulsory licensing of music, setting fair rates and methods of collection. Such laws have become a hindrance lately because of the way the expression concept conflates content with delivery. Thus, there is no one rate set for music licensing, nor even the possibly-feasible rate of licensing given an intended use (background to a radio news report, business Muzak playing, education and criticism, etc.). Instead, the rates are set for music given a certain distribution method, which is to say, the exact mechanics of how the message of the music is sent. Unfortunately, there are a wide variety of ways of distributing music, and subtle variations on each one. One recent example of this is how the law has handled the case of streaming music over the web, which went very poorly and upset lots of people.
Using this model, we can concentrate on just the important questions regarding the two ends of communication. What music was sent in a message, how was it used, and who received it? The exact manifestation of the "expression" is not what matters. It doesn't matter if the user is listening on the radio, or listening to a CD recording of some radio broadcast. What matters is how many people heard it, what the music was used for, and what music it was. Trying to enumerate all the delivery methods is doomed to fail, so don't try.
This drastically reduces the number of special cases in the law by eliminating the need to consider the large and rapidly increasing number of different media for delivery of a message, and would correctly handle an entire domain of concrete content, no matter what transmission methods or other uses are imagined in the future. So even though the new model is more complicated then the expression model, its ability to more accurately reflect the real world move us closer to all of the goals of simplicity, completeness, robustness, and usefulness.
Communication Ethics book part for Legislating Human-Experienced Messages. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The other half of the problem is of course how to handle these human-received messages ethically and reasonably intuitively. Fortunately, it's easier once we abstract the concrete parts away.
The human-experienced message is much more complicated then the mechanics of manipulating concrete parts. As a result, it is worth its own chapters, such as the chapter on message integrity. But I can give at least one example of a purely "human experience" issue.
There's something called look-and-feel in computer user interfaces, or more generally just the idea of style. When Apple sued Microsoft because Microsoft Windows was too similar to the Macintosh OS, it was strictly a matter of human perception of the software. One of the reasons this case was so controversial is that it was one of the first cases dealing solely with human perceptions, where the flaws of the expression doctrine were painfully obvious. Apple was not accusing Microsoft of ripping off any of the concrete parts it owned: Microsoft did not steal code, they did not steal any significant amounts of text (a few menu commands like "Edit" or "Paste" can hardly be worth a lawsuit), and they did not steal graphics. The graphics were certainly inspired by the Apple graphics, but no more so then any action movie car explosion is inspired by another; similarity is enforced by the similar functions and you can't reasonably claim all graphics that bear any sort of resemblence to your own work. Yet Apple contended that the net result was that the human being using experience of using Windows was too much like the experience of using Macintosh to be legal, that there must be some form of infringement taking place.
It does make some sense that there might be some infringement here, even without any concrete parts being stolen, but it is much more difficult to quantify damages or draw boundaries delimiting who owns what. Another ethical complication is that there is frequently societal benefit to such style copying. We no longer even think about many things that are now very standard styles, such as the beginning of books (cover page, detailed info page, dedication, one of a handful of table-of-content styles, all of which are highly standardized across all companies), the looks of late-generation models of any particular device (there tends to be a lot of convergence into one "final" look for the device; consider the near-uniformity of television designs as the design is dominated by a display area of a certain size, and little else, compared to the era when a television was a small part of a larger cabinet), and other such things. There is great benefit in standardizing on interfaces for all sorts of things, not just software, to reduce the time needed to learn how to use the multitude of objects available to us now.
Communication Ethics book part for Goodbye, First Sale Doctrine. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
An expression can be physically possessed. A communication can not. In the case of something like a book, what is possessed is merely one incarnation of the communication, not the communication itself. So it's not surprising that the First Sale doctrine is coming under attack. Yes, there are obvious monetary motives behind the attacks, but the whole idea of a First Sale doctrine critically depends on the world only consisting of expressions. Even without the monetary motivation, the doctrine was doomed to fall anyhow.
It is not necessarily the case that the only possible outcome is that no sharing or ownership is ever allowed, though. For instance, there's no need to restrict a person's right to record a given communication. Indeed, there are many practical reasons to consider such a right necessary. While I would not want to go so far as to call it a right, demanding that a customer only be allowed to receive some communication within a certain time frame, even if they have the technical ability to shift that time frame, is just pointlessly jerking the customer around; it may satisfy the sender's need to control things but it's nothing but a harm to the consumer with no conceivable benefit to society at large.
It is also possible to work out ethically valid ways of sharing a message. The idea that Tom and Fred watching a pay-per-view movie together is ethically OK, but it's wrong for Tom to tape the pay-per-view movie and giving it to Fred for one viewing, is silly. The effect is the same in both cases. The opposite extreme, copying the movie to a computer and allowing the world to download it at will is also obviously a bad idea (even if you don't buy the economic arguments for that, it effectively destroys the moral rights of the authors), but there are intermediate possibilities. Consider a legitimate DVD being allowed to make unlimited copies for his immediate family (or cohabitants, or X people, any limited group), perhaps at some quality loss, but not allow anyone to copy the copies.
There is no way around the fact that the guidelines will be fuzzy and subject to judicial review. In no way does that obligate us ethically to believe that the draconian measures that Hollywood is pushing for are the only solution. Fuzziness is part of life.
Communication Ethics book part for Citation. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
One non-copyright-based example of a something that has already been shaken up by resting on a faulty foundation is the academic concept of citing. How do you cite a web page correctly, which could be evanescent by its very nature? Guidelines have of course been set forth by the various style committees (for instance, see the APA Style Guide). But even a specification of a URL and a time stamp is not always sufficient to specify a web page precisely enough for another user to see what is being cited; the page may be personalized to the specific user or even have totally random content, with no way to cause specific content to appear, not to mention the fact that in general you can't roll a webpage back to the state it had at a given date.
The problem here lies of course in that the citation is trying to cite the human-experienced message itself, which is too transient to make a good citation target. In theory, the solution is to cite the specific static content items that they are referencing, including how they were assembled. In reality, that is not feasible, because there is most likely no way to specify the content items directly, let alone how they were assembled.
In the absence of a strong promise to maintain content at certain URLs in perpetuity with a guarantee of no change, a good promise for an online journal to make, the only solution to this problem is for the academic to save their own copy of the web page they wish to reference, and reference their saved copy instead, again using this as a reasonable approximation to saving the human-experienced message. Here we see an example of where fair use ought to be strengthened in the modern environment, because without the right to do this for academic purposes, there is no rational way to cite things on the web. I accept it as axiomatic that we want academic discourse to continue, even over the potential objections of copyright holders.
The need to save archive copies for academic citation implies the technical ability to so save the content. No Digital Restrictions Management system that I've seen pays more then lip service to this. People need the right to convert transient messages into their own concrete representations and archive them, to the extent that it is technically possible.
(OK, I concede that DRM technically stands for "Digital Rights Management", but I'm not just trying to be snarky; I believe that actions speak louder than words, and DRM manifests entirely in the form of actions that restrict the user from doing something. Thus, I do not see calling it "Digital Restrictions Management" as snarky, I see it as honest.)
Of course once that is granted there's every reason to extend that to the general case of requiring that all content people can experience can be relatively easily archived by the recipient for their personal use, and potentially other limited uses such as the aforementioned academic citation use.
Communication Ethics book part for An Attack?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
One seemingly clever attack on this model that is to write a program that can output every possible web page in theory, then claim that you have rights to all web pages in the world because your program could theoretically generate them. I know someone will email me this if I don't address it here. This is wrong in at least three ways:
- Only messages received by a human matter under this formulation. If a human never sees it, then the theoretical capability of a process to generate the message is irrelevant. Remember, only humans matter! So, you're welcome to make this claim if you're willing to sit in front of your computer for billions of years waiting for something interesting to turn up.
- Even under current copyright law, if two people come up with the same expression fully independently, they both have rights to the expression. Similarly, if everybody creates their human-received messages or concrete parts fully independently of this program, which they did, it still gives the 'random web page' program writer no claim to anybody else's work, present or future.
- No judge in the land would ever imagine that one person could claim all such works like that in one fell swoop. That's the great thing about having humans as a critical part of the law.
Communication Ethics book part for Corollary: Clarification of the Concreteness Criterion . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Under this formulation, something very like copyright law applies to concrete parts. Current copyright law requires that an expression must concretely exist before it can be protected. In light of the previous section, we can further clarify this to say that in order to exist in the eyes of the law, a copyrighted work must exist in a tangible form experiencable by a human. Until it is experiencable by a human, it is neither protected, nor can it constitute infringement.
This is a direct consequence of "Only humans communicate." A copy of a document on a hard drive is not itself a tangible form experiencable by a human. We lack the sensory apparatus to directly experience the magnetic changes on the hard drive or the electric currents that it uses to communicate with computers. Only when the document is rendered to the screen does it become experiencable by a human. This more closely matches our intuition of when infringement occurs.
Going back to a previous example I used of a hacked server being used to serve out illegal copies of software, this helps us understand how we can rationally not hold the server owner responsible. Assuming the owner never uses the software on their hard drive, the owner has not committed any copyright violation. Yes, illegal software is sitting on their hard drive, but who cares? The owner of the hard drive is not experiencing the content.
As a bit of a tangent, I wouldn't even recommend trying to charge the owner with contributory infringement; perhaps someday we will be good enough at writing secure software that we can hold a server owner responsible for everything that happens on that server. But at the current state of the art, where software still routinely has all the structural integrity of swiss cheese, there is never any way to reasonably guarantee that a computer can not be misused.
Another example: The mere act of downloading anything, be it software, music, a document, whatever, is not intrinsically unethical (abstracting away potential second-order effects like using bandwidth somebody else paid for inappropriately). Until the content is experienced, the mere copying is a null event.
Communication Ethics book part for Conclusion. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The Expression Doctrine is dead. It is already useless, in the sense that it produces no answers to modern questions. One way or another, it is going to replaced with something. The question is whether it will be something ad-hoc, or well-principled.
We see that there is a well-principled alternative to the Expression Doctrine, based on a more reasonable understanding of the way communication works. By separating the concrete parts of the message from the dynamic parts of the message, and handling them separately, we can create principles that are much more useful. Laying down the exact principles is a matter of law, but I show how they can be constructed by showing some examples of how these principles make it possible to make rational laws, such as in the field of compulsory music licensing.
Communication Ethics book part for Review. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
By this point, I have synthesized a framework for modelling communication issues. I have begun deriving ethical principles from this framework, most notably the principles of receiver/sender symmetry and only humans communicate. Finally, I have demonstrated not only why software belongs in this new framework, but why software's "mutable expression" shatters the old frameworks and renders them literally meaningless. It is now time to expand the focus a little bit, and try to apply the framework to other issues, and see what more can be learned from a careful examination of the issues. Examining "privacy" will exercise the model well.
Communication Ethics book part for ``Traditional’’ Privacy Defined. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As we did for free speech and censorship, I wish to more carefully define "privacy" and maintain the original sense of the term, while extending as necessary to maintain its sense under modern pressures. The Merriam-Webster Online Collegiate Dictionary defines privacy as
- privacy
- 1. a : the quality or state of being apart from company or observation : SECLUSION b : freedom from unauthorized intrusion <one's right to privacy>
I drop the second meaning, which is considered archaic and not germane to our point: "a place of seclusion", and the third meaning which is basically redundant: "a private matter : SECRET". For our purposes, we may also drop 1a; it contributes to our general understanding of privacy but communication ethics does not come into play when one is alone and no communication is occurring. Thus, we will deal primarily with "privacy" in the sense of 1b: "freedom from unauthorized intrusion".
Communication Ethics book part for United States Legal Basis. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the United States, the right to privacy derives from the Fourth Amendment to the United States Constitution, which is part of the Bill of Rights:
The right of the people to be secure in their persons, houses, papers, and effects, against unreasonable searches and seizures, shall not be violated, and no Warrants shall issue, but upon probable cause, supported by Oath or affirmation, and particularly describing the place to be searched, and the persons or things to be seized.
You can see the word "privacy" never directly appears in the Amendment but based on the definition above ("freedom from unauthorized intrusion"), it's clear how this relates to a person's right to privacy from the government. The doctrine of privacy has subsequently been heavily interpreted by the Supreme Court, in ways that can and have been themselves the subject of lengthy books.
Communication Ethics book part for Traditional Privacy Broken Down. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I see "traditional" privacy as having two aspects:
- Freedom From Surveillance: You have "privacy" in your residence because you can close the windows and the shades and expect that nobody can see you, thus freeing you to perform many acts both socially unacceptable and illegal if viewable in public. One example of this is nudity; illegal if done in a public park, yet a part of everyone's life. Less extreme but the same basic principle, in most places one can still walk down the street without a camera recording their movement. You also have privacy based on the guarantees in the Fourth Amendment that the government won't search or seize your person, house, papers, or effects without a good reason.
I define "surveillance" as "collecting information about people". I deliberately leave out any considerations of "intent". When you accidentally look into your neighbor's window and happen to see them, for the purposes of this essay, that's "surveillance", even though I'd never use the term that way normally. I'd like a more neutral term but I can't think of one that doesn't introduce its own distortions.
The reason I believe intent shouldn't enter into it at the most fundamental level is that the intent of the collector has no effect on the data collected. Nor does the intent of the collector constrain what will be done with the data in the future; police investigations routinely use data that was collected for accounting purposes, such as phone records. Such intent is useful in the context of a specific problem, but it is not worth clouding the issue by trying to make it part of the fundamental part of privacy. "Intent" is a secondary consideration at best. What fundamentally matters is that surveillance has occurred, and information has been collected.
This corresponds pretty strongly with the dictionary definition, but in normal usage with regards to communications issues, there's clearly another aspect as well:
- Information Access: Who has access to what information? We expect that our neighbor can not obtain our criminal record just for the asking, unless this right has been explicitly stripped from someone, such as is the case for sex offenders in many places. We expect our shopping habits, savory and otherwise, are not publicly available. We consider our privacy violated whenever information about us is shared with people who should not have it.
Communication Ethics book part for Analysis. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Despite the dictionary definition, "not sharing information" is the more fundamental of the two aspects of privacy. If surveillance seems to occur, yet the information collected is never shared with a human, in a sense privacy has not truly been violated, even if people may feel it has been.
The real privacy concerns people have today fundamentally revolve around who has access to what information, not what information is collected. One common straw man argument attributed to privacy advocates goes like this: "Privacy advocates want to never given anybody their information, such as their address. But if you wish to order a book to be delivered to your house, you must divulge your address to somebody in order to accomplish this. Since this information must be known by somebody in order to do business, it is not possible to maintain privacy and do business. Since business is important, privacy must fall by the wayside." The "straw man" nature of this argument lies in the definition of privacy as "not collecting information". Nobody disagrees that information is necessary to do business; it is what is done with the information afterwards that constitutes a privacy breach, not the collection itself.
(It is also worth observing that less information is strictly necessary then might be obvious at first, which is another subtle weakness in this straw man argument. One common example is a Post Office box, which does not correspond to a physical location as an address does. The black market uses other techniques to obscure sources and destinations, while still doing business. One method frequently seen in the movies in the context of paying off a kidnapper is the "dead drop". There are ways of making it difficult to collect useful information if the parties are motivated enough.)
I can't prove it, but I would suspect that the vast majority of information collected has some legitimate use, and is not just random surveillance for no apparent reason. Therefore, for the purposes of this essay, I will mostly drop "Freedom From Surveillance" from my consideration. The part of surveillance I want to talk about is captured entirely by considering how surveillance information is communicated.
To continue to refine the generic meanings of the term "privacy" down to what I think is truly fundamental, it is worth noting another distinction based on this separation. What we would typically consider "surveillance" is only (legally) available to the government; it is illegal for a private party to engage in many surveillance activities, for a variety of reasons: Powers reserved to the government (go ahead... try to get a search warrant as a private citizen...), the inability to place cameras in locations owned by the government, practical resource considerations. The only privacy issues concerning individuals and corporations are those concerning the sharing of information. Governments also have the ability to force information sharing to occur, especially in law investigations, because of the natural position of power it occupies. So while in theory I'd draw the separation as in the previous section, when following practical news stories, I tend to group them into two categories: Corporate privacy invasion, and government privacy invasion. Similar to the difference I drew between "censorship" and "free speech", while the effects of corporate privacy invasion and government privacy invasion may be somewhat similar, the methods used to accomplish them, and the corresponding countermeasures necessary, are quite different, and can not be lumped together as one issue without loss of clarity.
Communication Ethics book part for Communication Privacy. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Let us try to cast this refined version of the concept of "privacy" in terms of the communication model. Despite the fact that I consider discussing the ethics of surveillance beyond the domain of this essay, it is worth observing that one kind of surveillance can be easily modelled, the wire tap:
Communication Ethics book part for Wire Tap. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
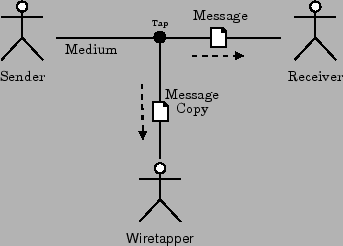 |
A wire tap occurs for some connection when a wire tapper interferes with the medium in such a way that it sends a copy of the message to the wire tapper. A wire tap is usually targeted at a particular entity, which may be either the sender or the receiver of this particular connection, and the wire tap is without the consent of that entity. (If the entity did consent to this arrangement, we would model that as the entity opening new connections to the wiretapper and deliberately sending new messages, containing copies of the original message, which is an entirely different situation ethically.)
In accordance with the only humans communicate property, it is not a wiretap if no wire tapper ever sees the message. In theory, when one sends a message over the Internet or a phone call over the switched circuit network, there are any number of copies made of the message en route to the receiver. As long as the message is not stored and nobody ever sees it, that's not a wiretap, it's just normal operation.
This does not cover all forms of surveillance, of course, just communication interception.
Communication Ethics book part for Privacy . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Privacy is a meta-property of the connection; "sharing" information obtained from a given message occurs outside of the original connection, so it is not strictly a property of a connection. Here's how I'd define privacy in terms of the model:
- Privacy
- Privacy is only an issue when the sender includes information in a message about the sender or some other entity that could be used to cause that entity some form of harm. "Harm" here runs the gamut from "minor annoyance" (another spammer gets your email address) through "life-threatening" (the location of a Witness Protection Program protectee is leaked), varying based on the nature of the information and who obtains it. The right to privacy is the right to control who has access to that information.
I've deliberately left the wide range of possible harm in the definition because I believe that matches how we use the term. Of course as always the exact nature of the possible harm plays into whether a given action is ethical.
In addition to data strictly contained in the message, people are also concerned about the collection and distribution of metadata about the messages, such as patterns in web page requests or what kind of television shows they tend to watch. In a way, this is information that is still contained in the messages, as it can not exist without any messages sent at all. So while it may not be directly contained in any one individual message, there is nothing special about metadata that merits special definition or handling.
Based on the clarity afforded by this definition, we can knock down another common argument against the need for privacy: "If I'm doing nothing wrong (usually wrong is used synonymously with "doing nothing illegal"), then I don't need privacy." There are two basic problems with this argument: One, "privacy" encompasses far more then just "hiding illegality"; certainly information about the commission of illegal, immoral, or socially unacceptable acts fits into the definition above quite handily, in that extreme harm can come to the entity if the information is shared with the wrong people, but that is hardly the only information that fits the definition. It is trivial to come up with instances where a person is doing nothing wrong at all, yet may still wish to prevent some other entity from obtaining information about them. For instance, there's the Witness Protection Program I used parenthetically above; the witness has not (necessarily) done anything wrong. Or consider someone being stalked who wishes to prevent a stalker from obtaining their address or other vital information. (And it's not just celebrities who get stalked, us Normals have to deal with it as well. Most of us probably know someone who has been stalked (to varying degrees) at some point.) Obviously these are extreme examples used for rhetorical purposes, but lesser examples are easily thought of, too.
The second problem is the hidden assumption that the purpose of privacy is inevitably to commit the "sin of omission", to hide something that you should be punished for. I would say this is incorrect. Let us explore the question "What is the ethical reason that privacy is desirable?"
Communication Ethics book part for Information Is Power. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In a nutshell, the ethics of privacy can be derived from the fact that knowledge is power. The more people know about you, the more power they have over you.
Did someone say power? That's a big clue that the principle of symmetry should apply here. We can boil the question down to "Is symmetry between the sender and the receiver maintained?"
We can get a clue from the section describing the symmetry property. We can recast the privacy problem into an economic one, where "economic" is used broadly to mean not just monetary issues, but all value transfers a person may wish to engage in. One of the basic ethical principles of a free economy is that with few exceptions, people are allowed to set the value of what they own. When a person is not free to set the value of what they own, they are effectively under the power of the entity that is setting the "price" for the goods or service.
Examples of this are easy to see by turning to the government. It is illegal to sell body parts. It is illegal to sell yourself or anyone else into slavery. In most parts of the US, prostitution is illegal. None of these things are physically impossible now that there is a law; instead, the "price" for doing these things is significant jail time and/or stiff fines (if you're caught!). On the flip side, where a government can force lower prices, it is illegal to abuse a monopoly to artificially inflate prices. Many prices are subsidized by a government to keep the goods or services available to all, such as Canada's "free" health care. Illegal drug possession can carry stiff consequences. All of these demonstrate how power can be exerted simply by increasing and decreasing the perceived values of various actions and objects.
("Free" gets scare-quoted because I prefer the more accurate term "paid for". Try replacing "paid for" wherever you see the word "free" in advertising; usually the advertisement is much less appealing after that.)
Generally, we want to reserve this unilateral power to governments. A relationship between two persons or person-like entities should be governed by mutual agreement, which is really another expression of the symmetry property: There is nothing special about either entity in such a relationship that entitles one or the other to special privileges. (Ideally, the government is By The People, For The People anyhow so even the powers reserved to the government are in some sense consensual, although in a collective sense rather then an individual sense.)
Using this analysis, we can construct a more active and practically useful definition of privacy:
- Privacy
- Privacy is violated when information of some value is taken from entity A by entity B and used in some manner that might cause A some form of non-monetary harm, without B compensating A in some mutually agreeable manner.
You could cast this in purely economic terms by dropping the phrase "and used in some manner that might cause A some form of non-monetary harm" without too much loss, but that allows too many cases that are purely economic, which I think fails to capture the sense of what people mean by privacy. If I steal a valuable product design document from you and sell it on eBay, that would fit a purely economic definition of privacy as it may cause great monetary harm, but most people would consider that just theft, not a privacy issue. So let us confine ourselves to discussing non-monetary harm, which as I mentioned above ranges from "minor annoyance" to "life-threatening". I also observe that this is not always a strict separation; one privacy violation can cause both monetary and non-monetary forms of harm at the same time, possibly constituting both theft and a privacy violation.
This definition has a distinct advantage over the previous one: It provides us with an easy yardstick to examine privacy relationships in the world around us to determine how ethical they are. We can also define privacy-sensitive information:
- privacy-sensitive information
- Information that could cause an entity non-economic harm, which the entity may or may not be willing to sell for some price.
You could probably write this next section now without me spelling it out for you, but good essay form requires me to do it anyhow, so please bear with me as we apply the yardstick to real life.
Communication Ethics book part for Applying the Privacy Yardstick. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is easy to see that in attempting to apply this yardstick, one must carefully search for people or person-like entities that actually meet the guidelines for ethical behavior, rather then the opposite. Current common practice appears to be to take whatever you have the technical capability of acquiring.
Most information collection right now is either:
- fraudulent: The target of the information collection is not even aware that some privacy-sensitive information is being collected, so how could any mutually agreeable method of compensation be arranged?
- forced: The target of the information collection has no effective choice about avoiding the collection of the privacy-sensitive information, or at the very least,
- the invasion is a result of product tying in an ethically questionable way, requiring a customer to part with some information in order to receive products or services important to them.
In theory we can avoid nearly all privacy invasion by moving into a hand-crafted log cabin and living off the land. Often a false dichotomy is handed to us between doing that, or putting up with the privacy invasions that seem to be a part of modern technological life. But it does not follow that this dichotomy should exist. If a monopoly exists in a given domain, or all producers of some good or service engage in some privacy violation (effectively an "oligarchy" from the point of view of privacy issues), then there really is no effective choice. This is an abuse of monopoly or oligarchy power to force you to either lower you price for your privacy sensitive information (down to zero) or do without some good or service. This is unethically raising the price of a service beyond what a competitive, informed market should bear.
Another virtually ignored aspect of the current privacy free-for-all is the effect of distribution on information. I do not particularly care that my insurance company knows my mailing address. They need it to send me my bills. Yet when they sell this exact same information to other entities, I consider my privacy violated, as they send me pre-approved credit card after pre-approved credit card, which I must spend my valuable time destroying to prevent somebody else from using the applications or cards to rack up charges in my name, which has already happened to my wife once. Information harmless in one entity's possession may be very, very harmful if another entity gets it, yet there is little or no acknowledgement of this fact in either economic reality or the privacy debate.
This answers another common argument, the claim that once I have some information, I can sell it to anyone I want. There is a usually-unspoken claim that a person's privacy is no more violated after the sale of my address information then before the sale, when at least one person already possessed the privacy-sensitive information. This argument falls down on two points: One, with every harmful event that occurs caused by additional sale and use of the information occurs, the privacy violations become more and more ethically serious. The only way to sustain this argument is to frame the problem in terms of binary "privacy violated/not-violated", which as usual is too simplistic to handle the real world. Two, I may not consider my privacy violated at all until the sale, if the first entity has some good reason to have the knowledge, so there can still be a fresh privacy violation, even with a binary view.
In fact, the vast majority of value things like our address have to marketers is the value it has in combination with other bits and pieces of information. It's really the exceptional database where each single record is inherently a privacy violation; your credit record, your medical history, and your criminal record, if any. The rest of the value lies in the combination with seemingly harmless bits of information. Thus, when you see privacy advocates like myself getting upset at what seems to be a trivial violation, bear in mind that we see it as not an additive privacy violation, but a multiplicative violation. The first few bits of data are worthless, but start adding a few thousand bits here and a few thousand there and pretty soon you're talking real knowledge.
The state of privacy in the current world is absolutely reprehensible, not because so much privacy-sensitive information is being collected, but because so much information is being collected and used without mutually agreeable compensation being arranged for the source of the information. Instead, entities, mostly corporations, are abusing their positions to effectively force people to cede this information for no benefit whatsoever, and with little or no effective ability to just opt-out of the collection entirely if the collecting entity is unwilling to meet the price set by the information owner. Further, there is no acknowledgement of the increased value of information as it combined with other bits. This is basically large-scale theft, in many cases theft of information that has value transcending mere money.
Communication Ethics book part for Who Needs Privacy?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
To go back to the argument that started this all, "If I'm doing nothing wrong, I don't need privacy", what an incredibly simplistic and naive view of privacy that exemplifies! It would be nice if we could simplify privacy down to only "hiding crimes" and make a hard-and-fast judgement on privacy that applies for all, but it just doesn't work in the real world. "Hiding crimes" is only one rather small aspect of the whole of privacy, and it's not even a very interesting one in the final analysis. It's just a particular case involving high levels of harm, which isn't that unusual as many other privacy violations can include similar levels of harm without involving crime; ask anybody who has had to recover from identity theft how much fun that is. It is incredibly short-sighted to take that small aspect of privacy and try to extend it to cover all cases.
It is equally foolhardy to force one person's values onto all, as it would be foolhardy to do so in the monetary arena. Some people may value their privacy so little that they are effectively willing to give everything away, but that does not imply that that is necessarily true for everyone. (I wonder how many people truly don't value their privacy, and how many people would suddenly value it if a fair market arose that would pay you a fair price for your privacy-sensitive information. ) One of the Great Truths of Life is that people value things differently; this is a very important part of life and can not be simply waved away just because you only see your own viewpoint, and thus see only one value for things.
In fact, another way of phrasing my rebuttal to the "If I'm doing nothing wrong, I don't need privacy" line is based on pure economics: When your privacy is violated without mutually agreeable compensation, you are quite literally being stolen from. If you don't really care about privacy, that's fine, but you should still be compensated for the information being taken from you. You are literally losing value measurable in dollars in today's anarchic environment every time your privacy is invaded.
How do you know there is a value measured in dollars? A corporation would not bother to collect and sell such information if there was no monetary benefit, so the simple observation that the corporations obviously consider themselves enriched by this privacy-sensitive information is sufficient to show that it has a dollar value to them. It would be hard to put a solid number on such a diffuse asset for a corporation, but for a more solid number, criminals were able to sell stolen identity information for as much as $60 per record in 2002. I'd guess that was a conservative valuation, too, since those records were used to commit large-scale credit fraud.
Privacy-sensitive information is treated so cavalierly now that it is leaked without a second thought:
One credit card company kept calling and calling even though I repeatedly said it was a wrong number. They insisted, so one day, I just never said I wasn't the guy they were looking for.. It got scary: I never realized how easy it is to get information from people like this.. These repo/credit companies call and give you soo [sic] much information without verifying who they are talking to. I knew all about this guy that had a white ford ranger pickup about to be repo'd, he only had a PO box (haha they sold a pickup to a guy with no address), he made cabinets, lived in New Mexico, had my phone number, hadn't paid his $239/mo payment for 4 months, AND I verified his social security number. I got all this information through passively sitting through their "can you confirm your address is..." type questions. - "Broodje" on Slashdot
Why bother validating you're talking to who you think you're talking to, when there's no penalty for leaking this information? Note with a name and a social security number, "Broodje" could have committed any credit card fraud he'd please. Identity theft can never be completely eliminated, but such casual treatment of privacy-sensitive data makes it easy; if data was treated with more respect and more suspicion it would be much more difficult to commit identity theft.
Who need privacy? Everybody! Everybody, that is, who is interested in not being forced into subservient relationships, including criminal ones, by any entity that happens to have the power to collect information that might be harmful to you. I suppose if you don't mind this subservience, then privacy issues won't bother you. But please forgive the rest of us for objecting to the yoke.
In the era of "power politics" where every conceivable petty "power struggle" is immediately transformed into a violent struggle of epic proportions, where people equate denying a promotion based on race to murder with a straight face, it's easy to tune this line of reasoning out. But I think at the core of the power rhetoric there is still some kernel of truth. When a telemarketer calls me because they have my number, obtained through a privacy breach, and they take 10 seconds of my life away (which is about as far as they can get now), that is a real power they have over me. This is hardly the end of the world, yet one should not make the mistake of exaggerating in the opposite direction. This is a real effect, and in the course of your life, the amount of your time wasted by telemarketers becomes significant, time you cannot get back. It's hard to see because there's no alternate world you can peek into to see a life without privacy invasions to compare to, but this is very, very real. As people continue to be complacent and unable to perceive the effects clearly, they are getting worse and worse.
Why can I safely predict privacy violations will continue to get worse? Because there is an inherent economic interest in pushing privacy violations as far as possible, by definition. Violating privacy means some value profit for the violator, with no motivation to stop and every motivation to increase the violations. Until we actively fight this as a society, it will get worse indefinitely. Someday we will rise to fight this, too, because the intrusion is going to monotonically increase in the absence of backlash.
Communication Ethics book part for A Social/Personal Footnote . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is undeniable that there are social and personal aspects to what sort of privacy is desirable. Many of these aspects are unimportant, and can be determined by the society as they see fit. Whether or not you keep your blinds open on a first-floor apartment is a personal, ethically neutral decision.
The preceding analysis also gives us a method for determining whether or not an issue is such a purely personal or social decision, or a decision potentially containing ethical concerns. If the information gathered fits into the above analysis, then there is at least the potential for ethical issues to emerge. If the analysis makes no sense for the particular issue, then it can be determined by the society or person (as appropriate) with no ethical issues to worry about. Many mundane daily privacy issues are of this nature, but it is also a mistake to then assume that all privacy issues are of this nature, which I've also seen.
Communication Ethics book part for Privacy Legal Machinery. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The most interesting thing about this analysis is that it almost directly parallels the arguments for having the whole concept of intellectual property in the first place. Ethically, people must own their privacy sensitive information, there is a value loss if the privacy-sensitive information is stolen (sometimes value not measurable in mere money), we must have fine-grained control over this information. It should be easily seen that privacy-sensitive information is just information, like anything else, and as such, constitutes concrete parts which can be used to create messages, with all that implies.
This is a powerful mechanism for understanding the great variety of ways in which privacy-sensitive information can be abused. There would be no e-mail spam in the world were it not for the ability of smart expressions to take a list of email addresses, which are privacy-sensitive bits of information, and send emails to each one, a simple attack not possible before the computer era. If it wasn't for the great interconnectedness of modern databases, a simple error in one credit history database would not be able to screw up a person's life for months or years at a time.
Communication Ethics book part for Can We Use Existing Machinery?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This would seem to call for some sort of legal protection. At first glance, it seems like we could just declare privacy-sensitive information to fall under copyright laws and be done with it. If this worked, it would have the virtue of simplicity. Unfortunately, on closer examination it doesn't work at all.
First, original copyright law deals only with expressions. You cannot copyright a fact, for several reasons, not least of which is failure to meet the creativity criterion. This makes it extremely difficult to use copyright machinery to protect such information. Ignoring the creativity problem, you could try to justify other's recordings of your address as a derivative work of your original recording of your address, but that does nothing to prevent people from independently recording your address, getting their own "copyright", and leaving you unprotected.
Second, as we discussed above, copyright in its current form really only deals with the concrete part aspect of communication. Our whole desire for privacy centers around the desire to control the flow of the information, which is to say, the human-experienced part of the communication. This highlights one way in which that division is sensible. Copyright is not a very good mechanism right now because the expression model can't handle this sort of information, and hopefully once copyright is simplified to cover only the concrete part aspect, it will be even less appropriate. We need some other form of protection, one that does not exist right now.
In its current form, copyright is primarily concerned with the recovery of loss. The penalties for copyright violation increase as the damage done to the copyright owner increases. We want a legal mechanism concerned with the prevention of injury, which is completely different.
The closest currently-existing legal mechanism that meets that criterion is trade secret law. There are some similarities: Trade secrets protect information of economic value as long as it is maintained secret. It is concerned with preventing the secret from getting out and being used by somebody else for gain, which sounds like how we'd like to protect privacy.
But there are some serious problems, too: Once the trade secret is independently found, it is no longer protected, so one accidental release of your address without proper trade secret protection and it's no longer a secret. Since by now we've all released all kinds of personal information without trade secret protection, we can't even claim trade secret status on our information in theory or in an ambitious lawsuit. It also (as far as I can tell) deals strictly with monetary value, where our privacy concerns go beyond that, as we wish to be able to consider some information priceless, as is our right to set the value of our information.
Current legislation dealing directly with privacy suffers from the same symptoms as the rest of intellectual property law. It is haphazard and chaotic as it tries to deal piecemeal with each isolated situation as it arises, instead of being based on a cohesive theory of privacy. It is a list of special cases, which is obsolete before it is even put into effect. It is clearly inadequate for the larger task of protecting people's privacy as a whole.
So to answer the question posed in the title question: No, there is no existing legal machinery that we can use or extend to protect our privacy. Even the current privacy laws are too focused to be made generally useful.
Communication Ethics book part for A New Form of Intellectual Property . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The only practical way to protect privacy is to create a new legal concept matching what I call privacy-sensitive information and create the legal machinery to protect it.
We need to grant entities the right to decide what constitutes "privacy-sensitive information" and require information brokers to respect the fact that the information is considered privacy sensitive and not distribute it. We need clear guidelines on what constitutes "privacy-sensitive" so that people can't abuse it, as they inevitably will. The definition given above would be a good start, as it correctly focuses on people and not technology, unlike other attempts I've seen to create privacy machinery. We need to establish meaningful penalties for violating privacy, applicable across the whole domain of privacy-sensitive information, not mere subsets like "medical data".
Sound ambitious? It really isn't. Already current privacy legislation is hinting at this level of protection. There is precedent for controlling the dissemination of information, in both the form of trade secrets and the concept of confidential information. There is precedent for the owner of information setting value or refusing distribution entirely, as in current copyright law. (Compulsory licensing is the exception, not the rule.) There is certainly precedent for granting only limited rights, not a binary "possession/no possession" status, in current copyright law.
This is not calling for anything truly novel in execution, only a re-combination of already-existing legal machinery. Given the existence of copyright, patents, trademarks, trade secrets, and confidential information, this isn't so much a blazing of new territory as closing a gap in existing communication-ethics-based law, one being exploited by many entities as they benefit from selling our information without passing any benefit back to us.
Finally, one way or another more privacy legislation will be enacted. It can either try to merely address symptoms, which we've already seen in legislation like HIPAA, or more directly solve the fundamental problems. For society's benefit, the latter is much more desirable.
Another nice benefit is that once these protections are enacted, a privacy market can develop, allowing society itself to directly decide what their privacy is worth, almost exactly analogously to how the government manages the economy itself. Many people have researched how this could be made technologically feasible, but without a legal framework enforcing the technological protections, the technological solutions are worthless in practice.
Communication Ethics book part for Practical Privacy. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I stated earlier that prevention of surveillance is less fundamental then prevention of communication of information, and that preventing surveillance is more a practical concern then a theoretical one. By this I mean to imply that a focus purely on surveillance, without addressing to whom that information is communicated, is doomed to failure, because of the number of fully legitimate sources of information.
I do not mean to imply that it is a waste of time to pursue limitations on surveillance, though. Obviously, information never collected can never be communicated in such a way as to violate privacy. In the long run this will not be sufficient, though, because the amount of information that can be extracted from communication always exceeds the literal content of the communication.
Suppose you are given all the receipts from my grocery shopping trips. Along with the literal information contained directly on the receipt, which is simply a list of items, you can derive much interesting information. With a good baseline understanding of the shopping patterns of people in my demographic group, you could probably derive the fact that I am trying to lose weight on a high protein, low-carb diet, but that someone else in my household is not on that diet. You could derive I like certain types of food, and perhaps that I dislike others.
Beyond that, if you had a large enough database, you could derive other things. If someone buys a lot of Gatorade or other sports drinks, it is more likely they are males age 14-30. Buying mineral water would be associated with other personality traits. Buying a lot of herbal remedies would be associated with other traits. The amount of information obtainable just from a large collection of your grocery receipts would probably surprise you.
Start combining sources of information together and the possibilities increase even more. While it is not possible to build a 100% accurate model of a person, a lot of privacy-sensitive information exists in data that could only be discovered by combing through a lot of data. This is exactly the sort of thing the government was proposing with its Total Information Awareness program.
This suggests another practical avenue for controlling privacy violations, which is enacting restrictions on who can combine what data. Exactly what restrictions would be in place is a matter for specific law, but I would suggest that licensing people who can access this sort of information would be a fine idea. The privacy value of even such mundane data as how much Gatorade I buy increases as it is combined with other data, and that should affect how we perceive the ethics of such actions. This is another sort of thing where sufficient changes in quantity becomes a change in quality; adding two pieces of data together is probably harmless, adding millions very intrusive, and while there is no obvious, firm line we can draw where the transition occurs, a transition occurs nonetheless.
Again, lest you think this is theoretical, watch a detective drama on television sometime, such as CSI. While the television detectives of course live in an idealized world where every problem has a neat solution, the general principle of convicting a criminal based on a scrap of thread, the precise impact angle of a bullet, a thirty-second cell phone call record (not even the contents of the call, just the fact one was placed), and the microscopic striations on a bullet shows how much information can be extracted from even the simplest scraps of data, when intelligently assembled. In fact, there's nothing particularly hard about this, we all do similar things all the time; the only challenge is automating such logic.
Communication Ethics book part for Conclusion. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the final analysis, modern privacy concerns center around the flow of privacy-sensitive information, rather then the gathering of that information in the first place. In other words, privacy is primarily a communication concern. Concerns about surveillance are practically worthwhile, because it's difficult or impossible for an entity to possess information without communicating it to somebody, but in theory it is possible. By modelling privacy concerns based on the flow of information, we can and should begin to see such information as another kind of intellectual property, subject to the same protections and legal machinery. It should be legally meaningful to say to a corporation that they can have my address but are forbidden to sell or even give that information to anyone else (even "business partners"), just as they can sell me a book contingent on the condition that I don't post copies on the Internet, regardless of the price I'd charge. New legislation will be required to support this, but not truly new legal principles.
Communication Ethics book part for Message Integrity. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Message integrity is an often-overlooked problem for much the same reason that it is not generally recognized that the expression doctrine is dead. The technical ease of having an intelligent medium modify the message en route is not like anything in the past. Previous attention to message integrity has mostly been focused on the physical threats, because to modify a message required a physical change. This can be seen in the "locked briefcase handcuffed to a guard" model, which guards solely against physical attack. This is no longer the case, as messages can be both intercepted and changed without physical access. As tempting as it is to try to resort to physical metaphors, such an approach is as doomed to failure as it was in the expression case.
Throughout this chapter, the assumption is that the sender or the receiver does not consent to the changes made to the message, and thus that there is a third party involved in making the change. If both sides agree to a change, such as in the example of a newspaper digesting a press release instead of re-printing it directly, or informed consent to one of these technologies by both sender and receiver, then there is no issue.
Because of the difficulty of even conceptualizing non-physical integrity attacks under the past frameworks, it has been very difficult to explain the extreme danger such things pose. I know from personal experience that the metaphors alluded to previously are doomed, because they have never worked for me, despite a lot of time spent(/wasted) polishing them. The issue of message integrity is much more easily handled in the Concrete Part/Human Perception model.
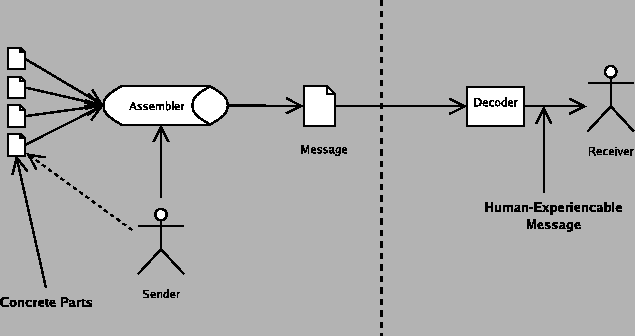 |
First, there are two aspects to message integrity, one pertaining to each side of the dividing line in the figure. The left side is very easy to deal with.
Communication Ethics book part for Concrete Message Integrity. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As mentioned in "Intention vs. Literal Speech", I do not want to get too deeply into the issues of determining whether the "sense" of a message is changed by some action, because therein lies an infinite quagmire of "mere philosophy". Fortunately in the case of concrete communication, especially when using computers, it's quite easy to determine if the concrete message has been changed between the sender and receiver. Simply answer the question "Did the bits change en route?" If yes, the message integrity has been violated. If no, it has not been. In the case of non-computer communication, you can still ask largely the same question by "virtually" digitizing the message and comparing what was sent to what was received, within reason. If the concrete parts are adequately contained in the final message, then everything is fine.
Example of "within reason": A person making a speech in an auditorium won't sound precisely the same to any two people, in the sense that a microphone would pick up a slightly different version of the speech. In this case, we do have to make the reasonable determination that the differences are irrelevant to the contents of the speech, or unavoidable due to the nature of the auditorium. It should not strain anyone's mental faculties to say that everyone is hearing the same speech, unless someone quite deliberately censors it somehow.
Hopefully you can see this is exactly what I defined as censorship, because changes in the concrete parts are the same as changing the message, so this topic is previously covered.
Communication Ethics book part for Human Perception Integrity. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The integrity of the human perception is much, much more difficult, yet correspondingly more important, because what really matters is what the human finally perceives, not the mere data that is delivered. How can we ever determine whether someone has disturbed a message?
Concrete parts are amenable to comparison before sending and after reception. Messages are significantly more fluid. As discussed elsewhere, a web page may be viewed in a virtually infinite number of ways, with different fonts, color schemes, or graphics handling. Even the sensory modality it is rendered into can change, with someone perhaps listening to a computer reading the web page, or reading it through a specialized Braille interface. At first, it would seem impossible to say whether a supposed modification is truly a modification, or merely another legitimate way of perceiving the message.
Yet even though there may be an effectively infinite number of ways of viewing my web page, and an effectively infinite number of ways of viewing the New York Time's homepage, it is immediately obvious that there is some real difference. The answer lies in the fact that the message is not independent of the concrete parts that went into making it. No matter what settings you set your browser to, my web page will never have the same content of the New York Time's page, because they have articles, advertisements, and other things that my web page simply does not have, and vice versa. It is this point that has been missed in previous debates on the Internet about the real-world examples of message integrity attacks, because it is easy to be blinded by the apparently infinite number of ways of experiencing a particular message. (This is another manifestation of the common misconception that any infinite set must contain all possibilities within it. This is obviously false; the set of "all integers" contains infinite numbers, yet no matter how long you look, you will never find 1.5. Similarly, even though there are an incredibly wide variety of experiencing a given web page, perhaps even infinite in some sense, the content the web page is based on always remains constant.)
Communication Ethics book part for Human Perception Integrity Defined. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is this recognition that allows us to formulate a rational and meaningful definition of the integrity of a human-perceived message, even in the light of infinite rendering variations.
- human-perceived message integrity
- When the message perceived by a human is composed of the same concrete parts, mixed as intended by the sender, the integrity is preserved. If parts have been added, removed, or modified, or rendering instructions have been added, removed, or modified, in ways not intended by the sender, then the message integrity is violated.
Again, we do not try to read the mind of the sender, but pay attention solely to the flow of concrete parts and their assembly. For instance, a novice web page creator may place an image tag in their HTML page and intend that every user see it. However, it is not this "intent" that is transmitted, instead it is an HTML image tag, <img src="/images/communicationEthics/something">. In HTML, the IMG tag does not truly mean "display this image", in the sense of an unbreakable contract. Instead, it is on the level of "strong suggestion to the browser", which it can take or leave as it wills, or as it is technically capable. Users may visit the web page with a graphical browser with image loading off, or with a text-only browser, or with an alternate-media browser with no visual component at all. All of these are acceptable under both the general understanding of the web, and even the technical specification of the HTML language:
The alt attribute specifies alternate text that is rendered when the image cannot be displayed (see below for information on how to specify alternate text ). User agents must render alternate text when they cannot support images, they cannot support a certain image type or when they are configured not to display images.
Emphasis mine.
In general, the actual message won't precisely match what the sender intends to convey, unless they are deliberately limiting their communication to the capabilities of whatever language they are using. In HTML, there isn't a way to say "The browser absolutely must display this image." The message can only match the sender's intent if the sender deliberately limits themselves to the limitations of HTML. The inability to truly express concepts completely correctly in any language is a deep philosophical problem, but such discussion does not gain us anything. The fact we can not narrowly and precisely define the intended "true message" does not mean that we must therefore deny it exists.
There is a lot of flexibility in how an HTML message is rendered. There is no flexibility in what set of concrete parts will go into a message. There is some set of images, text, applets, data, etc. that might be used to render the page, or might be elided by the browser. The set is finite and quite well defined with some simple analysis of the HTML page itself. Loading content from an additional source not described in an HTML page is a very distinct, identifiable event, and this constitutes an integrity breach.
Communication Ethics book part for Recognizing Integrity Violation: Delimiting Messages. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
There is one more issue to resolve before considering this discussion complete, though, and that is the issue of delimiting messages. Consider the case where a person creates a web page and "intends" for it to be viewed in Netscape. Now consider two people visiting that page, one with Netscape and one with Internet Explorer. One sees the page as "intended", with the Netscape logo on the browser. Another sees it with the Internet Explorer logo. It seems that a part of the message has been "modified", yet intuitively we do not see this as an attack on integrity.
Suppose now we use a browser that adds the word "WRONG" in huge red type to every third web page. This does seem to be an attack on the message's integrity. Many debaters I've seen on the Internet happily munge these two together in their zeal to prove their point, but intuitively, there does seem to be a real difference. What is it?
The rather straightforward answer lies in the dependence of the messages.
- dependence
- Message A depends on Message B if a change in B significantly affects how A is perceived by the human.
There is some fuzziness in the word "significantly", but that is just the real world rearing its ugly head at us again. In the case of a browser, it may draw a title from the current web page and use it in its title bar, or as the title of the bookmarks, so technically what web page it is currently viewing does affect how the browser is perceived by the human, but these are really rather insignificant changes under any reasonable interpretation. Practically speaking, the browser, considered as a human-experienced message, is independent of the human-experienced message of the current web page. As evidence, consider the visual similarity between a browser showing an empty page, and one with an actual page. Flipping it around, it is possible for the web page to affect the browser in certain limited, well-documented manners (such as opening a new window without toolbars), but again it is not really a case of "the web page" manipulating the browser, it is a case of the browser doing its best to render the web page as the HTML suggests. The user can override those manipulations either with certain browser settings, or by using a browser that doesn't understand those concepts.
One frequent counterargument to earlier, cruder versions of this concept is that it would outlaw such things as a television, which always have the name of the television manufacturer on it, thus affecting all television programs viewed on the set. Of course this does not happen because the name is completely independent of what is on the television, persisting even when the device is completely unpowered. Similarly, on-screen menus overlayed on top of television programs are harmless, because they are also almost completely independent of the television program, with the possible exception of displaying basic information about what is currently being viewed, which has already been discussed.
This is the answer to the problem of how to delimit the interactions of messages. If two messages co-exist, and do not depend on each other in the sense given above, then neither violate the integrity of the other, no matter how they came to be co-existent. Dependence analysis thus degrades gracefully in the pre-smart message case, when messages could never react to each other and thus could not become dependent, and shows that no messages were ever dependent on another message, so this is indeed a new ethical problem, one almost completely misunderstood by most people at this time.
Communication Ethics book part for Renderers Should Be Independent . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Earlier, I said the following:
No matter what settings you set your browser to, my web page will never have the same content of the New York Time's page...
Obviously, a special browser can be written that will show my homepage identically to the way it shows the New York Time's page. That does not negate my assertion, because such a browser is no longer an independent browser; it must be getting those New York Times concrete parts from somewhere, be it through accessing the New York Times website "behind the scenes" or through storing parts of the New York Times website in its own files. Either way, the important thing is that those parts are still not coming from my web site.
From this, we can derive an important rule of thumb: In general, a renderer should be independent of its content. This is how our intuition measures whether a given browser is "honestly" rendering a site. Considering that a renderer such as a web browser can stand between its user and thousands of other people, it is very important that the browser function independently, so the user is clearly aware of who is sending the messages.
Is this an abstract consideration? Of course not. While large scale manipulation by a browser manufacturer remains a hypothetical, a small-scale demonstration of the possibilities was provided by Opera in February, 2003 with the release of the "Bork" edition of their Opera browser. From their press release:
Two weeks ago it was revealed that Microsoft's MSN portal targeted Opera users, by purposely providing them with a broken page. As a reply to MSN's treatment of its users, Opera Software today released a very special Bork edition of its Opera 7 for Windows browser. The Bork edition behaves differently on one Web site: MSN. Users accessing the MSN site will see the page transformed into the language of the famous Swedish Chef from the Muppet Show: Bork, Bork, Bork!...
"Hergee berger snooger bork," says Mary Lambert, product line manager desktop, Opera Software. "This is a joke. However, we are trying to make an important point. The MSN site is sending Opera users what appear to be intentionally distorted pages. The Bork edition illustrates how browsers could also distort content, as the Bork edition does. The real point here is that the success of the Web depends on software and Web site developers behaving well and rising above corporate rivalry."
Or, in terms of this analysis, the success of the Web depends on web browsers remaining independent of web content. Opera's "Bork" edition functions by containing a special message internally that is executed only on the MSN site, which adds content to the site that does not exist on MSN servers. While this is a largely harmless release, made to underscore a point, it demonstrates that browsers have a great deal of power over the content they are rendering. This standard of "Independence" provides a usable metric to determine whether they are wielding that power responsibly or not.
Communication Ethics book part for Annotation. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the context of web pages, annotation refers to the practice of using some software program to leave notes on web pages that others using the same program can view. (Note that if only the author can view the notes, it doesn't matter.) Perhaps the most famous example of this is the now-defunct Third Voice, which no longer exists even as a website I can point you to, only the odd screen shot here and there.
 |
It is instructive to take a look at how Third Voice and related software accomplish this technically, because it is a paradigmatic example of how to effect large-scale integrity attacks. Despite the demise of Third Voice, other software still exists which has similar capabilities.
Communication Ethics book part for How Does Annotation Work Technically?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
 |
How the annotation author leaves a note on a given page, and how it is shown to the annotation viewer, worked like this:
- The annotation author would request a web page, let us say http://www.jerf.org for concreteness, from the web server. The browser would retrieve it normally.
- Once the browser was done retrieving the page normally, the annotation program, which was a plug-in to the browser and thus deeply integrated with the browser so it could detect things like when the page was done loading, would send a query off to the annotation server, asking if there are any notes for "http://www.jerf.org/ ".
- In this case, we'll say there wasn't any yet, so the server returns that there are no notes on that page yet.
- When the user decides to leave a note, he tells his annotation software where he wants to leave it, and what the title and contents should be.
- The annotation software reports to the annotation server the contents of the note and where to put it.
- When another user of the same program goes to http://www.jerf.org/ , their browser downloads the web page.
- Their annotation program asks the annotation server whether there are any notes on the page.
- This time, the server reports that there is a note on that page, and sends it to the annotation program, which then allows the user to browse it.
One consequence of this design is that only other users of the particular annotation software can see the annotations on that system. Different software systems can have entirely separate databases of annotations, and conceivably if this technology ever takes off, someone might build a "meta-annotation" software program that could hook into many different annotation databases. Another one is that the annotation server gets a complete log of the pages visited by the user.
div align='center'>
 |
The other major way that an annotation service can function is by using a proxy, which is a computer that acts on behalf of another computer. In this case, the proxy gets the web page for the requesting computer, and additionally adds the annotation information.
- The user asks the browser for a web page, http://www.jerf.org.
- The browser asks for that web page from the proxy.
- The proxy retrieves the web page from http://www.jerf.org , and adds the annotations to the HTML. The proxy returns this modified HTML to the browser.
- The browser displays the modified page.
Adding annotations is done by sending special requests through the browser, which the proxy server detects and processes to add the annotation into its internal database.
While very different technically (different bandwidth requirements, different bottlenecks in the system), the theoretical capabilities of the two techniques are identical. Some effects are easier in one model then the other, but there is nothing that is possible in one that is impossible in the other.
Communication Ethics book part for Why Annotate?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The justification for annotation was based on the observation that the web is largely controlled by corporations, as measured by the number of pages viewed, who have no mechanism for allowing feedback about the writing. (This was even more true in 2000 than it is now, with the proliferation of web-based forums, many even hosted directly by the big content producers.) Annotation was proposed as a solution to this problem, allowing people to metaphorically gather together on a web page and discuss the content. (The name "Third Voice" presumably comes from the idea that the web visitor is one "voice", the web page author a second voice, and the Third Voice program provided a third voice on the web page.)
Numerous examples of such things were proposed by Third Voice, such as criticizing products, posting reactions to news stories, or carrying on discussions about the contents of the page, but they all boil down to the same thing, discussing the content of the page.
Communication Ethics book part for So What’s Wrong?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Certainly those are noble goals, which is probably why the system was defended by so many people who meant well, including the program's authors. The problem is that by doing so, the defenders are opening the door to a subtle, insidious form of censorship.
One might consider granting a pass to these sorts of things because they appear on first glance to offer a way for "the little guy" to strike a blow against the corporate powers. But this is a dangerous illusion... because both practically and ethically, anything that the "little people" can do, the "big people" can do, too, only bigger and with a huge marketing push. In reality, all that is being created is the ability to slap arbitrary content into the middle of a web page, and if any of these services ever becomes large enough, it would be co-opted by the very same "corporate" voices is was created to provide a counterbalance to, in the end only making sure that not only do the corporations own their own spaces, but anybody else's they wish as well. This isn't just theory; see Smart Tags.
Communication Ethics book part for Annotation As Censorship. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Using the models we've built so far, it's easy to see how this is censorship. Analyzing the concrete parts that go into building the web page in the first Third Voice screenshot, there is the glaring intrusion of the comment from "shaina" that the author of the web page clearly did not intend. That is certainly content not coming from the author or even the reader, but from this "shaina" person. Without consent from both the web page reader and the web page author, such an addition clearly meets our definition of censorship.
This is not just academic. One of the most popular uses of Third Voice, measured by "pages with the most annotations" (Third Voice provided a little graph showing the "most active" pages on the web for some period of time, and while I obviously can't point to it, it allows me to know this was one of the most popular uses of the program; "Say No to Third Voice" monopolized the top position for a long time), was to visit the sites protesting Third Voice and attempt to "shout down" the protest sites through sheer volume of posted notes, sometimes so many that the browser would crash for some people. I'm almost sorry the program is shut down now, because you simply have to take my word for this: Even if you believe for a moment that Third Voice users would indeed use the service for the noble causes the creators claimed for it, a quick cruise around the system indicates that it was only rarely used for that, and you would quickly become disabused of the notion that it was being used for "debate". What little content on the service that was truly related to the page was almost entirely of the "shout-down censorship" type. Just as the readers have the Free Speech-based right to visit a web page, read it, and draw their own conclusions about the content, web page authors have the right to present their material without "interruption" from people, even if the reader desires that interruption.
Going even further, there is nothing special about "annotation". The symmetry of communication inevitably bites those who wish to make exceptions. If we try to make web annotation legal by dropping the requirement that the content author consent to the modification, then that applies equally to the annotations themselves. Many Third Voice users would have cried "Censorship!" if Third Voice started taking down notes for any reason other then community standards (and many certainly cried "Censorship!" when my techniques were used to prevent Third Voice from working on certain web pages), or even modifying them to suit their own purposes, but once you forfeit protection for the author, your own communication loses that protection as well. If anybody who has the technical ability can modify a web page by inserting content, then there's no way to limit that to just "annotation" or "good" uses; that means if somebody at AOL intercepts an email you send via their service and adds something to it "just because they can", there is no basis for complaint.
Perhaps the best way to look at this is to look at the Chain of Responsibility for the communication. For the original web page, only the original author of the web page is on it, since all other entities who are involved with transmitting the message do not affect it. When viewing a Third Voice "enhanced" web page, there's the web page author, the Third Voice company (who controls content via their centralized server), all the other people who used Third Voice to leave a note, and the user of the web page itself, because they installed and turned on the software.
One of the consequences of our right to free speech can be expressed as the right to control the chain of responsibility to the extent possible. Without the ability to deny others the ability to modify our messages we can not have confidence that what we are communicating is being expressed. The only possible ethical justification for Third Voice I saw given by its defenders is that a receiver has an ethical "right" to modify the page as they see fit. The reason this seems so plausible is that it is partially true; once the message has been received the recipient is free to do with it as they please in their own possession. But it is not completely true, because the recipient does not have the right to add other people to the chain of responsibility, allowing them to modify the message. Once the intended message of the author is altered or destroyed, the value of the web page to the author is also destroyed, and the end user does not have the ethical right to do that.
This is another way of looking at how the breaking of symmetry inevitably bites the very people who wish to benefit from it. Note that the end user does not have the power to insert the other entities onto the chain of responsibility. When two parties are involved, changes in the relationship require the consent of both parties; it's the same fundamental reason that when someone invites you over for dinner, it is impolite to invite somebody to come with you against the wishes of the dinner host, or when two people sign a contract, it takes the consent of both to change it. The wishes of the end user are not sufficient, so if we wish to claim that behavior is ethical, we must find some other basis to say that such external addition is ethical. But in the final analysis, the only basis that is even a candidate for that is mere technical ability to add other entities to the chain. Therefore, by opening the door to annotation we open the door to arbitrary content manipulation by anybody who has the technical ability. Annotation is merely a convenient term we give to certain types of content modification, but there is nothing fundamental about it; there are no sharp lines you can draw between it and more conventional content-based censorship of all kinds. In all cases, the ability of a sender to express themselves without interference from outside parties is irretrievably compromised.
In the long run, communication's value is directly connected to the reliability of the transmission of the information it contains. To allow messages to be arbitrarily degraded for a small short-term gain will inevitably make the system useless for all in the long term.
Communication Ethics book part for Follow The Effects. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
One last perspective on annotation from a technology point of view. One of the themes of this essay is follow the effects, not the technology. In this case, the effect of annotation technology is identical to what could happen if someone hacked into a web server, and installed software onto it that would cause it to provide annotation services to people who used it from that point on. That would literally change the contents of the server.
For people using the annotation programs, the effects are identical to the server serving out changed content. Yet nearly nobody would claim that this is legal or ethical. But this is really a contradiction; two things with exactly the same effect, yet one is ethical and one is not?
So, follow the effects. If it looks exactly like the content on the server is being modified, then treat it that way. If it looks like the server is being hacked to provide this service, then treat it that way. Otherwise, we open a loophole that will allow people to "hack" servers without hacking them, by riding the line between what even current law recognizes as illegal access and "allowed" annotation. For example, suppose I own a computer that a certain website uses as its connection to the Internet, so all packets that computer sends must go through my machine. Suppose I configure this machine to dynamically add a nasty picture to that machine's home page every time someone accesses it from the Internet. This looks exactly like somebody hacked the machine to include that nasty picture, yet it's all done by hardware I legally own, and if we're to allow arbitrary additions to the chain of responsibility, you are left with no real way to call the action unethical communication behavior. Yet we would certainly all feel this is highly unethical.
It is a testament to the consistency of the model we have built so far that three different ways of looking at the issue (as censorship, as insertion onto the chain of responsibility, and from the perspective of effects) all have the same result: Annotation should not be allowed.
Communication Ethics book part for No Annotation. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the end, the only workable way to allow free speech is to forbid anybody from altering the message between the sender or the receiver. Otherwise, nobody will be able to reliably transmit messages without assurances that the sense has been completely altered, even if we only allow "additions", even if we require those additions to be clearly labelled.
And why would we want to allow it, anyhow? For all those objections above, for all the problems it causes, including the fact it would eventually be co-opted by the companies themselves (see "Smart Tags"), it doesn't actually solve anything. For all the speech it throws away, it does not enable any speech that people did not already have the ability to do. You can already complain about a company. You can already discuss products. You can already post reactions to news stories.
The only reason annotation is even interesting is that it adds the content "directly to the page itself". But this is not sufficient to counterbalance annotation's costs. The reality is that while you have the right to speak, and the right to listen, you do not have the right to be heard. If nobody choses to listen to you, that does not give you the right to start defacing the speech of others. You have no claim on somebody else's web page, only your own.
The solution to the annotation problem is, mercifully, the one that seems to be winning on the Internet: Give people their own spaces, and let them say what they like. The purest incarnation of this is found in the proliferation of weblogs. Protect these spaces, and everybody can say their piece with confidence that the messages they post will be reliably transmitted to their receivers. This, not an anarchy where anybody can fiddle with a message, is the true path to free speech.
Communication Ethics book part for Other Integrity Attacks. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Annotation is probably the most interesting and perhaps the most direct attack on message integrity we've seen so far, but it is not alone. We need to make this entire class of activities illegal before one of them manages to become deeply entrenched.
Communication Ethics book part for Smart Tags. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Smart Tags are a Microsoft technology that can automatically turn words into link-like entities on HTML pages, without the web page author's consent or even knowledge, and potentially without the viewer's consent or knowledge. (In the proposed implementation from Microsoft, the user could shut off the Smart Tags if they like, but they were on by default. A certain large percentage of users would never know they could be turned off, or even what they were, so for many people the effect would be that they were on without even their knowledge.) For instance, if the word "Ford" appeared on the page, it might add a link to the Ford homepage, or a page with information about Ford stock, or anything else Microsoft thinks might be a good idea... even if the word was used in the context of "fording a river".
The definitive article on Smart Tags is probably from A List Apart. Note the parallel between the Microsoft's quote and the arguments in favor of annotation, framing them in terms of "user empowerment" to the exclusion of "author empowerment", as if there was a meaningful distinction between "users" and "authors".
This isn't quite annotation, but it's about as close as you can get without actually doing it, and it does demonstrate how large companies will swiftly co-opt that sort of technology if given the chance, and turn it into anything but a way for the little guy to "strike back". The technology is very similar to Third Voice, though a little more sophisticated and flexible (more then one central server, more flexible client manipulations). Adding new "Smart Tags" is limited to developers, since it would require programming, which practically means it is limited to companies since most "normal users" aren't programmers. "Smart Tags" were going to be used for the very things Third Voice was supposed to counterattack.
"Smart Tags" do nothing for the users that they could not already do for themselves; if one is reading about greyhound dogs and suddenly has the urge to look up the stock value of the Greyhound Lines, Inc., they can do it for themselves plenty easily without assistance.
Communication Ethics book part for Advertisement Blocking. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As advertisements become ever more annoying on the web, people are developing ways to fight back against the intrusion. Exactly how they do so brings up some subtle issues in how ethical that is, because there are several types of techniques with different ethical implications.
Browser-based blocking
Browser-based blocking is probably the easiest blocking technique there is, and if you didn't know about this before, consider this your reward for slogging through the essay this far. In the latest versions of Mozilla and derivatives, there are simple options to prevent pop-up windows for appearing. For instance, in Mozilla 1.3, going to Edit->Preferences, opening the Privacy and Security tab, and clicking on the Popup Windows text, will show a dialog that allows you to turn off pop-up windows. It's really nice in 1.3 and above because you can enter exceptions, if you have certain sites which require pop-ups to work correctly but you trust them to use pop-ups in a manner you approve of. In addition, in the Images section (just above "Popup Windows"), you can tell images not to animate, which for the most part only affects advertisements. And finally, if you open the Advanced list and click on Scripts & Plugins you can disable a whole raft of "features" used mostly to annoy the user.
I personally recommend using Mozilla and activating these features, and leaving Internet Explorer only for things that absolute require it. Generally, after taking these steps the annoyance at the advertisements subsides enough that you don't feel the need to do the more extreme things I'm about to discuss.
Two interesting things about this: First, not all browsers even support the idea of opening new windows in the first place, so it can't be that big a deal to tell your browser not to open new windows. Second, everything I mentioned is solely under the users control, and none of these things depend on the content of the web page. All animating images will not animate, without regard to whether it's an advertisement or who created it. No pop-up windows open, unless they are from an approved site, without regard for what they will contain. These features are independent of the content. They happen to mostly affect advertisements but that's a consequence of the fact that mostly advertisers (ab)use these features. None of these settings do anything to block the simple, pure-text ads that Google.com uses, for instance, showing they are not directly targeting advertising.
Based on that analysis, there's certainly nothing wrong with configuring your browser like this, because as we've mentioned earlier, web pages are not unbreakable contracts to display certain things in certain ways, they are loose instructions for assembling images on the screen to the browser, and the browser and the browser user are free within the parameters of those instructions to render the content in many ways.
Some people are developing technologies that try to detect when the user is blocking popups and not allow them to proceed without viewing the ads. It is probably not ethical then to bypass these checks, as the content owner is clearly making access contingent on the ad viewing, which is within their rights. It's probably not a good idea to annoy a consumer that devoted to dodging ads, though, and it's unlikely the contents of the ad will leave such people with a favorable impression, so hopefully the open market will realize this and an arms race will not be necessary.
Filtering Proxies
The most sophisticated ad-blocking solutions are filtering proxies. The proxy works as in the proxy-based annotator, but instead of adding information, it takes it away.
An example of such a program is The Internet JunkBuster Proxy(TM), which can block certain URLs (including that of advertising images), and prevents certain information from being transmitted to web servers that most browsers send by default, such as cookie information. As seen in the annotation example, a proxy server can transform content in nearly any imaginable fashion, so the mature ones such as The Internet JunkBuster Proxy(TM) are very flexible and powerful.
Used as a tool by a single user, again I don't see any significant problem with such software, again because the "contract" of the web is not that the user must see all content precisely as intended by the author. A single user adding sites to his filtering proxy is similar to simply refusing to visit those sites, which it is in the power of the receiver to do. Some browsers, such as the variants on Mozilla, even build this into the browser; by right-clicking on an image you can tell the browser to stop loading images from that server.
There is an obvious scaling problem with this, though, in that advertising sites are popping up faster then a user can smack them down, and there is obviously a lot of redundancy in what each user does, as many of them choose to block the same sites. It seems like it would be a good idea to create a tool with a centralized list of bad sites, let users update it dynamically, and distribute software that checks the centralized database for what should be blocked. One piece of software that does this is Guidescope.
Unfortunately, this crosses the same line that annotation software does, by allowing third parties to influence the communication without the permission of the sender. It seems like it would be nice if we could salvage the ability to use this ethically, but that's an artifact of considering only the receiver's point of view. In the larger context, this must be considered a form of censorship and the limited benefits to certain people do not justify how dangerous it is to open the doors to censorship... even if you are yourself one who would benefit. Acting ethically is not always pleasant in the short term.
Using a filtering proxy as a tool is acceptable, until the proxy is using input that did not come directly from the user. This also implies that while it's OK to distribute the proxy server, the list that it uses to block sites with should start out empty so that only the user's input is used by the program.
Practically speaking, I find that using Mozilla and blocking popups and animating images, and optionally telling Mozilla to be conservative about what cookies it accepts, takes care of the majority of the problem with privacy and annoying advertisements without the use of unethical group censorship programs, so once again the benefits of such a scheme are quite marginal compared with the real damage to free speech (even commercial free speech) such programs do.
Communication Ethics book part for Spam Filtering via Blocking Lists. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Almost completely analogous to how advertisement-filtering proxies can download a list of sites to filter out, a mail server on the Internet can download a list of sites to ignore the mail from. Many such lists exist, one of the most famous being the Realtime Blackhole List, created and distributed by the MAPS (Mail Abuse Prevention System).
Such lists have been used for censorship, deliberately and otherwise, many times already. For instance, see MAPS RBL is Now Censorware. Even if you ignore for a moment whether the precise allegations in that article are true, it is true that the power to arbitrarily block communication for large numbers of people is given to these blocking list maintainers. The point is not that it is bad the power was misused, the point is they should not have this power at all. Spams cost the receiver money, but that still does not justify censorship as a solution to that problem. Instead, other techniques should be pursued.
Once again, the benefits of this scheme are marginal, compared to the significant costs. Not only are these blocking lists not working, there are better solutions that are also perfectly ethical. We are not handed a choice between discarding our ethics or living with spam, we simply must use solutions that do not involve third-party communications not consented to by the sender.
Such solutions include, but are not limited to:
- white lists: Lists of known good addresses that you filter into a special "good" mailbox. This would solve the spam problem almost completely for the large number of people who use email to communication with a relatively small number of people or email lists.
- challenge-response: Whenever an email comes from a new sender, a challenge email is sent back requiring the sender to authenticate themselves, either by simply responding or potentially through more complicated means. Unanswered challenges result in the email being discarded.
- requiring payment: A small fee could be charged for sending email, which could be optionally remitted if the receiver likes the email. It could be small enough to not bother anyone, yet make it prohibitive to spam millions of addresses at a time.
- authenticating the sender: We could require people to digitally sign their email, which uniquely ties the email to a secret key which the user can then choose to accept emails from. Sophisticated variants on this scheme could not only eliminate spam but also allow users to decide how much they can trust certain senders.
- things nobody has come up with yet: Who knows when a great solution will come along?
None of these solutions require third-party influence on message reception. The only unethical solution to the spam problem is blocking lists, which also happens to be worse then all the solutions on that list. (Why are we using it then, you ask? Because it's also the easiest to implement.) Ethics need not tie our hands.
Communication Ethics book part for Automated Movie Censoring. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In early 2003, a debate over a technology called ClearPlay arose (also this discussion). ClearPlay is a movie technology that takes a DVD movie and a data file from the ClearPlay service that describes how to play the movie, and will selectively censor the movie in accordance with those directions. ClearPlay is designed to clean movies up to the standards of its customers, removing nudity, violence, profanity, etc. and thus allowing these movies to be viewed in a family setting, where such things may be considered inappropriate.
Hollywood objects to this, such as is seen in this quote from USA Today:
"Artistically, we're offended by an arbitrary outsider deciding how you should see a film," says Martha Coolidge, president of the Directors Guild of America and director of such movies as Rambling Rose and Introducing Dorothy Dandridge.
I'm long overdue to finally say this: Hollywood is right. A parent is free to take a film and clean it up themselves, for viewing by their children (who legally are an extension of the parent), but when content from a third party, in this case ClearPlay, is included, that is the bad kind of censorship without permission from the original owner.
Unlike the other examples mentioned so far where the gain is negligible, there is a small loss of capabilities here in the case where even parents would like to see a movie, but without the profanity. This small loss does not justify the costs of allowing this sort of manipulation, however.
The theoretical ideal would be for ClearPlay to license the movies, make their changes, and sell the resulting movies, with some reasonable fee going back to Hollywood, so everybody wins. While Hollywood is theoretically within their rights to shut this down without debate, one does have to question how committed to this sort of integrity they really are, when they are perfectly willing to censor their movies to run them on television. Still, just as it is my choice about how to distribute this essay, it is a movie owner's choice about how to distribute their movie.
In 2003 the Electronic Frontier Foundation came out in favor of this, demonstrating how hard it can be to recognize censorship if you aren't careful about understanding what's going on.
Communication Ethics book part for Others. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I'm not going out of my way to make an exhaustive listing of these things, so I've probably missed some currently existing systems that do this. And certainly until we come to a clearer understanding of the boundaries as a society, more people are going to have more bright ideas for this sort of censorship that seems to solve some short-term problem, while remaining blind to the long term disaster allowing such things will cause. I would be willing to bet money that within a year of the "publication" of this essay, to the extent this is "published", at least one more system will be proposed based around this idea. When it does, I hope you can recognize it.
Communication Ethics book part for The ``Patch’’ Hole. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
What all of these things have in common is that on some level, they are applying "patches" to a message.
Communication Ethics book part for What Is A Patch?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
A "patch" is a technical term in the computing industry that most closely matches this concept, of all the terms I am aware of. A "patch" represents the differences between two files. For instance, if I have a file that contains "This is a dog." and a file "This is a cat.", the difference is the word "dog" in the first and "cat" in the second. A patch file describes how to start with one file and get to the other.
Patch files are usually written for computers, but they are generally very easy for a skilled programmers to read. Since it would not be very useful for you to know how to read them if you don't already know how, I'll simply discuss them in terms of English instructions. Patch files can be considered as instructions being fed to a proper interpreter, so re-expressing them as another set of instructions doesn't lose anything significant in the translation.
A patch from the first sentence I mentioned above to the second sentence might read as "Remove 'This is a dog.', and insert 'This is a cat.'." That correctly describes how to get from one sentence to the other, but there are two problems with that. One is that it contains all of both files within it, which is a waste of space. The second problem is that there is a much more efficient way to obtain the same effect: A patch file that says "Remove the word 'dog' and replace it with 'cat'." Now the patch is very space-efficient (especially in computer terms, where that entire sentence might boil down to just "s/dog/cat/" or some equally cryptic, but precise, formulation), and it also does a good job of highlighting the differences without repeating the similarities, which can be useful to human readers.
There are no particular limitations on the capabilities of a patch. As the two messages become increasingly dissimilar, the patch grows in size, until eventually it simply contains both files (the negative of the source file and the positive of the destination file, if you want to think of it that way; the photographic analogy is reasonably accurate), but the differences between any two messages can be expressed as a patch. Even the differences between two human-experienced messages can be expressed by a patch, in a sufficiently powerful patching language.
"Annotation" works by patching the incoming web page to include the annotations in it. In the Third Voice implementation of annotation, you could even watch the patching happen, as the annotation markers trickled in and caused the page to be re-formatted. "Smart Tags" work by patching the web page to include new, special links that weren't in the original page. ClearPlay patches selected parts of the movie entirely out of existence; spam filtering patches entire messages out of existence. (The equivalent in terms of the sentence examples above would be "Replace 'This is a dog.' with nothing.") Advertising blocking uses all of these techniques, depending on which implementation you chose.
Communication Ethics book part for Complete Power Over Messages. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Any single one of those things may seem harmless... "How can it be bad to add annotations to a web page?" The problem is that there are no technical limits to what patching can do. On a technical level, once you grant a third party patcher access to a message, they have complete control over it. They can change it to anything they please, with or without notifying the sender or the receiver of exactly what they are doing. (In the receiver-initiated cases, the patcher tells the receiver something about what they are doing, but there is no way for the receiver to be certain that the patcher is telling the whole truth, except through trust. To be fair, this is true of any software program.)
It is never a matter of "just adding annotation" or "just censoring certain scenes" or "just blocking advertisements". A patcher may claim that they are exercising restraint but at any time that restraint can end.
It is entirely unethical to ask a sender to send a message under those conditions. The value of the communication to the sender extends only so far as they have sufficient control over the message to do their best to ensure that their message expresses what they want it to express. When a third-party patcher is invited into the transaction against the sender's will, no matter what the patcher claims to be doing or even what the patcher actually is doing, the message ceases to be under the senders control and it becomes the patcher's message.
How can I claim it's actually becomes the patcher's message when it (usually) looks so much like the original message? Well, ask yourself who has control over the contents. For the purposes of concreteness let us talk about proxy-based annotation in particular for a moment, though the principle trivially extends to all other instances of patching. Support the web page author decides to add something to the page. Who controls whether that gets to the receiver if the receiver requests the page again? The proxy server can completely mask the new change out, in such a way that the receiver never notices. On the other hand, the author exerts no control over the proxy whatsoever; the author is probably not even aware of the proxy's existence. If the change gets through to the receiver, it is because the proxy graciously allowed the change through, not because the author made the change. There is nothing the author can do that the proxy can not veto, while the author has no say in what the proxy does.
Again, follow the effects. The patcher can effectively make any change they want. The patcher effectively has full control, even to explicitly contradict the author's wish. Therefore, the logical conclusion is that they do have full control. In terms of the effects, a patching system is equivalent from the receiver's point of view to the patcher actually changing the source code of the original message. If they actually did that in the real world, if ClearPlay actually went and modified the actual movie, if annotation servers actually hacked into web servers and changed the code for the page, if spam blocking programs actually hacked into other's computers and broke the mail sending facilities (and remember that very little spam comes directly from spammers nowadays, they relay from other people so you'd be hitting innocent victims, as tempting as such a drastic solution might sound), we would instantly know that something unethical has been done.
This is the "patch hole", a hole not just in the law but in our understanding of the world. Where we should see one unified effect, we see two sources and some technology for combination. We allow ourselves to be distracted by irrelevant technology behind the scenes and allow the technology to obscure the fact that accomplished in another manner (direct modification of the original source material) the action is obviously unethical.
Each of these patch-based technologies seems so innocent on first glance, but taken together, and taken to their logical conclusion, it paints the picture of a world where nobody can every have any assurance that a received message bears any resemblance to what they meant to say.
In each instance, there is a better way, or it's simply better not to do it. Any information a patch is adding can be communicated by other means; one need not mark up a web page to discuss the contents, one can go online to any number of bulletin boards dedicated to the task of communicating for that. Any patch that removes information, such as ClearPlay's product, should either simply not be done since removing information is a violent act that does unquantifiable and unqualifiable damage to a message, damage that nobody is fit to judge, or should be done with the explicit cooperation of the sender. Even if you aren't quite willing to believe right now that the costs are as high as I say they are, I hope you'll agree that the benefits are still so marginal and of such low quality compared to better solutions as to not be worth it.
Communication Ethics book part for Patching In Terms Of The Communication Model. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Like "censorship" and "privacy", it's best to finally produce a concrete definition that we can use as a yardstick to tell whether or not someone is doing something unethical. Let's clearly lay down the criterion for what constitutes "unethical patching" so we can recognize it when we see it.
- unethical patching
- a message from a sender to a receiver is modified by the receiver in accordance with a message from a third party in such a way that the human-experienced message automatically depends on the third-party message (as "dependence" is defined previously), without the consent of both the sender and the receiver, then the act of modifying the message is unethical patching.
This definition is actually quite elegant, because of the way it is based on the earlier definition of "depends". If there is no change at all to the human-experienced message, then there is no patch, whatever technical stuff may have been going on behind the scene. (Translation: It is actually OK to use an annotation service if you go to a webpage that has no annotations. Pointless, but ethical.) If the change is "independent", then there is no problem. (Translation: It's even OK for the annotation service to provide a console on the screen for controlling the service, as long as it is independent of the web page; the ones I've seen are.) Once the human-experienced message changes in a way that depends on the third-party content, the line has been crossed. The simplicity of the definition is the source of it's power; something so simple can not be danced around by hiding in a corner; either there are concrete parts intruding from a third party or there are not. This is an advantage held by this definition over every other ad-hoc attempt to justify annotation, but not changing the web page... or changing the web page by adding Smart Tags, but not changing the actual "words"... or justifying ClearPlay while standing against other things in this chapter... or even trying to justify all of these things while still pretending that the result isn't simple anarchy, with the corresponding loss of free speech.
There are things that this definition explicitly does not cover. Note that "unethical patching" includes the concept of "dependence", so things that are independent of the message are still OK. For example, there are several toolbars you can download that will allow you to easily get a list of web page that link to the one you are currently reading. These links are independent of the message, so adding this information in an independent way would not constitute unethical patching. Such functionality is not "unethical patching".
The line starts to get fuzzy here; consider web pages. Alexa's tool bar shows the links in what is clearly a separate window not belonging to a web page. crit.org, in addition to providing annotation services also provides a back-link service, but puts the information in the web page itself (which it can do because it functions as a proxy server). (As of this writing, it seems crit.org may have been unplugged.) So it's possible that even the same information in different places could affect how the original message is perceived and thus violate the independence of the original message. I personally would draw the line between Alexa and crit.org, saying that the information should not appear to belong on the web page, but I think it's much more important to understand that dependent content is bad then argue about exactly where independent content should go to make it clear it's independent, which will be strongly medium-dependent and even message-dependent anyhow.
The implied definition of "independent content" here would be "content that it is at least possible to present in a fashion preserving the independence of the original message". Backlinks can be shown in an independent manner; annotations can not, because by their very nature they depend on the annotation target for context.
Also note the word automatically. It's a critical word in the definition. Suppose you are running a advertisement-filtering web proxy and a friend emails you and comments that www.WeWishWeCouldPutAdvertisementsOnTheInsideOfYourEyelids.com is serving a lot of ads. You can still manually add that domain to your blocking list, because there's nothing "automatic" about that addition. "Automatic" here means that the control over the results lies not in the hands of the receiver, but in some third party. Adding a single domain to the proxy, and thereby blocking content from that domain, is clearly an action of the proxy owner. On the other extreme, a proxy that automatically downloads updates every hour from some centralized server not under the proxy owner's control is giving the control to that central server owner.
Of course there is no way to easily draw a line that completely delimits how much control is given to a third party and how much is given to the receiver. You could sit all day and spin borderline scenarios... "What if the user has to individually agree to each annotation?" "What if we make the user do something like copy & paste the annotations into the web page?" "What if the user has to type the annotation before viewing it?" While there may be a thin boundary condition, what it boils down to is pretty simple: you can't allow someone else direct access to the message, to change it in any way. The message is between you and the sender. The key is the level of involvement you have with the decision.
Determining who is responsible for the unethical behavior depends on exactly who is doing what; the patcher may doing it against both the will of the sender and the receiver (perhaps it's government censorship), in which case it's the patcher's responsibility. Or the receiver may be doing something with the received message and using information from a third party without the third party's knowledge, such as in the case of framing, in which case it's the receiver's responsibility. The receiver and the third party may be cooperating, like annotation. It is not likely that the author is responsible, since in such cases the activity of the third party would then simply become part of the message; for instance, many large web sites outsource their advertising to a large advertising company, who will add images to the company's pages. However, this is intentionally part of the message the company wishes to send, so that isn't really a "third party". Accepting any third party the author invites essentially becomes one of the conditions of communication. Remember that since everybody is a sender at some point there's nothing asymmetrical about this; when it comes time for the current receiver to send a message they are equally free to impose such conditions.
Communication Ethics book part for Example: The GPL. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Another aspect of "the patch hole" is that by allowing such things you effectively preclude certain very legitimate forms of protection.
Consider the GNU GPL. The "GNU General Public License" is a "copyleft" license, designed to be applied to software source code. Summed up very succinctly, the GNU GPL (usually referred to just as the GPL) allows you to take GPL-licensed code and do nearly anything you want to it, including change it and further distribute it, except you must distribute copies of the modified source code to anyone who asks for it whom you have distributed the program to, and the source code must remain itself licensed under the GPL. In essence, this allows for the creation of a common pool of code that is Free, and must remain Free, preventing anyone from swooping in, grabbing some code, making a lot of proprietary changes to it, and profiting thereby without sharing the changes back to the community who created the foundation in the first place. For more information, please see the GPL FAQ.
The GPL is an unusual use of the copyright system, but a very legitimate one, and while many have questioned its validity, it is difficult (and some would say "impossible") to formulate an objection to the license that would not apply equally to all copyright-based licenses. Unlike many copyright-based licenses that restrict your rights, the GPL focuses on guaranteeing certain rights, subject to agreement to its conditions.
The Linux Kernel, the very core of Linux itself, is protected under the GPL. Now, suppose Microsoft decides to distribute a Linux kernel. Under the terms of the GPL, Microsoft can do so, but must provide the source code to the changes to anyone who has a copy of their changed kernel. This doesn't fit into their strategy, so they seek to bypass this requirement. Instead of creating a single file that contains the changed kernel directly, they compile a "clean" version of the kernel. They then make their changes, and compile a version of the kernel containing their changes. They then create a patch that converts the clean kernel to their changed kernel.
Suppose Microsoft now distributes this clean kernel and the patch. (In other words, they never directly distribute the modified kernel.) In the process of installing the Microsoft product, the installation program dynamically combines the pristine kernel and the patch on the user's system to produce a copy of the Microsoft modified kernel. With sufficiently clever programming, the system can even do this in such a way that an actual copy of the modified kernel never actually exists anywhere all at once, only bits and pieces of it.
Linux hackers notice the inclusion of the Linux code and triumphantly demand that Microsoft distribute their source to the kernel. Microsoft does so by sending out a copy of the "pristine" kernel source, straight from the original kernel.org source code, declare they never distributed the modified kernel and are therefore not required to distribute the changes. Voila; one inconvenient license, patched around.
When you allow people to patch with "clean hands", you destroy all derivation-based protections afforded under traditional copyright, and still valid for concrete parts. Any derived work can be expressed as the original work(s) plus a patch. This destroys the GPL, many clauses of many software licenses, and a wide variety of established protections for messages of all kinds.
"Patching" is not an ethically neutral event. Follow the effects. Patching is effectively the same as distributing the final product.
Communication Ethics book part for Integrity of Messages as Derivation Trees. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Recall that in Expression and Derivation Tree Equivalence, we observed that expressions are their derivation trees. The same is true of messages, they are their derivation trees, it's just that messages may have much more complicated relationships then traditional expressions. In fact, it was an exploration of those more complicated relationships that first convinced me that the expression doctrine is not useful for understanding the current communication world.
This chapter's thesis is a somewhat subtle argument, so let me re-cast it in terms of derivation trees and quickly run through the argument in terms of derivation trees, with the advantage that I get to use pretty pictures that way. First, we need to make two simple observations:
Communication Ethics book part for Observation 1: All Human-Experienced Messages consist solely of Concrete Parts. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The difference between "expression" and "message" is mostly that a "message" can lead a much more dynamic life. Many modern, dynamic messages are only useful in relation to other messages. For instance, "the homepage of CNN", in the most pure sense, is really "a program that assembles the latest news and a list of links to CNN's other web services and shows it to the user", not the specific HTML you receive when your browser retrieves "http://www.cnn.com/". That specific HTML page may never be seen again, but the description based on what the homepage program does is always true, regardless of the news.
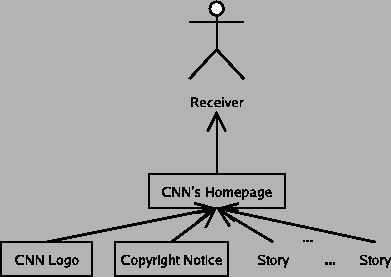 |
Thus, the best representation of "the home page of CNN" is as seen above. There's this program, that draws from variable input, and produces a web page as output.
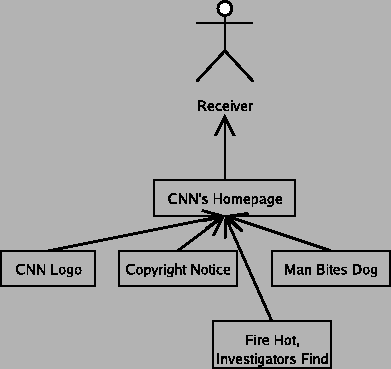 |
But in the end, a given human-experienced message must be entirely concrete. You can not directly "experience" CNN's homepage without actual content. (The closest you can come is that you can examine the source code of the "home page program", but that's not the same.) Until all of the arrows are actually coming from something concrete, you can't experience the abstract page. You can only experience something as in the prior figure.
Communication Ethics book part for Observation Two: The ``Sender’’ is Always On Top. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The way I'm drawing these diagrams, the sender is always on top. Why is that? Because of the dynamism of messages, as demonstrated by annotation and composition and all of that other stuff we see in the real world, it is obvious that no matter what concrete parts go into making up the message, the person who has the final say has full control over the message; they choose whether to bring two things together, or mask something out, or replace this with that, or what have you. That entity has the power, and therefore the responsibility, of being the sender.
The complementary statement is also true, effectively by definition. The entity that has the final power to change the message is the one that belongs on top, as near the receiver as possible. Of all the entities who may be involved in a given message, that is that one, the only one that makes sense to represent as interacting with the receiver.
This is why earlier when I modelled this essay as a real published book, it is the publisher who is the sender. Intuitively, it may seem like the author is the sender, but it is not the author who has final authority over what is in the book. It is the publisher, who has contracted with the author for the rights to use the book in the publisher's complete message, which will include the text of the book itself, but also additional content, such as a cover and advertisements in the back. If the publisher decides to simply not print pages 26 and 27, then the author can not truly stop them. Thus, it only makes sense to call the publisher the sender; they enjoy privileges that no other entity does, or even can. Being a sender is a meaningful privilege and responsibility.
In summation, an entity is the sender of exactly that content which they can change and nobody else can override that change. Any other definition of sender will result in situations where the putative "sender" is responsible for something they can't change, or situations where the sender can change things they are not responsible for, both ethically repugnant.
Communication Ethics book part for Representing Integrity . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
 |
 |
Reducing the equation down to the Receiver, the Original Content, and the Annotations (encapsulating the rest of the details), the question is which diagram more accurately captures the spirit of the situation.
Obviously, an annotation defender would claim the first diagram is more correct. The annotations are separate from the original content, at no time are they truly "mixed", and the receiver is just choosing to use a program that happens to allow them to view both the annotations and the annotation target at the same time. The final viewed page with the annotation content is not a "derivative message", it's just two things being displayed simultaneously.
This argument falls down in many ways, any one of which is fatal.
- The annotation program and the annotators have full control over the annotated web page. By the previous discussion about senders, that means the annotation provider is the sender of a combined communication, since the annotation vendor can unilaterally make changes to the original web page, and the original web page owner can do nothing about it. Therefore the annotations do constitute a change to the message and the original sender does have the power to object to that.
- Having two communications, and two senders, implies that the two communications are independent, in the sense that a change to one should not affect the other. But that is not true, in either direction. A change in the annotations appears as a difference on the original content. A change in the original content has the power to completely shift the context of the annotation comments, or, depending on the technical implementation, "orphan" the annotations (by removing the text the annotation is anchored to). The first figure completely fails to capture this fact, and as such is not the correct way of looking at things.
- Perhaps most damning of all, the diagram does not capture our intuition of what is taking place. The annotations are intimately related to the web page, or they wouldn't be annotations. Trying to understand them as separate is a disingenuous attempt to justify something that can't be justified. (Many annotation supporters find themselves straddling this fence: On the one side, they defend annotation as being independent and totally unrelated to the original content, and therefore not constituting a derivative product. On the other side, they promote annotation in the first place as a way of commenting directly on the original content, because the very attraction of annotation is that it is directly based on the original content. Consciously or unconsciously, they find themselves dancing between these two propositions.)
The reality is that the second figure is far more accurate.
The other major argument can be summed up as a diagram as above. Translated roughly into English, this is the "Annotation as overlay" argument; that an annotation is just an overlay placed on top of other webpages and as such does not truly affect them. The problem with this argument is that it is only true in the abstract. Without mixing in the original web page, the annotations, well, aren't annotation at all, they're just posts on a message board somewhere. This argument runs smack into the fact that all human-experienced messages must consist solely of concrete parts. The act of "overlaying" is not an ethically neutral act, it can damage the concrete message it is overlaying, and annotation (and other integrity attacks) require the overlaying in order to be annotations at all.
The root of this disconnect is that people making the "annotation as overlay" argument are implicitly defending their right to comment on things, and believe the annotations themselves are being attacked. This is not true; it is the act of overlaying that is being attacked. Your "annotations" are free to exist as message board postings on another site, or as commentary on television, or whatever other independent message you care to use to comment on my message, but as soon as you "concretize" this abstract overlay by using my content as the "...", you have stepped over the line and created a derivative of my original message, no matter how cleverly you try to use technology to obfuscate the act of creating the derivative product.
Communication Ethics book part for Applications And Examples. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Applications and examples of the principles so far explored, to make sure we all understand what I'm saying:
Communication Ethics book part for TiVo: Tools vs. Content.. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
TiVo is the most well-known "Personal Video Recorder" (PVR). It "knows" when television shows are going to be on, and can record them for you according to a variety of conditions you can give it. Since it records to a hard drive, you can then later watch these shows however you wish, whenever you wish, jumping around them, fast forwarding, rewinding, or skipping back with impunity. It also provides the same services for up to 30 minutes of Live TV. I highly recommend owning one if you like TV at all, or if you "don't like TV" but find that you sometimes like certain programs either. (I don't know that there are very many people who "like TV" as in "liking the vast majority of programs they see"; I'd suspect nearly all of us only like single-digit percentages at best.)
The television industry has mixed opinions about the whole thing; on the one hand it vastly increases the value of their offering with no particular effort on their part. On the other hand it allows consumers to skip commercials, and it seems some television executives believed that there was an unbreakable contract between the television producers and consumers that the consumers must watch the commercials. Apparently these executives don't watch TV much themselves, or they'd know about the invention of the Mute Button, along with Channel Surfing, Using the Bathroom, Getting a Snack, and of course just plain Ignoring the Commercials, along with the wide variety of other ways people have found to not watch commercials on television.
Interestingly, and perhaps to the television executive's chagrin, none of this message integrity analysis affects TiVo. TiVo is just a tool that does as you say, it contains very little content of its own (and that content is correctly independent of the television shows). Skipping around and such under control of the user are perfectly valid uses of the message. While television executives may prefer that you watch a television program straight through, they really have no grounds to make that demand.
If TiVo tried to send a programmed sequence of commands to your machine so that you could, say, skip over commercials automatically, that would be over the line, because that would be sending a patch to remove commercials from the television show using a TiVo, patches very dependent on the exact show being shown. The current TiVo is fine, though, and is just another example of how the receiver will continue to be empowered by technology.
ReplayTV provides a great borderline case. ReplayTV is another PVR, one that tried to ship just such an automatic commercial skipping algorithm. This automated commercial skip, which is also a feature in at least some VCRs (my parents have one) is technically not accomplished by sending patches through to the user, especially in the case of the VCR which is not connected to anything. In the end, though, it's equivalent to such a patch and is basically a smart filter, and is probably a textbook case of being just barely over the line. As such, it was ethically correct to "a href="http://www.wired.com/news/business/0,1367,58957,00.html">remove it from the product. (Though that does bring up the question of how ethical it is to remove a paid-for feature from a product after the owner buys it.)
Communication Ethics book part for But What About… . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I've been thinking about this and debating these issues for a while. I see the same counterarguments over and over again, but the problem is not that they are wrong, it's that they simply don't apply. As usual, they boil down to bad physical metaphors being applied in a domain where our physical intuition is nearly useless:
- Are you saying it's unethical to watch television with sunglasses on? The television producer never intended you to see it that darkly.
Two things are wrong with this: Sunglasses do not contain any communication in any meaningful sense. And second, even to the extent you could call it communication (since the effects of sunglasses could conceivably be described as a software image manipulation), the effects are independent of the content you are viewing. There are never any circumstances where it's unethical to wear sunglasses from a communication ethics point of view, because the "content" of the sunglasses will never depend on what you are looking at.
- What about the manufacturer's logo on my television? Is it unethical for the logo to be there, since it affects my viewing? Again, no, the logo is fully independent of the content being watched. Same for television overlay menus, which I previously mentioned explicitly.
- Are you saying you think it's unethical to rewind, or skip commercials, or watch a program backwards? No, you can manipulate content on your end as you please, as long as it is kept away from other content. Again, even if you describe "rewinding" or "fast forward" in terms of software (which it may well be if the device being used is digital, like a TiVo), that software is independent of the content and does not itself modify the manipulated content by changing the concrete parts of the content; a program watched in reverse is the same program.
All of these misinterpretations of what I'm saying center around missing the primary point: The point is not about trying to limit what the receiver can do. The point is the message should be kept pure. As long as the message remains untouched by other external messages, the receiver is free to do as they please.
Of course identical arguments can be made in any physical domain, not just television. I use television because it's the one that seems to be brought up most often, even when the debate does not otherwise involve them.
Similarly, even when the debate doesn't involve annotation, people frequently defend integrity attacks in terms of annotation, so for the flip side arguments let me express them in terms of shared website annotation:
- Why shouldn't I be allowed to annotate websites? It's just like writing a comment in a newspaper then passing it to my friend, and there's nothing wrong with that. Well, it's true that there is nothing wrong with writing a comment in a newspaper and passing it to your friend. But website annotation is more like running around and writing that comment in all the newspapers in town.
No, wait, it's more like breaking into the printing facility and changing the print run to contain these new comments.
No, wait, it's like distributing special glasses that only change what people see in the newspaper for people who put them on. (Seriously, as silly as this sounds it will inevitably come up in an annotation debate, and as far as I know it's independently created each time. When your metaphors get this out of touch with reality, it's time to ask whether your metaphor is useless or if your argument is that hopelessly absurd. Or, as in this case, both.)
No, wait, it's more like...
The reality is that there is no physical metaphor that matches what happens with website annotation, or the other wide variety of message manipulations possible by inserting something between the sender and receiver. Neither justifying it nor proving it evil will be possible on the basis of a physical metaphor. That's why this more sophisticated theory is necessary.
The fact is there is a provable qualitative difference between scribbling a comment down for one person, and scribbling a comment on the newspaper that millions would see. There is a provable qualitative difference between posting on an independent (in my technical sense) message board and directly on the original content. The proof is simply that there are people who want to so annotate webpages; obviously they believe there is a difference between that and posting to a message board, or they would be content to simply post. QED.
- This is just like glasses that only change what you see when you look at billboards. Or Annotation is just like glasses that only eliminate advertisements. Or any number of other things based on glasses. I wouldn't even mention these, but they also come up every time. The problem with these arguments is there isn't even anything to refute; conveniently left out is why exactly we'd consider such glasses ethical either, especially in light of the fact that no such glasses exist and are impossible (except in extremely controlled environments) in the real world right now anyhow. Proof by irrelevant metaphor?
The basic fallacy here is an attempt to divorce the effects of a process from its technical implementation. These metaphors are all trying to justify the technical methods used to do the annotation, but fail twice: First because the physical metaphors can't conceivably apply anyhow, and second because it's not the mechanism that's the problem anyhow. Follow the effects. The real pertinent question is whether or not the effect of website annotation is ethical or not, regardless of how it is done, and I believe I've made a convincing argument that they are not ethical.
In fact this argument traps most people who use it, because they are not willing to follow it to its logical conclusion. First, if the technology is OK regardless of how it is used, as these metaphors implicitly argue, then they must prepare to have it used against them by other people, including big corporations. Secondly, the same technology can do all of the things mentioned in this chapter; sure, it may seem like fun to annotation Microsoft's web page, but are they prepared to live in a world where Microsoft can make 90%+ of the web browsers hitting their web site see a special Microsoft-approved version, where Microsoft dynamically twists the page to say what Microsoft wants it to say? It's the same technology; to be consistent this needs to bother you not at all.
This reveals a strength of this ethical theory. Many people proposing the arguments above genuinely have a hard time seeing the difference between website annotation and scribbling a note to their buddy, which I can't blame them for because it took me a long time to articulate it myself. Using this theory helps us see the differences like differences of scale and differences of effect on the concrete parts that go into a final message. Even if you don't agree that the differences affect anything, you can still now see that there are indeed real differences between the two actions, and that as a result, proving that note-scribbling is ethical by no means automatically proves wide-scale website annotation is; they are more different then they are similar and convincing me otherwise will take much more then that.
Communication Ethics book part for Why Is Integrity Desirable?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is worth taking a moment, having carefully defined and explored message integrity, to justify why it is a good thing, and why protecting message integrity is important enough to justify trumping the theoretical benefits some of the integrity attacks, such as annotation or ClearPlay's service, offer.
The logic is quite simple, flowing almost directly from the definition of free speech:
- the right to free speech
- The right to send any message in public, and the corresponding right to receive anybody's message in public, without being pressured, denied access, arrested, or otherwise punished by anyone, subject to somewhat fuzzy, but fairly well-understood exceptions.
This is straight from the definition of free speech, suitably updated for a message model rather then an expression model. The bold parts are the key point: If you can not know that your message is going to be accurately transmitted without someone else degrading its integrity, then you have lost the right to "send any message" in public; instead, you only have the right to "send a message subject to somebody else's modifications". This is not Free Speech.
On the flip side, the more-unusual case of externally-imposed integrity attacks (forcing everyone to use censorware for instance) means that you can not access anybody's message. You can only "receive a message subject to somebody else's modifications". This is not Free Speech.
You can not have Free Speech without guaranteeing integrity.
Communication Ethics book part for Conclusion . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Message integrity attacks are very dangerous because of their ability to destroy the value of communication for everyone who can not afford to "defend" their message against all possible attackers. (Since "defending" a message is effectively impossible, that's basically everyone.) Moreover, the "gains" of such integrity-attacking schemes are themselves marginal, as compared to the damage they can do.
Unfortunately, message integrity attacks are also very subtle, taking advantage of weaknesses in our physical intuition, weaknesses in our understanding of communication ethics, or cloaking themselves in fancy-sounding technology while downplaying the effects of such technology. Even otherwise well-meaning people will defend some integrity attacks, especially when they seem to be a way for the Underdog to strike a blow against the people in power, a narrative we Americans have a weak spot for. The best way to combat this is to acquire a clear understanding of what message integrity is, and to defend it where ever we see it under attack.
In the long run, the only way to have true Free Speech is to allow everybody to speak their messages with the assurance that it will be transmitted with integrity. Free Speech is only guaranteed when nobody has the ability to alter our messages without our permission.
Communication Ethics book part for Degrees Of Freedom. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
So there you have it; a whirlwind tour of nearly every major intellectual property and communication issue of the day, based on a coherent communication model. I've shown you all of these details so you can see how each issue, with the explicit exception of software patents, can all be expressed in the terms of the same basic communication model, with the complete context model as described in the previous chapter. Now, for the final major point of this essay: To show how these issues are all deeply inter-related, and why for consistency's sake, we are limited in what solutions to the problems we can truly choose.
The best way to do this is to determine what degrees of freedom we have in determining our ethics consistently. Degrees of freedom is a term I find myself borrowing from mathematics because there is no true pure-English equivalent.
Put (very) loosely, the degrees of freedom describe how many fully independent directions something may move in, for a very abstract definition of "direction". For instance, while we live in a three-dimensional world, for many practical purposes we only have two degrees of freedom: We can move North/South, or East/West, or a little of both at the same time, but we are not free to move Up/Down. (We do have a little freedom that way, but compared to N/S and E/W, it's quite small; you can go ten miles north far more easily then ten miles straight down or up.)
The key word in that definition, as I've bolded, is independent. We can move North without moving East. We can also if we choose move in both directions at the same time ("northeast"); that's OK too. Generally, we can not and do not move up or down without also moving north, south, east, or west to some degree, so it is not an independent direction.
Similarly, the "Dow Jones Industrial Average", over the course of a single day, may either move Up or Down (or not at all), but there is no "sideways". The Dow Jones Industrial Average only has one degree of freedom. The "Entire Stock Market", on the other hand, is a complicated beast, with all kinds of stock prices independently moving around. Thus, the "Entire Stock Market" actually has one degree of freedom per stock or other trackable entity.
(This is simplified from a full discussion of "degrees of freedom", of course.)
To refresh your memory, one of the earliest parts of this essay observed:
Rather then taking the time to truly map the domain of discourse and look at all of the issues in a coherent way, laws (most especially judicial decisions...) exploited the independence of the media types, and each individual segment got its own laws. ... The Internet in a period of just a few years has taken each of the bubbles that we saw in the previous section and rapidly expanded each of them until they all touch, overlap, and envelop each other. ... the fundamental problem with the current legal system is that the foundational assumption that the legal domains are independent is no longer valid.
To phrase this another way, the old legal system had many degrees of freedom. A law concerning book copying would not affect the laws concerning audio tape copying. The practical realization by the computer industry that all of these things are just various sets of numbers, and they can all be expressed simply as data significantly reduces the degrees of freedom we have in creating our ethical system, because suddenly, laws affecting how audio content is copied does affect how books are copied. Consider how laws like the DMCA, which it is probably fair to say was only intended to protect video, audio, and software by the authors of the bill, has also been found to affect things like printer ink refills, or protecting prices charged for retail goods by Wal-Mart (retracted, but voluntarily by Wal-Mart after public scrutiny, not in court). It is no longer plausible to try to create significantly different systems for different types of communication, unless you can define a particular type carefully enough that it is not easy to ride the boundary condition and cheat the system. Again, there's nothing theoretical about any of this, it's happening all around us. The point of all of this theory is to give us words to communicate with and models to think with; what the theory describes is already here.
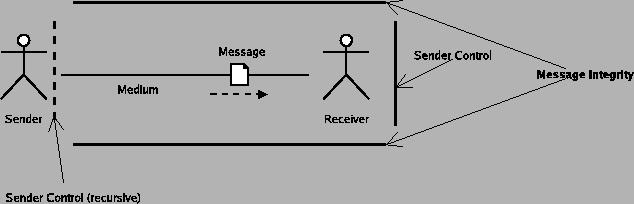 |
Thus, the foundational question we must answer about ethics is how many degrees of freedom are there, and what are they? I submit to you that there are only three.
- Internal Issues
- Message Integrity
- Sender Control
We can draw these issues on our communication model, as seen in the previous figure. Message Integrity is represented by the two lines above and below the message. Sender control is represented by the line on the right of the receiver, controlling what the receiver can do with the message. The line immediately to the right of the sender represents the constraints laid on them by the senders of the messages they are using to assemble the message for the receiver. That means the restraints are recursive on all of the concrete parts that go into the diagrammed message. Internal issues are represented by the entirity of the communication, and is everything inside the box formed by the four lines.
Let's examine those lines in more detail:
Communication Ethics book part for Internal Issues. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
By this I mean things internal to the communcation itself. Is the content truthful? Is it slanderous? Is it covered one of the commonly-accepted exemptions to free speech, such directly threatening someone?
I mention this because up to this point we have not examined the content of the communication itself very much. I think this is because there's no need to do so. Except for some terminology issues (the slander vs. libel distinction isn't really terribly useful anymore), we know what to do with fraud. We know what to do with threats. Nothing is changed by having new media to make threats in, or spread lies in, or make fraudulent claims in. Thus, I am comfortable invoking existing ethics to cover "internal issues", and explicitly discarding them as an issue for this essay.
Many people try to muddy the issue to justify more strict laws but there is little need or call for new harsher laws. When it boils down to it, there's nothing you can say on the Internet that can't already be said through any number of conventional channels, and even the reach isn't different enough to justify any extensive new laws; more people have louder voices, but we have already extended these doctrines to distinguish between people based on their varying reach.
Thus, even though this is theoretically a degree of freedom, we have already decided as a society what our position on these internal issues are, and there's no need to reconsider it.
This is a "degree of freedom" because how we handle this does not directly impact the other two degrees; for instance, fraudulent messages are conceptually removed from discourse entirely so there is no ethical way for the fraudulent message to be sent to anyone anyhow.
Communication Ethics book part for Message Integrity . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Message integrity is essentially a binary issue; either we defend message integrity as described in my Message Integrity chapter, or we do not. There is little or no middle ground because any crack in the integrity can be exploited to do nearly anything, thanks to the patch hole. While it is not strictly speaking impossible to imagine an exemption that can not be so exploited, one can still question why it's worth the risk to free speech.
So while this is theoretically a degree of freedom, if we are to maintain our commitment as a society to the principles of Free Speech for all, we must choose to defend message integrity, and thus this degree of freedom is already chosen for us by our pre-existing ethical values.
Communication Ethics book part for Sender Control Over Message. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
And thus we come to the crux of this essay. What restrictions are the senders allowed to lay on the receivers with regard to what the receivers can do with their messages? I see several distinct issues:
- Can it be received at all? The sender may not send the message at all until (s)he is paid. Or they may not want to send it at all. Or they may not be allowed to keep a message to themselves. Are there provisions of standard contract law that can not be ethically applied to communication?
- What is the receiver allowed to do with the message themselves? Can they archive it? Do they have anything like "Fair Use" rights? Can they manipulate the message as they please (fast forward, rewind, etc.), or are there constraints on how they can experience it?
- Can #1 and #2 interact? Is the sender allowed to discriminate based on what the receiver will do with the message, or not? For example, is it ethical to charge a Pay-Per-View customer twice for seeing the same content twice? Or is it the case that once the message is sent, the sender no longer has an interest in what the receiver does with it? As a practical example, is requiring the use of Digital Restrictions Management hardware and software by a receiver ethical?
- To whom may the receiver forward the message to, and under what circumstances? This certainly interacts with #1, in that the sender may refuse to send the message at all if the receiver insists on being able to post it freely on their web page, but is also worth considering on its own, because there may be special limitations on the kind of restrictions a sender can place on the receiver. For instance, traditional "Fair Use" is covered here; I can forward a small snippet with commentary under certain limited conditions, and there is nothing the sender can do about it ethically. Can I manipulate the forwarded messages (i.e., use a snippet of video in my television program vs. the whole thing)? In what manner?
Having come this far, it may surprise you to learn that I have no intention of answering these questions. I have my opinions, which given this context are brief enough and inconsequential enough to be explained in a sidebar, and I would like to explore the issues in a bit, but I also believe unlike the other two degrees of freedom, there are multiple acceptable answers, even given the choices we've made as a society and the general principles I've laid out in the rest of this essay such as the Symmetry Property.
However, even in the domain of the multiple acceptable answers, not all answers are possible simultaneously. Some choices we make will constrict our freedom to make other choices, and we will either need to decide which is more valuable to us, or work out some way to cleanly delimit the boundaries between the domains where different choices take effect. As I take you through at least a partial analysis of the issues, the most important things to watch for are the fundamental conflicts between different choices made for how the sender can restrict the receiver.
On the one hand it seems rather odd that it took this long to get to this result. On the other hand, I don't think anyone who has been tracking these issues can deny that there's a lot of confusion and fuzzy thinking out there. One could probably spend two or three times more verbiage then I have just clearing away the fuzz, and until the questions are clarified, it's impossible to give good answers to any question. I believe that you can not just jump into this chapter and truly understand what I'm trying to say without the context and terminology provided by the previous chapters.
Communication Ethics book part for Wildly Inconsistent Answers. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I'd like to take a moment and make concrete the points initially made abstractly in chapter 2. Our problem lies in the fact that we have chosen wildly inconsistent answers to these questions, both because of accidents of technology being perceived as fundamental ethical principles and because certain issues like Privacy have not been carefully analysed as in this essay to show how connected they are with other communication issues. Consider the following matrix of Issues and summaries of what seem to be our current system's answers to the preceding questions:
| Issue | When can it be received? | What can the receiver do? | Can those interact? | Can the message be forwarded? |
| Music (Radio) | Freely broadcast with no contract (no money from receiver) | tape it for later listening (though the industry would like to eliminate this) | can only make "personal" use (businesses can't just turn on a radio without paying) (codified in law since there's no contract) | Only Fair Use |
| Music CD, Movies DVD | receiver must pay for content + media | somewhat up in the air, but space shifting and format shifting seem to be OK | some CDs are trying to use DRM-like techniques to prevent certain uses like format-shifting | somewhat up in the air; can you send your grandmother an MP3 from a CD you own legally? (Does whether your grandmother lives with you impact that?) |
| TV | same as Radio | same as Radio | same as Radio | same as Radio |
| Movies (theatre) | controlled by physical access | controlled by physical access, banning recording equipment on the premises. | pay once, view once (but one can make the case that one is renting a seat for a period of time) | never in physical possession of the movie, so nothing is possible |
| Privacy-sensitive Information | information must be sent out to perform certain transactions | nearly anything they want. (Some very limited exceptions like HIPAA restrictions) | no, sender of PSI is typically allowed no control over the PSI after it is sent | anything the PSI receiver pleases |
| Software | heavy contract restrictions in the general case | based on contract restrictions, seems to be no limit to what those contracts can contain (UCITA), though they've never been tested | based on contract restrictions with no apparent limit | based on contract restrictions with no apparent limit |
| Actual Speech | controlled by physical proximity; admission charges or physical barriers may bar access | may be recorded by listener, copyright for recording belongs to the recorder, not the speaker (speaker may have other copyright) | none I know of | none I know of |
| Books | controlled by physical access mechanism | unrestricted (historically impossible to restrict book users) | no restrictions technically possible, so historically no-one ever thought of it | traditionally, since books can't be copied they can be given to anyone and nobody cares. There are some interesting issues if a society wants to have public libraries. |
| Website text | in general, may be as restricted as software is (usually freely available) | technically, messages can usually be archived, but it's an open question if this is generally acceptable (and also an open question what it means if it's not) | theoretically as rich as software contracts, usually not used | theoretically as rich as software contracts, usually not used |
There's a lot of summarizing going on in that table; for instance the "Privacy Sensitive Information" answers were specifically written with the common case of addresses, phone numbers, credit history, etc. in mind, not the more esoteric privacy sensitive information that still falls under my defintion. "Software" discusses the general case, even though not all software lays all the restrictions on the receiver. This isn't even complete, either, but I think this is enough to show the point.
The key here is to note the incredible discontinuity between the current answers to those questions, even though it's all the same thing, just numbers. Even very similar things like "Website text" and "Books" have wildly differing answers; as they merge ("E-books") it is impossible to simultaneously reconcile the differences while also keeping everything the same as it was before; one of those has got to go.
In fact, that's a general problem with effectively every technology here; you can not simultsneously preserve all of these historical accidents in the Internet era.
Communication Ethics book part for Consistent Answers Needed. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As technology continues its march, what we need is a uniform set of answers that we can apply across all of these "content types", because the very concept of "content type" is becoming meaningless. Or we at least need something that can be applied "nearly uniformly"; deviations from the uniform for specific circumstances will certainly be necessary and desirable, but we should start from a firm foundation.
This may sound hopelessly Utopian but I think that is only because we have become used to the gelatinous blob that passes for current law. The reality is we will eventually have something like what I am proposing; the question is whether we get there in fits and starts, only after years of painful lawmaking and judicial oversight, and with lots of useless cruft still in place, or if we get there relatively smoothly because we had the foresight to see change. Lest you think I personally am hopelessly Utopian, yes, I'm betting on the former, but I hope this essay in some small way can help us move towards the latter.
I'd like to look at each of these four sub-questions and examine the issues more closely now; like I said, I don't necessarily have answers but I think I can ask some good questions with the foundation I've laid down.
Communication Ethics book part for Social vs. Individual Effects. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Up to this point we've only talked about the relationship between individuals, because even large-scale one-to-many or many-to-many communication can be modeled as a series of one-to-one communications. As it comes time to choose as a society what restrictions we will allow senders to lay on receivers, it's appropriate to start analysing social effects.
Social effects of course arise from the combination of lots and lot of individual interactions. Some things only matter when lots of people do them; for instance see tragedy of the commons. Some effects only become obvious when you think about lots of people doing them. Since we have freedom on the individual level, we need to decide what effects as a society we want to encourage or discourage. After all, "intellectual property" law is supposed to be derived from the idea of managing social effects via legislating individuals:
To promote the Progress of Science and useful Arts, by securing for limited Times to Authors and Inventors the exclusive Right to their respective Writings and Discoveries; - Section 8 of the United States Constitution
We have to consider social effects because the ethics at an individual level can't guide us; there are too many possible legitimate answers.
Communication Ethics book part for Receiving Messages. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Generally, message reception can be handled as a contract issue, with optional explicit media-based exceptions for compulsory licensing. In the future, and even to a large degree in the present, the licensing model will be dissociated from the content type, and I think this is overall a good thing as it increases the freedom of the market to set prices. It will be important for governments and informed consumers to make sure no one source of information gets too powerful and starts trying to exert asymmetric control over the receiver or the sender (for instance, one can make a good case the music industry exerts too much control on the music authors because of their collective market dominance and oligarchial actions), but I do not think those are truly new ethical issues.
Public Libraries vs. Digital Restrictions Management
Easily the thorniest question we face as we decide our answer to the reception issue is "What is the role of a public library in the Internet era?" The strictest possible contractual restrictions, which are "only one person shall use this content for some finite period of time", backed up by well-implemented Digital Restrictions Management techniques, are simply antithetical to the existance of public libraries. If strong digital restrictions management is to be elevated to the status of law, as the DMCA strongly hints at if it does not actually already accomplish, it will eventually be the death of libraries.
In the end, we must really choose either public libraries, or strong DRM. It's impossible to have both with the current conception of a "public library" because we'd have to poke holes in the DRM to allow libraries special access, holes that would end up "leaking content" out of the DRM system. (For instance, photocopying resources is still provided by most libraries; the digital equivalent of photocopying, which is "printing", would take text resources out of the DRM system. Speaking as a computer scientist, I have no confidence in the long-term viability of techniques such as "watermarking" that try to keep even such printed resources "in" the DRM system; once it's out, it's out.)
One solution is restrict libraries to what are technically allowed by DRM. In the current environment, that may well be equivalent to eliminating libraries, since there is little or no (perceived) motivation for a sender to allow one's works to be lent out by a library when, from the sender's point of view, the lendee could instead be purchasing them. There are some arguments on whether libraries still provide a net gain to the sender in the end, but truthfully, most of them sound strained even to me, and if this is the only reason we have libraries, then it should be left up to the sender to decide whether they wish to take that risk. Without some sort of law protecting libraries as the First Sale doctrine does now, I can not see the majority of future senders willingly allowing libraries to lend their messages. This also interacts with my question of whether it is even reasonable to imagine taking a message away, which I'll explore in a bit in connection with "How can a sender restrict the receiver?".
Complete elimination of libraries is another option. Since libraries are build upon the First Sale doctrine which I've previously explained as being dead in the current era, if no other library-protecting legislation is passed this is the "default fate" for libraries.
I think we need to preserve libraries for lots of good ethical reasons that fall outside of pure "communication" ethics. I think they are a net good for society. I think the value of libraries to our society far, far outweighs the value of DRM. But there is nothing in these communication ethics or the legal mechanisms being developed that will support the libraries. Our current path will lead to the casual elimination of libraries by the large copyright interests. If we want to stop this, we will need to come to a concious decision as a society.
Librarians, if you're not close to retirement you really ought to be pounding the pavement on this point a bit more; your jobs are in imminent danger over the next couple of decades!
Communication Ethics book part for What Is the Receiver Allowed To Do?. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
In the past, once the message (in the form of an expression) was delivered to the receiver, there was no way to control how this message was used by the receiver. Now there are ways to control the message, even after delivery, via the Digital Restrictions Management technology discussed so often before.
For example, nearly all DVDs require the viewer to sit through the FBI warning at the beginning for the full period of time the DVD producer decides. Many DVDs actually require the viewer to watch previews before the main movie could be viewed.
Can the receiver skip commercials, like with TiVo? Can they rewind or fast forward at all? If they schedule a movie for 5pm does that mean they have to be there or miss out?
But all of these questions first presume that these restrictions are acceptable and we merely need to quibble about which ones are OK. We seem to have managed just fine without them until the present time. We're mostly still managing just fine without them, in the publishing and music industries. Why should we suddenly start trying to restrict people, just because we "can"? Is that a net value to society?
What about a model where once a receiver experiences your message, they have every right to experience it again?
If you could tape every moment of your life for your own personal viewing, would you like to be told that you can't legally re-experience moments in your life over again because they are copyrighted by someone else?
What if I told you that you were already taping your life through the wonders of "memory"? What's the real ethical difference between "remembering" a song you experienced before, and listening to it again? Especially since some of us have photographic memories and can literally re-read a book, rendering most of the obvious differences moot?
Does it even make sense to allow the sender these sorts of restrictions?
Clearly, I'm trying to bias you in favor of "no". I admit that. I know there are counterarguments. I just want you to consider all sides of the issue fairly. Again, I issue the "this is not just theoretical" disclaimer; the technology to tape every moment of your life for your personal use already exists, and will almost certainly be available to the public in five or ten years, barring legal challenges. (The buzzword to keep your eye on is "life caching".) Moreover, there's no theoretical reason why we won't eventually be able to produce devices to tap into the human memory directly, though that is even further off. Are we going to extend "copyright"-like concepts all the way into the brain? (Are we willing to extend the "right to free speech" into a "right to free thought"?)
Communication Ethics book part for Interaction of Restrictions and Sending. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As our technology continues to improve, and our theoretical ability to control the receiver continues to improve, it's worth carefully examining the restrictions we are considering for the definition of "experiencing" the message they imply. Half of analyzing a Digital Restriction Management system is determining how it defines "experience" for the types of messages it is trying to restrict.
I don't support requiring senders to help receivers archive their works; there's nothing fundamentally wrong with the idea of pay-per-view as such. But what does it mean if we restrict pay-per-view customers from recording the pay-per-view event for their own archives? In the days before it such restrictions were possible, such as in the mid-1990s, one could say that when a customer purchased a pay-per-view event they were paying for delivery. If we restrict what people can do with pay-per-view content, does that mean that the customer is now paying for a viewing, rather then delivery? Does that mean that the customer has legal grounds to demand a refund if they do not actually view the event as planned? In the 1990s, we would have considered that a specious argument because the goods were delivered as contracted. Now, if the customer doesn't view the work, it seems they paid money for a viewing and got nothing in return. Can the pay-per-view provider just tell the customer that it's too bad?
To maintain the principle of symmetry, restrictions on what a receiver can do imply a corresponding responsibility for the sender. DRM that does not account for this is unethical. All DRM systems I know of are strictly in terms of giving the senders control with no mechanism for the receiver to hold the sender to their responsibilities.
Further, the contracts from the providers that boil down to "The customer shall give us money, and we may or may not deign to provide them certain services" need to be stopped as well. They are probably already unenforcable even under current law, so this is no great loss. The more tightly the reins are pulled on the receiver, the higher quality service the receiver should be able to demand.
Natural vs. Unnatural Restrictions
I think it's worth taking a moment to differentiate between "natural restrictions" and "unnatural restrictions". Natural restrictions flow from the technology itself, and are often removed by later technology. It is not inherently easy to record television. It was never the responsibility of the television industry to make it easy for the home user to record. However, once the VCR came along, the industry had no right to restrict their use, either. A natural restriction was thus removed. There is nobody who intends (in the legal sense of "intent") to have these restrictions, they just naturally exist.
Unnatural restrictions are deliberate limitations to the technology, intentionally engineered into the final product (again in the legal sense of "intent"). There may be a little bit of fuzziness here but it's usually pretty clear whether a technology has been deliberately hobbled or not, especially as our ability to sling numbers around improves.
There is obviously a big ethical difference between these two. That nobody could copy compact disks cheaply when they first came out was to be expected ("burnable" CD's are actually quite sophisticated technology and they were not trivial to develop, even though we use them casually now), and the various industries did not have an ethical mandate to wait to use CDs until people could so copy them. The inability to archive or make direct fair use of the digital data was a natural restriction of the technology.
DRM is an intentional technology, creating intentional restrictions. Even when they merely mirror older sets of restrictions, there is a significant ethical difference.
Communication Ethics book part for Sharing Messaeges. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The entire question of what it means to "share" a message can be boiled down to "how do we define a receiver?" This is the other half of analyzing a Digital Restrictions Management system.
In this essay, I've very carefully defined almost every component of the communication model. The receiver is left undefined because it's actually very hard to tell who is the ethical receiver (or, for the computer folk in the audience, the logical receiver). It's usually pretty easy to point to a physical receiver but that is often not the same thing.
Most media purchased from commercial retail outlets are essentially sold to households, not people. I may have bought a DVD yesterday, but my wife or children are free to watch it, even if I am not around. So while I may have physically acquired the DVD, it is clear my entire household has received it in the ethical sense.
This obviously doesn't bring us any closer to a rigorous answer of what a "receiver" is, for what is my "household"? Is it just the legal adults legally registered as living there? Who on Earth can enforce that sort of thing, anyhow? If I have a non-family-member housesit for me, is it a crime for them to watch one of my DVDs? The more you try to narrow down who the "receiver" is, the more very common exceptions you find.
Right now it isn't a crime anyhow, because they could borrow it and watch it that way, so this can be considered as a form of "borrowing". But what of a DRM'ed movie, backed by the DMCA, that I paid for for only household viewing. Would it be a crime for my housesitter to watch that movie because they are fraudulently identifying themselves to the movie sender?
In fact this theory does not point toward a way to rigorously define a "receiver". It points to some ways how we could do that, but it does not prescribe one.
If one tries to narrow down what a receiver is, one is invariably drawn towards extremes, because the lines are fuzzy and people will abuse them. You can't define it in terms of "household", because that's a virtually meaningless term. Same with "family". One is pushed towards either a very narrow view, where only single people can be legitimate receivers, or a very broad view, where entire large, amorphous groups of people at a time are the receiver, as either the restrictions grow, or the group definition grows.
Clearly current DRM technologies are all moving towards the "single person" definition, where one person receives a message, and they may essentially never share it with anyone ever again, possibly not even with themselves if the message "expires". There's no grounds to call this inherently unethical, although the technical difficulties of restricting receivers this much while not restricting their Free Speech rights or creating an asymmetric relationship may be insurmountable. In fact I believe them to be, but this technically is an engineering issue and it is possible that with enough decades of work, a fair but restrictive DRM system could be built. If they are truly impossible then this isn't really an option, ethically, and there is also the question of the damage done while inferior systems are in place, which will certainly be for many years.
On the other hand, we are currently living in the world where the definition of "receiver" is very, very loose, and I'd submit for your consideration that the economy has conspicuously failed to collapse. Right now, practically speaking, I can copy a CD and give it to a friend. Nobody is seriously claiming this is destroying the music industry. (The music industry certainly talks about this on occasion but their real ire is saved for the P2P sharing systems, more about which in a moment.) Is there anything terribly wrong about sharing a movie with your parent, or a friend? Especially if one could develop a culture that still encouraged paying for it? (Anecdotally speaking, I think we live in that culture already. Certainly the purchase rate isn't 100%, but one questions who got the idea that such crime could ever be stamped out, or why these crimes justify restrictions on the rest of us.) The sheer mathematics of life and time work out such that even if giving copies of movies to our friends was as easy as pushing a button, we have better things to do with our time then worry about that.
I think the maximal value to society is obtained with this fairly loose idea of "receiver" that we inherited from older technologies. This includes a seperation between the idea of "sharing with one's friends or family" and "sharing with the world"; we did not condone large-scale piracy in the 1990's and I think that the modern equivalent, large-scale anonymous file sharing to all comers is also unethical. But here I think we can draw a relatively sharp line between "sharing with all comers" and "sharing with just people you know".
The tension here comes from the difficulty in defining "receiver" in different ways for different technologies. Certainly the large content providers of today are comfortable with locking down to individuals and grudgingly admitting that families can probably watch the same movie (though they'd make them pay extra if they could), but that's not necessarily the social ideal. And one must also question the costs of implementing these schemes, which are expensive in both development and maintenence costs, vs. any gains for anyone, even the actual sender, let alone society. Unfortunately either a restrictive or a free model must be chosen, and as usual it will be difficult to impossible to mix the two.
Communication Ethics book part for Boiling It Down . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I think it can basically be boiled down to this:
- DRM or libraries? The evidence to date is any restriction a sender is allowed to place on a receiver will be used. Libraries can't live in a strong, enforced DRM environment. The stronger you make DRM, the weaker libraries and corresponding low-level sharing we all do so routinely we don't even think about it get.
- Fast forward or not? Are we going to live in a world where we have the choice to fast-forward past commercials or not? (manipulating messages)
- Are "receivers" individuals or some group? What group, if any?
Each of those question are merely exemplars of a whole host of related questions, meant to highlight the issues at stake, not exhaustive enumerations of all the issues.
Once you choose the answers, propogating them back out to the various message types and media are really relatively simple. It's the figuring out what we should answer that is that hard part, and what I'm trying to at least help with with this essay. As a society, we need to come to a consistent idea of how the sender can restrict the receiver of a message, while still maintaining symmetry of relationship. It's a subtle problem with more then one good, consistent answer, but quite a few bad, inconsistent answers.
Communication Ethics book part for Terminology. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is probably too late to change terminology, and I'm not enough of a Don Quixote to think I can. But if I could, I would change a few words we use in this domain.
Communication Ethics book part for ``Intellectual Property’’. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
The term "Intellectual Property" covers nearly everything I mean by a "message" except patents, and it probably wouldn't be much of a stretch for most intellectual property lawyers to see privacy-sensitive information as another form of intellectual property. (It certainly already is once it's collected, becoming a normal copyrighted aggregation.)
Many people criticize the term "intellectual property" as inherently containing a metaphor of "ownership", be it of the communication itself, of the ideas (patents), of the phrasing (trademarks), or something. They believe that the physical concept of "ownership" does not apply in this domain, because it has no meaning. They believe that using the term "theft" or even worse, "piracy" is inappropriate because there are no real analogues with the physical meanings of the term. By using these terms, the entire conversation about communication is being prejudiced in a certain direction that does not truly reflect how the things referred to as "intellectual property" works.
They are correct. Certain aspects of the "property" idea are still useful, but as a whole, the entire "intellectual property" idea is a bad metaphor that inhibits understanding, rather then helping it. The few good aspects are swamped by the ways the metaphor impedes understanding. Communication is not property. It can not be meaningfully stolen. It can not be meaningfully transferred in toto to someone else, because at a bare minimum, the original owner will still remember the content of the communication. There is no meaningful analog to copying a communication in a physical process.
A metaphor is only as useful as it correlates to the origin of the metaphor. The fatal flaw of the "intellectual property" metaphor is that with communication, possession is divorced from the ability to own rights on the property. I own this physical chair I am sitting in as I write this. I can do as I please with it, and you can not. If I give it to you, I do not have it any more, and I lose all rights to it. On the other hand, I can and have given you a copy of this essay, yet I believe I retain certain rights to it. This is a night-and-day difference between "intellectual property" and real property, much more then enough to make the metaphor useless.
"Intellectual property" as a concept dates from a time when we did not understand how thoroughly computers would revolutionize communication and help us attain nearly 100% of the theoretical capabilities of communication. The fact is, we've outgrown this old metaphor, and we should be mature enough as a species to give up this crutch. Just as we gave up the concept of a "horseless carriage" and moved to "automobile", just as we gave up "wireless telegraph" and moved to "radio", it's time to give up "non-physical property" and moved to a more mature model of communication.
Note throughout this essay I've studiously avoided using the term "intellectual property" unless I was explicitly discussing the current modes of thinking. After all, the whole point of my essay is to clarify thinking, not muddy it up.
Communication Ethics book part for Message rights, not Intellectual Property. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I'm not good at naming things, but I would propose we need to move to a message-rights based understanding of communication to completely replace the concept of intellectual property in the domain of communication. The question that truly needs to be answered is who has the rights to do what. Note the terminology involving "rights" is already used in practice, "intellectual property" is only used as an aggregate term, and as a rhetorical term. It is very rare to hear of people actually talking about licensing "intellectual property", though I've heard some lawyers use the phrase in public. Typically one talks about licensing the rights: "I licensed the movie rights to the book." I think part of the reason can be seen in that sentence: The word "rights" can take an adjective like "movie" in a way the phrase "intellectual property" can not: "I licensed the movie intellectual property from the book." doesn't make sense, because there is no movie intellectual property until the movie already exists.
This, incidentally, is another way the "property" metaphor breaks down; "property" can not be meaningfully traded or manipulated until it exists. Future rights to physical property can be, though, just as rights to messages that do not yet exist can be.
If the Intellectual Property metaphor's foundation looks something like this:
- There exists knowlege in some people's possession.
- This knowlege can be bought, sold, traded, rented, etc., analogously to pieces of physical property.
- We can create laws to enforce this concept.
Then I propose a foundation like this:
- People communicate messages to each other all the time, sending out copies of various expressions as a result.
- There are certain restrictions on what people can say, and certain rights which may not be abridged.
- There are a special class of restrictions regarding what you can relay from somebody else without their permission.
- We can create laws specifying the restrictions with regard to relaying communications.
This is why I believe that even though this essay is apparently related only to communication ethics that it provides a complete replacement for the concepts of "intellectual property", by building from a superior foundation that better reflects the real world.
Communication Ethics book part for IP Abolitionists. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It isn't just the "IP" lawyers making the mistake of lumping many disparate concepts under one confusing umbrella term, though; by lumping so much stuff under the heading of "intellectual property" you have people calling for the complete abolition of "intellectual property". But because of their poor conceptualization of the problem, these people are calling for something that would be worse then what we have now.
Abolishing IP, be it a version of my communication-based protections or even modern IP, means abandoning everything in this essay. It means abandoning privacy entirely, because it can not be protected. It means abandoning all rights and all control to your messages, not just the messages of others. It means abandoning message integrity, because the defense for message integrity is effectively a copyright-based one. As a result, it means abandoning free speech, since integrity can not be protected and without integrity, we have no free speech. And yes, it means abandoning market rewards for new information, which may be OK in certain very limited domains like software, but will destroy other domains. Even trademarks can be important in subtle ways that we don't usually think of since we live in a society with strong trademarks.
Ironically, the IP abolitionists often hold thier views in the mistaken belief that this will increase their freedom and power, and decrease the power of corporations. They couldn't be more wrong; in the anarchaic environment that would result, it would be corporations who would be better able to exert power, more inclined to create and use DRM standards that only corporations can afford, and individuals who would be left almost entirely defenseless. Only strong IP laws even gives an individual a chance against a large corporation. If anything, IP laws need some selective strengthening, not weakening or outright destruction.
This demonstrates the importance of proper terminology to proper understanding; if we were really working in a message-rights-based model, these people could instead be fruitfully discussing what "inalienable rights" a receiver or a sender has to a message, which is a very important discussion for our society. Instead, these people marginalize themselves by calling for something that won't and shouldn't happen. The IP abolitionists are wrong.
Communication Ethics book part for Non-Communication Intellectual Property . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Not everything that is currently called intellectual property fits into my communication model.
Patents do not fall under the domain of communication (except software patents as described earlier); physical patents can be cast in terms of communicating how to build something but they are clearly intended as protecting physical objects, not the communication itself since the entire patent application is publically and freely available to all. Physical patents contribute to the belief that "intellectual property" is a good concept because it seems like they can indeed be treated as property much more accurately then communication, because they can be truly bought and sold in a way that often deprives the original owner of all rights. Physical patents do not fit in with the other IP concepts, though, because they are not communication related. Instead, a physical patent is the right to tell someone to stop manufacturing something.
I use the term "physical patent" to distinguish it from a "software patent", which is communication related as discussed in the Patent chapter. As software becomes more and more powerful, it may be the case that all patents will become software patents, in the sense that they all become programs running on some powerful robot. In that case, the concept of a patent will become obsoleted, being supplanted by communication-based models.
Communication Ethics book part for Corporations and the Principle of Symmetry. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I've used corporations as an example many times in this essay, but I've not directly addressed how corporations fit into this model. This is because in theory, they are just another entity and as long as the symmetry is maintained in the communication relationship, there's no special theoretical need to address corporations. But as this chapter is addressing more practical concerns, the practical implications of our large corporations should be addressed.
You may think you've detected an anti-corporate undertone in this text, but that's really not representative of my opinions. I've used corporations as examples simply because they are interesting, they get into the news and other permenent records and thus provide citations for me, and because frequently only a large corporation can take advantage of or build new technology. You simply can't run DirecTV out of your garage.
Corporations are a tool of humanity and like any other tool can be used for benefit or harm. Many things we take for granted are difficult or impossible without at least one large company involved, such as making cars. (Automobile companies are supported by hundreds of smaller companies, but there must be one final company that assembles, tests, markets, and sells the final product; those functions really can't be broken up efficiently and that's going to be a big company.) There's nothing inherently wrong with them. But practically speaking, it must be acknowledged that they can wield significantly more power then a single person, power which can easily come into play with communication relationships.
The problem is quite simply one of man power. Today, I have roughly 16 hours of wakefulness, assuming an 8-hour sleep cycle. Every workday, a corporation receives on average slightly more then eight man-hours from each employee. That is to say, for a 10,000 person company, for my 16 hours today, that company received 80,000 man-hours of life (rounding to 8 man-hours), 5,000 times more then me.
Now suppose this company sues me, and we get into a drawn out lawsuit that occurs over the course of a year, and consumes roughly a quarter of my year meeting with lawyers, rotting in jail, preparing defense, worrying such that I can't productively do anything else, etc. (That's probably conservative on my part; it could easily completely destroy my year.) If I live a nearly-average (and conviently rounded) 75 years, that's a third of a percent of my entire life. (If you're willing to call it the entire year, that's one and a third of a percent of my life. If I died tommorow, that would be a full 4% of my life, as I'm near a rounded-by-luck 25.)
Let us suppose this lawsuit also eats three lawyers and the equivalent of one administrator year, for a total of 50 * 5 (fifty weeks, five days a week) * 8 (eight hours a day) * 4 (four people) = 8,000 thousand man-hours. Now, that may sound like a lot but it's only a tenth of one day for the 10,000 person company.
In terms of communication issues, I think that practical symmetry requires thinking about the following considerations, above and beyond normal concerns like monopolistic or oligarchic practices:
- EULAs and other truly massive contracts: A corporation can produce a truly massive contract that the average person is effectively incapable of understanding. A person has no equivalent ability to produce stupifying amounts of legal verbiage; even a single lawyer can't match the output of a well-funded legal team. A large contract that is otherwise perfectly fair and honest may itself be intrinsically unethical simply because there's no way for a customer to discover it is fair and honest, and it is unethical to ask someone to enter into a contract they can not possibly understand. This affects not just EULAs but all contracts with people, both explicit and implicit; we need to recognize there is an upper limit to the complexity an individual can be asked to deal with. In fact, I won't push this claim in this essay except by mentioning it here, but I think a case could be made that this consideration alone renders nearly all current DRM systems unethical due to their highly technical and complicated natures.
- Manpower for enforcement: On more then once occaision, my cable modem service has dropped out for entire days; sometimes it eventually fixed itself and and I didn't have to call, other times I have. At no time did I ever receive any sort of compensation or for that matter even an apology. What am I going to do, waste a significant portion of my day trying to get a pointless symbolic gesture?
On the other hand, if I pay all of my bill but a penny, they will still come after me for the penny. I do not know how far they would push the issue and while it would be an interesting experiment I'm not willing to put my credit history on the line for this. My point is that a corporation, through the economy of scale it gets through its size advantage and automation advantage, can afford to really hold me to my end of the contract. There's an asymmetry here, because they've slipped several times.
Of course, it's actually worse then that. They're a big conpany with lots of lawyers. Technically, the contract states that while I will pay without fail the bill the company sends out for me or suffer great consequences, in return, they will try to deliver service, but if they fail, well, gee, that's too bad. They aren't responsible for anything, up to and including returning money for service not received. If they do return some money it is out of the goodness of their heart. This is one manifestation of point #1.
- Manpower for lawsuits: The simple threat of a lawsuit is a powerful weapon a corporation has. An individual finds it impossible to wield that weapon for the same reason a threat is so effective for the corporation; see the math above. Now imagine that lawsuit was frivolous in the first place; the frivolous corporate suit can be devestating, the frivolous individual suit a mere annoyance. There's power there that needs acknowlegement.
- Manpower for technology: A corporation can mandate DRM on its data. I personally can not right now, and I don't see it happening for a long time. There's an asymmetry in a movie studio effectively protecting its messages with restrictive DRM while I can not protect my privacy-sensitive information (or really any information) with equally effective DRM. This is largely a "natural" restriction right now, as even if useful DRM for personal privacy-sensitive information is developed it will be a long time before it is feasible and in use. But it nevertheless is a significant asymmetry for an individual vs. a corporation right now.
Corporations aren't people; if they are people, they are some sort of wierd, powerful "person" that could legimately be called "superhuman". We shouldn't treat them as the same as normal people, legally.
I honestly don't know what to do about this practically, and it obviously extends beyond merely communication issues. I'm not satisfied with any proposals I've seen so far to try to rectify this problem. But it's a real problem and it's only going to get bigger and more relevant as the armament available to corporations such as DRM improves. I do not know how to convert theory into practice here. But I think we need to consider that very carefully as a society or we will regret it as individuals in the future.
Communication Ethics book part for The Law. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
As I mentioned at the outset, I don't really think it is my place to lay out a complete legal framework, nor am I necessarily qualified to do so. As long as I was speaking only about ethics and generalities, I feel relatively safe that my opinions are meaningful, but constructing laws is a bit out of my domain. However, I do believe that the analysis of the issues can give lawmakers at least a few concrete guidelines while trying to formulate the practical ethics for the next few decades.
First, as I emphasized repeatedly, catastrophic effects occur when technology is directly addressed; contradictions are inevitable, and the legal loopholes will proliferate. Laws should not address technology directly, but be solely concerned with effects on humans. Even recent laws have been falling down on this criterion; the DMCA outlaws "circumvention of a technological access protection measure", instead of the more proper, more general, and more human-centric "accessing of a message without paying the owner a reasonable fee", or some other reasonably human-centric formulation of the real point of the law. By mentioning technology at all, one invokes a morass of issues about what constitutes circumvention, the logic behind outlawing DeCSS even when used only to view DVDs the viewer owns a fully legal copy of, free speech implications of such outlawing, etc. If one merely bans the effect of viewing a protected work without paying, with regard only to the payment and without regard to how the protections were circumvented, a much more general and yet simultaneously less objectionable law is created.
Second, once that principle is understood it becomes clear that the primary public policy question to answer is "Shall a given effect be legal, illegal, or something in between?" Rather then asking if a particular annotation technology is legal, ask if anything with an annotation effect is legal, or under what circumstances it may be legal. Rather then trying to define "framing" in the context of HTML itself, ask if the idea of re-wrapping somebody else's content in a new border is legal, and under what circumstances it is. Once a list of basic effects is created over time, through legislation and court cases, a coherent and meaningful body of law could be created that is actually fair, predictable, and workable. Even if someone creates the World Wide Web Squared, a wonderful new digital frontier as different from the WWW as the WWW is from a world with just email, that case law would still be very useful in determining what was legal and illegal in that new environment.
Prof. Touretsky's Gallery of DeCSS descramblers, previously mentioned in the Software Patents section, brings up a serious of concrete questions about what constitutes a circumvention device under current DMCA law. It highlights the absurdities that are inherent in the way the DMCA tries to define a "circumvention device". Such a gallery is an excellent concrete example of how one can try to skirt the law by dancing around the line; there is a very smooth continuum between "graphic" and "program" shown in the gallery. This highlights the absurdities in the way the DMCA tries to define a "circumvention device"; as soon as you try to nail down a definition of "device", somebody can come up with something that isn't quite a "device", but would allow "circumvention" with a reasonable amount of effort.
With my formulation of the issues, even if you do decide to "ban DeCSS" there's a reasonable answer to what constitutes a "circumvention device": DeCSS is a "circumvention device" the moment it is used to do something that affects a human, in this case, decoding a DVD that the law says should not be decoded. Even a copy of the DeCSS algorithm, sitting on the hard drive, one simple command away from running on a DVD, is not a circumvention device. It must be loaded into memory and actually executed in such a way as to affect a human, and only that copy is a circumvention device. Even a partial application of these principles would correct some of the outright absurdities embedded into current law. Again, this boils down to the following the effects: The question is whether a movie was illegally watched, not whether a program was executed.
In many of these cases, there is a societal judgement call in where the line is, and while I have my opinions, I certainly believe that there are a number of other valid opinions. Thus, I don't really see the point in trying to enumerate these effects and giving my opinions. What I really care about is that these principles be used to create good law, better then the inconsistent, incoherent trash currently being passed and judicated currently.
Communication Ethics book part for ``Cheat Sheet’’ for Lawmakers. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
- Follow the effects. The mechanism is irrelevant. Only effects matter. Tools are inherently neutral. Some may be more easily abused then others, but even guns and nuclear weapons have very legitimate uses. We judge the ethicality of their use based on the effects of their use.
- Only humans communicate. Laws that discuss ethical concepts should only reference humans, not machines. Laws referencing machines should be strictly confined to mechanics. The DMCA should not discuss programs, it should discuss whether a person violates copyright. Laws concerning EM frequency allocation must reference specific electrical properties, but should not discuss ethical concepts.
- Maintain symmetry. Symmetry as discussed in this essay benefits everyone, big and small. There is no compelling reason to write a law that only large companies can comply with, unless there are legitimate physical reasons (EM spectrum interference, for instance; there can only be one TV Channel 7 in a certain area); such stunting of communication will have negative effects for society as a whole. Everybody is a sender; if not today, then tommorow. Even you, Congressperson.
- Complexity is bad. Complex laws will interact very poorly with a complex world.
Communication Ethics book part for Exercise: Making a Good Law . (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Let's take the case of the Australian television authorities considering requiring a license for streaming video, and try to make a good law out of it in stages.
- Leave the law as it is: The first option is to simply ignore streaming video. But as I mentioned the first time we discussed this, sooner or later a streaming video provider can have all the reach of a conventional television station, and those television laws exist for a reason. This doesn't seem like a good idea.
- Require a license for streaming: As a first cut idea, this isn't too bad, but there's the obvious problem that not all streaming is television sized. One of the big selling points for cable modems where I live is that you're supposed to be able to do "video teleconferencing", and on a purely pragmatic level, nobody wants to license thousands or millions of normal citizens (as opposed to large corporations) streaming video; who's got the budget to afford that?
- Define "large-scale streaming": You might consider defining something like "large-scale streaming" to avoid the teleconferencing case. Maybe you'll define a "large scale streamer" as "an entity that serves out more then ten hours of video per hour". (Of course there's nothing holy about "ten".) But you've made a mistake... can you see what it is before I tell you the answer?
I've implicitly defined "large-scale streaming" in terms of how it is technically served out. Therefore, you've opened yourself to technical circumventions of the law. Imagine a peer-to-peer video sharing network, where no one peer ever serves out more then ten streams at a time, yet the system as a whole reaches thousands or millions of people. As is usually the case with "technical" circumventions, there's a good reason to do this even outside of "getting around the law"; the bandwidth drain on any one person is much lower with such a system, and if done correctly is easier on the network as a whole as well. There's good reason to create this sort of network, technically. For a real-world example, see BitTorrent (http://bittorrent.com), which helps download large files like Linux distributions without hammering the hosting server.
The question to answer at this point is "Who are we seeking to regulate, the broadcasters (transmitters) or content producers?" Since for television, broadcasters and content producers are typically the same organization, or at least very closely related, this will be a new conundrum for the television regulatory agencies. The answer changes depending on exactly which regulation we're considering. Certain types of regulations, such as "requiring X minutes of public service broadcasting a day" are regulating the broadcasters, whereas content-based regulations are laid upon the content producers. Since we're talking the Internet, the television regulatory commision probably won't have the power to regulate the Internet common carriers, so they'd either have to give up that idea or work with the agency or agencies that do have that power. They can continue to regulate content, though, so let's try that:
- Define "large-scale streams": I'd suggest something like "A large-scale stream is a stream created with the intent and reasonable knowlege that it will be viewed by X people in an hour shall be subject to the following restrictions:" where "X" is a reasonably large number like 100 or 1,000. Note that traditional television still handily fits within this definition. Note also that if someone posts one of those accidentally popular video files (like AYBABTU) they won't suddenly get smacked with the need for a broadcasting license; there's not much point then because such freak phenomenon are rare and unlikely to be replicated by the same person. If they do happen to be replicated, require a license.
Also note I've not tied this to the stream being "live", because that is another technical consideration that would allow people to circumvent the law by not streaming it "live" but offering it for download instead. On the other hand, the phrase "in an hour" is necessary because a small video file could collect 1,000 viewings over the course of five years; we're not worried about those.
Now you've got the basis for creating law that can address things like content considerations without on the one hand unduly limiting technology, or on the other hand, being obsoleted by the advent of new technology. If it's a video stream going to X people per hour, this law covers it.
Communication Ethics book part for Conclusion. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Having brushed away a hundred years of misconceptions and layer upon layer of unclear, fuzzy concepts and terminology, and replaced them by a clear model for communication, it becomes clear that the fundamental question before us as our communications technology continues to progress is this: What restrictions are fair for a sender to lay on a receiver, and how can we back the answer to that question up by law?
The current confusion we are experiencing is not fundamental to the domain, it's caused by our attempts to be radically inconsistent in how we answered that simple question, and our inability to sustain the previous answers now that previously seperate communication domains are merging. There is no true need to be inconsistent, and the harder we try, the more the system will strain against us.
As I said above, I don't believe that there is One Perfect Solution that we must choose, I believe there is a range. But that range is really a rather narrow range, with only a handful of choices to be made, and once we have made those choices, practical application is rather simple.
Communication Ethics book part for The Goals of the Ethics Framework. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
This should technically be placed immediately after we justify the need for a new framework, but who would read it? It's worth explicitly going through our goals, so you can easily evaluate other proposals against the same standards.
Communication Ethics book part for Simplicity. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It's a chestnut by now, but "Perfection is achieved not when there is nothing left to add, but when there is nothing left to take away.", attributed to a wide variety of sources.
No solution to any communication issue that works in the real world will ever be simple in execution, and there's no way we can totally avoid ambiguity that the courts will have to clean up every so often over time. But we must strive for a conceptual framework that is simple in its heart, that is based on some simple concept.
Complexity in implementation could be tolerated when these issues were more or less separated. Unfortunately, when large complex systems that were not designed to interact with one another start interacting anyhow, the result is vastly more complex. A common metaphor here is that the complexities tend to behave like multiplication, and I would consider that essentially accurate. Those with good mathematical intuition will recognize that I am claiming that it will be utterly impossible for our legal system to continue with its current policies; the number of systems interacting is high and they are all combining.
We all sense this. We all feel the system is flying out of control and that nobody has a grasp on it. The major content production groups (RIAA, MPAA) react by getting more and harsher laws passed to try to return some semblance of control to the situation, but that only makes the landscape even more complex, as the laws are broad and ill-conceived, and thus open to abuse. The common man watches a bewildering, incomprehensible miasma of new laws pop up and tell him that any number of previous acceptable activities or devices are now illegal. The domain of activities one can safely engage in without a lawyer steadily shrinks, which is especially economically damaging when you're trying to sell to the general public as they can become afraid of the complexity and simply not buy. The complexity of the copyright system is rapidly exceeding the abilities of any one individual, no matter how highly trained, to keep track of it. Among the other already-stated reasons, this is partially why I do not spend too much time getting into the specifics of the current system; I simply don't have time to absorb all of its complexities and still do my non-lawyer job.
Odds are any set of solutions attempting to address areas individually will fail this criteria, unless the solutions truly can strictly partition which parts take effect under which circumstances so that they do not interact. I can't prove this because it's really hard to prove a negative, but I'm willing to bet no such set of solutions exists such that there will never (or close to never) be any ambiguity which part of the solution applies to a given case, simply by virtue of the fact that the flexibility of the Internet does not seem to allow the drawing of clear lines between the capabilities.
We must drastically lower the number of special cases, preferably even the number of classes of distinct kinds of communication from its present high count. If we do not, the system will (continue to) self-destruct.
Communication Ethics book part for Robustness. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
It is only reasonable to assume that we've only begun to see the types of interactions that will be occurring and the legal actions that will result.
Any proposed solution must not just work for yesterday and today, but work reasonably well into tomorrow. This characteristic is required for much the same reason as simplicity; as the interactions between the various legal domains occur, the guiding principles of the solution need to provide some measure of guidance. No matter how pretty a theory somebody may spin, any real-world legal solution will have its share of special cases and exceptions. The guiding principles themselves, as explained by the theory, must still provide guidance if they are to be of any use, even if society deliberately chooses to do something else. If the theory itself is contradictory on some issue or combination of issues before the real world is even considered, then the theory is of little use, and may even be a hindrance.
And not just tomorrow as in "next year", but hopefully for decades to come. Companies need to know that their business models will still be legal (or still be illegal) ten years from now with some level of confidence. The new technologies that are developed need to not affect the viability of the solution too much.
In order to accomplish this goal, it is clear that a solution tied too intimately to technology is doomed to fail this measure. Technologies are very ephemeral. This tells us that for better or for worse, we must create guiding principles that do not really relate to the intricate engineering details of what a technology is doing. We must take a higher level view of what is going on, and somehow manage to not get bogged down in details.
This will be a great challenge to correctly perform that balancing act, but if we can manage to find a solution that has long-term viability (a big if!), it also means that the precise details of the technology disputes of the future won't matter to the judge so much. Once the dispute's relationship to the guiding principles are ascertained, the technology will have to fade into near irrelevance. This is good news, because it means our judges and lawyers won't necessarily need degrees in engineering, just enough training to understand the principles of engineering (although even this lower standard is curiously absent in current lawyers).
It should be clear that the path we are currently on is the very antithesis of robustness. Once you start using technology to move content in a way not possible in the early 1980's, you are in trouble. There are simple issues on the Internet that remain largely unresolved, and are largely ignored because they provide the foundation of the Internet as we know it.
Another example of this, in addition to ones described elsewhere: Do you have the right to access content on public servers, or can I selectively deny certain corporations from accessing the information? For instance, do an Internet search for "eBay vs. Bidder's Edge"; eBay tried to deny Bidder's Edge access to their servers, which Bidder's Edge was using to download huge quantities of information to provide services to other people. This case "resolved" the issue only in the narrowest sense, and using the rather dangerous doctrine of trespass, which really doesn't make much sense in this context.
Communication Ethics book part for Completeness. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Any good solution must be complete, and cover the entire domain of issues well. Solving "The Napster Problem", in isolation from anything else, is not a solution at all; any decision made in isolation in that case will only create more loopholes and special cases that others may find ways to use to their advantage. For example, there was once a bill before Congress that would specifically allowed people to do what MP3.com wanted to do with its "beaming service"... are they ready to guarantee the same rights for all other media as well? Is that law ready for the case when some company allows people to scan their VCR tapes somehow, beam confirmation to the company's servers that they own a legal copy of the movie, and allow people to download the digital video version? If not, why not? Movies are just like songs in most of the important respects; the only reason it's not already happening is that movies are large. (This also serves as a good example of a non-robust solution as well; what little virtue the bill had when it was proposed will only diminish over time.)
I emphasize that is only a particular example. There are tens or hundreds that could plausibly generated. The solution must be complete; it can't just deal with music, but ignore movies. It can't deal with movies and ignore computer games. It can't deal with books, but ignore websites. Far too many little solutions to little problems have been proposed, but since each interact in unpredictable ways, they can never solve more problems then they generate.
This requirement basically knocks the court systems out of the running. Courts can only properly rule on cases that are before them, and they basically lack the ability to create coherent systems of law. Congress is much better at that, so we must expect a legislative solution. It should also be clear that the legislative branch in the US is currently writing laws that are no more coherent then the court system. If it isn't clear to you yet, contrast a law like the DMCA with the general framework proposed in this essay and you'll see what I mean. In fact, Congress is several steps behind the courts, as the courts have had to deal with actual conflicts and resolve them somehow, while Congress was able to just ignore the problem, or view the issues through only one side's point of view.
Communication Ethics book part for Short Term Viability. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
Short-term viability may seem redundant to robustness, but it is not. This is a largely economic concern; not usually associated with ethics but I prefer ethics that are usable in the real world to useless abstract principles, so it should be considered. Companies need to know whether or not a business plan is viable before they open themselves up to the potential damages that Napster faced... before settling with the music companies, Napster was looking at hundreds of billions in claimed damages. But this is not the real reason that short-term viability is necessary.
It is common knowledge that the technology industry moves much faster then the legal system does. This is wrong. In reality, the legal system merely moves much less often, and deliberates those moves more carefully, then the technology industry which has a more continuous flow, with constant little changes.
The legal system may move rarely, but when it does move, the moves are massive! The Digital Millennium Copyright Act changed a whole lot of things when it was passed, and did it very quickly. Overnight, a large number of previously viable activities became illegal, and a much smaller number of previously questionable legal activities became well-determined. For instance, nobody knew how much legal protection was gained by putting access restrictions on something; the DMCA cleared that up, regrettably in favor of giving any restriction whatsoever full legal protection. Also, a large number of other activities that were previously not illegal in and of themselves, such as bypassing access restrictions, became illegal. The tendency of the legal system, especially the legislative branch, to produce huge changes is the basic reason it is necessary to deliberate so carefully in the first place.
If a solution makes sense in the short-term, this basically means that there aren't any technologies that can suddenly pop up that create contradictions in the solution. This means that while the legal system may take a great deal of time to arrive at a conclusion, if the solution makes sense to most people, the government should act predictably. Predictability is generally good in a government.
If ethical and applied-ethical (legal) solutions won't even work next month, then of course it's simply a waste of our time!
Communication Ethics book part for Usefulness. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
For our final criterion, I'm going to mention something that may seem silly, but it's still a necessity. The solution needs to be useful; it can't be so weak that it has no real applications. This is perhaps the biggest problem with the current guiding principles of the legal system; they are so weak now as to be nearly useless.
Intellectual Property law's basic guiding principle is to promote innovation and thereby good to society, at least in theory. It's a good principle as far as it goes, but it has the unfortunate problem that there are multiple good ways to do that. Both sides of a debate claim they are supported by this principle, and generally both sides are right in their own way. The principle doesn't have any usefulness. This means that the court cases are being decided less on the merits of the case and more on the particular biases of who the judge thinks is innovating. For instance, in the first round of the Napster vs. RIAA case, in my opinion Judge Patel essentially ruled for Big Money and against the Internet Punk Thieves... which may be a valid ruling (assuming that Napster also represents Internet Punk Thieves, which is also another discussion) but was not truly informed on the basis of promoting innovation, but rather on the basis of preserving the interests of the status quo. (Note I also would have ruled against Napster, just for entirely different reasons, so this is not sour grapes about a ruling by one of said Punk Thieves.)
So if I get done spinning a theory but that theory never says anything is right, wrong, or up to the society to just decide, it's still completely useless.
Communication Ethics book part for Conclusion. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I think it's pretty obvious that current practice fails on every single one of these counts. If you find this topic interesting and have read other people's essays on these topics, I think you'll also see they fail most of these criteria, especially because there are so many essays on isolated topics. It's great that there are people writing about these problems, and many of them have been of great help in putting this together, but we need to start creating coherent structures that might be useful across many of these issues if we are to do anything.
Communication Ethics book part for Appendix: The Technical Lawyer Cirriculum. (This is an automatically generated summary to avoid having huge posts on this page. Click through to read this post.)
I'm not a lawyer, I'm a technically competent person. Right now, the lawyers and the geeks are so estranged from each other that they can't even communicate rationally. Sooner or later, this has got to change and we will need a large number of people who can bridge this communication gap well enough to communicate. We should not expect one person to be completely competent in both fields, but perhaps we can cross-train people well enough to work together.
In the end, I believe it will make more sense to train otherwise 'normal' lawyers to a basic level of technical competence. It will require less effort and meet with better results then trying to train engineers to be lawyers. (If you want to see engineers trying to be lawyers, just look at the legal idiocy on Slashdot sometime.) While I would certainly encourage engineers to pick up some legal understanding if they are going to work with lawyers, learning basic principles of law gains you much less bang-for-the-buck then learning the basic principles of engineering.
On an intuitive level, this should make sense. While the computer industry has all sorts of nooks and crannies, all of those nooks and crannies are working on the same basic principles of what is possible to do with computers. If you learn those principles, you're a long way toward understanding computers in general. This is more-or-less because computing is a mathematical domain, and mathematical domains tend to be fairly simple... at least in comparison to fuzzy human domains like law. While the foundation of intellectual property law may stem from a very few simple principles (like "preserve an incentive to innovate"), you can't take another step without instantly being bogged down in exceptions, precedents, international differences, and a whole slew of details, which isn't helped by the fact that we're in uncharted territory anyhow.
I'll leave what legal stuff should be taught in this legal program, which I'm going to call "technical law" in the hopes that that doesn't already refer to something, to the lawyers (though we can assume a strong leaning toward property (intellectual and otherwise) law and international law), but as a technical person, here's what I'd put in the program. I would expect it to take about 10-15 undergraduate credits in a good college to adequately cover these topics. We would not cover all of them in depth, just an overview sufficient to understand them, but we should cover one or two in depth (preferably very mathematically-based topics) to give a better flavor of how these things work.
One last thing: Many will pass these courses, few will truly gain anything from them. Professors should encourage students who think these classes are a waste of their time to leave the technical lawyer track and take up some other branch of law. Just because you've passed these classes doesn't mean you know what any of this stuff means.
Technical Curriculum for the Technical Lawyer
All credit estimations are based on undergrad credits at a major state university. They'd probably tend toward the intense side (by lawyer standards, due to technical content)... this is after all a lawyer program, not some sort of community college technician program.
Basic Computer Science (Semester)
A four-credit course on some of the basics of computer science. This is a practical course highly focused on equipping lawyers, so we'll hold the stuff that real computer scientists start with, like set theory and discrete mathematics. Instead, we'll do some basic programming in Python or similarly friendly, yet powerful language. We'll cover basic complexity theory. We'll zoom right to the end of the P=NP? debate and discuss the kind of problems that computers can not do. (Example: Brute force solution of the traveling salesman problem. Even a lawyer can be shown why the brute force solution doesn't work; they'll have to take our word for it that there is no other known efficient solution guaranteed to find the best solution.) We'll cover basic information theory, emphasizing not so much the mechanics of transmission and error correction, but how information flows and is in many ways conserved like energy, being neither created nor destroyed in many ways. We'll discuss some simplified compression techniques that the students can implement (with substantial help from the prof), with an eye on equipping the class for the encryption class.
I know that looks like a lot, but to the extent possible, we really will skip over the foundations and cover just the mentioned topics. It will probably be hard to convince the CS professor to skip as much "fundamentals" as I'm talking about here, but it can and should be done. These are going to be lawyers, not programmers.
The ulterior motive for this class is not to actually teach the students how computers work. Instead, it's to teach students how computers don't work. To impress upon our technical-lawyers-to-be that computers are not magic boxes. That just because somebody claims something is possible does not mean it is. That just because you wish for it does not mean it's possible. (Can we enroll some managers in this course too, please?)
At some point in the curriculum, we would issue the students an impossible problem, either truly impossible or one the students simply don't stand a chance of doing in time. Ideally, it should be an actual 300-level assignment from a real Computer Science program. (My first choice would be some multithreaded program from an OS class.) Hopefully the lesson will not be lost on the students.
This is also a weeding course, to see if you really should be doing technology law and not some other branch.
More Info Theory
I hesitate to call it "Advanced Information Theory for Lawyers" but I suppose that's how it would look on the syllabus.
Again, we obviously can't cover the mathematical foundations, but we can go over what it is, what the technologies do, the history of the law surrounding these technologies, and cover things they can't do. Cover encryption, hashing in the context of digital signatures, the Snake Oil FAQ. More emphasis on what computers can and can't do, by looking at current technologies and discussing what it takes to make them work at a high level.
Assuming a large enough class, it might be fun to have the students work in pairs or small teams for three or four days near the beginning of the course and ask them to come up with some encryption technique, any encryption technique that works on medium-sized snippets of text. (We do not give them much time because we do not want terribly pseudo-sophisticated technique.) Then use some prepared programs to break right in front of the class the inevitable Caesar cipher solution, and a couple of other common ones that can be automatically broken on sufficiently large text sizes. Having their own encryption broken should teach them quite a bit about the difficulty of good encryption.
The statistics of false positives should go here. Also, at some point in the class we'd pose the question "Bob has a computation that will take thirty-two years on modern hardware. Assuming Moore's Law (specifically, "the computational value available per dollar doubles every year", which isn't quite right but it's close and makes simple calculations possible) holds and he can only spend the money once, when should he start his computation?" In fact, as many other similar brain-expanding paradoxes should be presented, as brain-expansion, not education in the rote-learning sense, is really the point. Too many lawmakers have never had to deal with exponentially-growing functions.
(Answer: For simplicity, assume he's starting in 2000. If he starts in 2000, his computation finishes in 2032. If he waits until 2001, his computation takes 16 years, finishing in 2017. If he starts in 2002, his computation takes 8 years, ending in 2010. For 2003, 4 years, ending in 2007. For 2004, 2 years, ending in 2006. For 2005, 1 year, also ending in 2006. After that, it always finishes after 2006.
This is non-intuitive to most people, who would normally think that the sooner, the better.)
I think this would be 3 credits.
Networking & Culture
Practical networking, not theoretical, so, an overview of Internet technologies and telephony technologies. History of technologies. Technologies built on those technologies. Philosophy of the various technologies (i.e., differences between open and closed networks, smart and stupid networks) and the practical effects of those technologies. Sample essay question from the final exam: "Would the Internet have developed if it were based on smart networks? How would it be different? For whom would it be useful? What uses, if any, of the modern-day Internet would not be possible, either technically or economically?"
To fill in the rest of the time (I don't think this would take all semester), cover the various cultures of computer users. You can't understand the way the tech industry has played out without understanding some of the culture clashes that have taken place, such as the GNU movement, and the wacky world of UNIX.
The reason the relatively small domain of "networking" in computer science rates a whole course for lawyers is that it is networking that brings people together, and it is only when there is more then one person involved that there is any need for law. Thus, networking has a much greater impact on the law then a field like "machine learning" does.
3 credits.
History & Case law
A history of computer science and computer law from a technology standpoint, whatever history and case law the other classes don't cover. Show some patents. Show why the XOR cursor patent was stupid. (If at all possible, assist the class in reconstructing the ideas behind the patent on the spot, and highlighting the absurdity of a patent when even a class of lawyers can figure it out. This means basic computer science is a pre-req to this course.) Whatever other misc things make sense.
This is the course that is primarily responsible for tying together the brief, breezy tech education they got from the other courses and tying it back into their major. It is unavoidable that certain value judgements will be made, as in the previous paragraph where I refer to a patent as "stupid". I know universities prefer not to express opinions, but one has to be pretty, shall we say, confident in the legal system to believe that every decision the legal system has made was correct, by any standard. Of course the class should be free to disagree without penalty, as long as they support their argument. (I assume this is standard practice in higher level lawyer courses when it comes to matters of opinion like this, but I don't know.)
I see this as a four-credit course but as this is the meat of the whole thing, it could easily be two 3- or 4-credit courses. Probably ought to be considered senior-level courses as well.